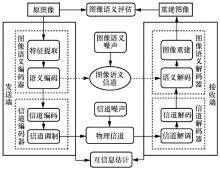
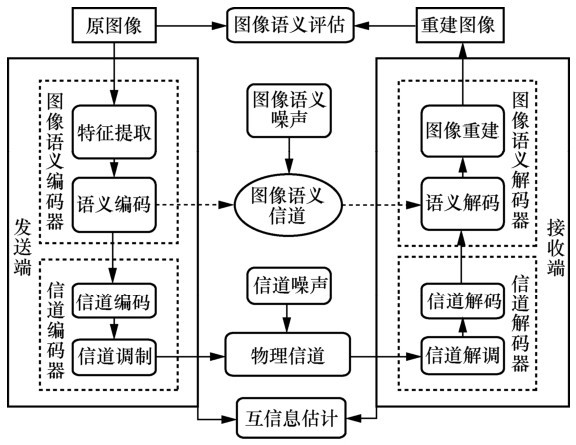
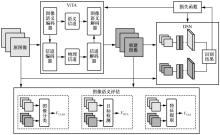
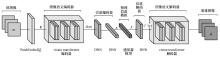
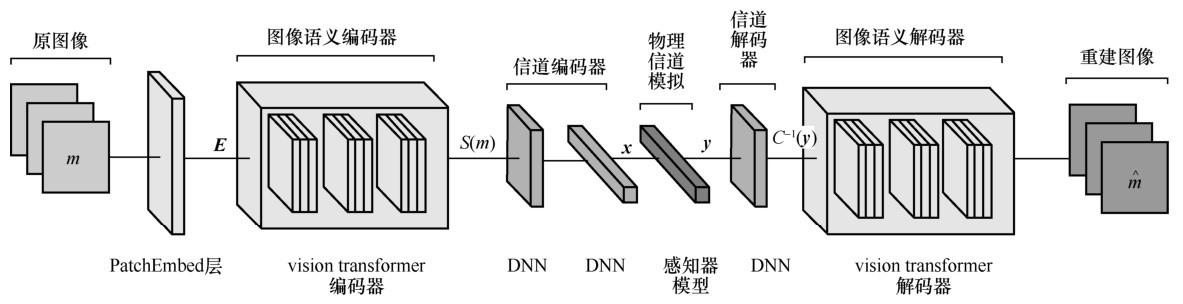
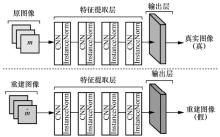
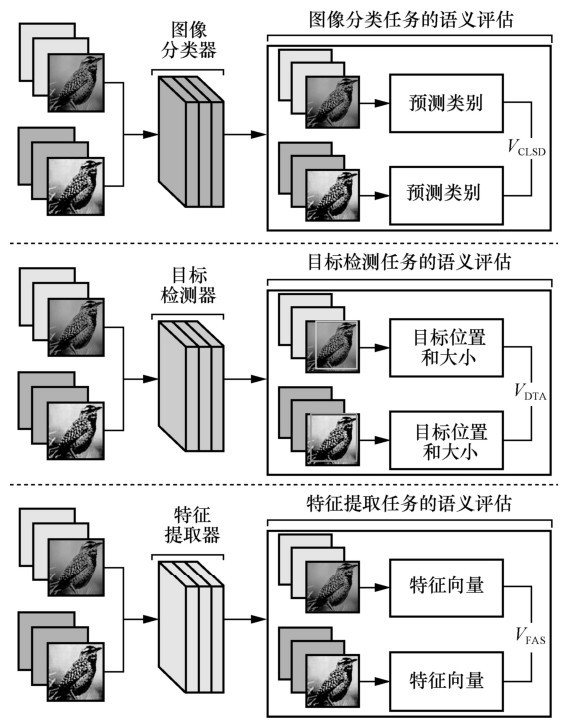
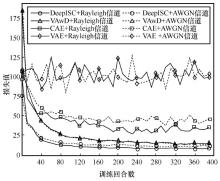
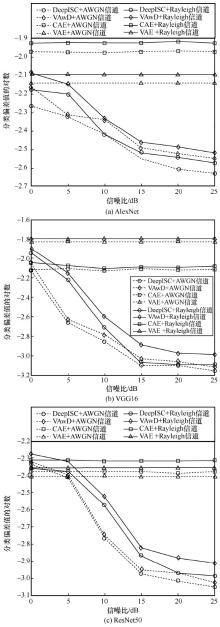
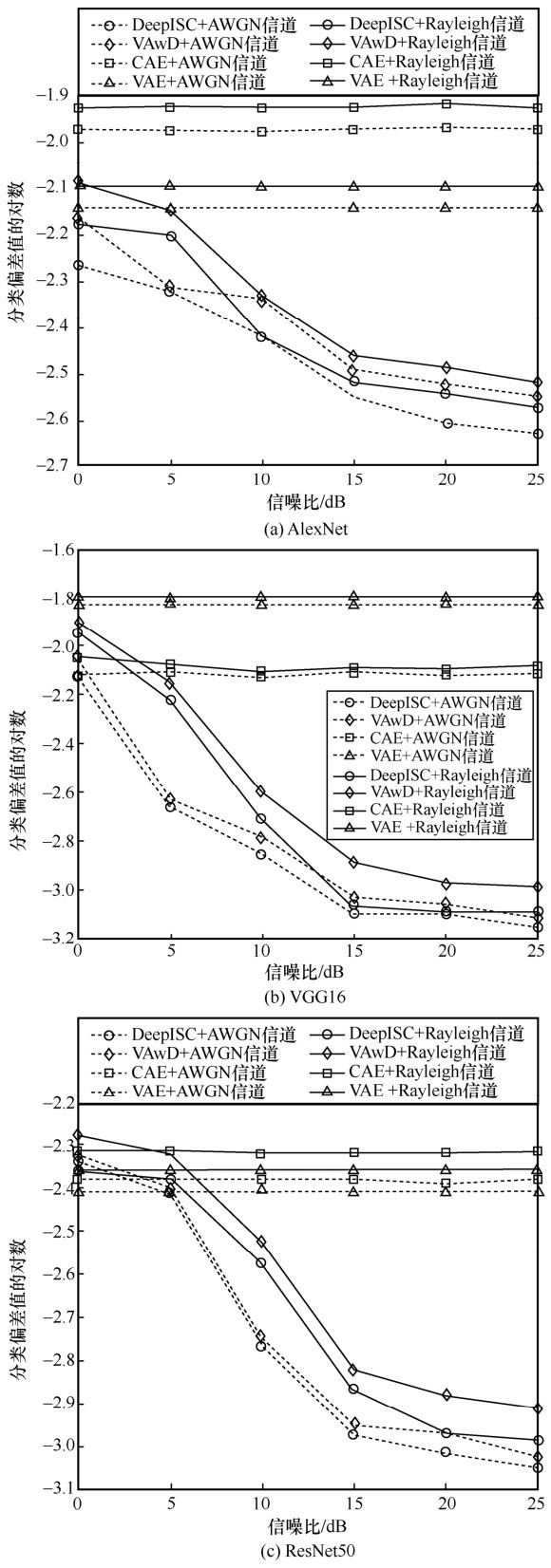
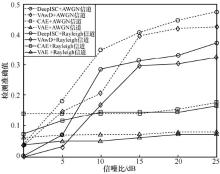
| [1] |
XIE H Q , QIN Z J , LI G Y ,et al. Deep learning enabled semantic communication systems[J]. IEEE Transactions on Signal Processing, 2021,69: 2663-2675.
|
| [2] |
TSE D , VISWANATH P . Fundamentals of wireless communication[M]. Cambridge: Cambridge University Press, 2005.
|
| [3] |
XIE H Q , QIN Z J . A lite distributed semantic communication system for Internet of things[J]. IEEE Journal on Selected Areas in Communications, 2021,39(1): 142-153.
|
| [4] |
TONG H N , YANG Z H , WANG S H ,et al. Federated learning based audio semantic communication over wireless networks[C]// Proceedings of 2021 IEEE Global Communications Conference (GLOBECOM). Piscataway:IEEE Press, 2021:doi.org/10.1109/GLOBECOM46510.2021.9685654.
|
| [5] |
KOTSAKIS R , KALLIRIS G , DIMOULAS C . Investigation of broadcast-audio semantic analysis scenarios employing radio-programme-adaptive pattern classification[J]. Speech Communication, 2012,54(6): 743-762.
|
| [6] |
HUANG D L , TAO X M , GAO F F ,et al. Deep learning-based image semantic coding for semantic communications[C]// Proceedings of 2021 IEEE Global Communications Conference (GLOBECOM). Piscataway:IEEE Press, 2021:doi.org/10.1109/GLOBECOM46510.2021:9685667.
|
| [7] |
PATWA N , AHUJA N , SOMAYAZULU S ,et al. Semantic-preserving image compression[C]// Proceedings of 2020 IEEE International Conference on Image Processing (ICIP). Piscataway:IEEE Press, 2020: 1281-1285.
|
| [8] |
SUN Q Z , GUO C L , YANG Y ,et al. Deep joint source-channel coding based on semantics of pixels[J]. arXiv Preprint,arXiv:220811375, 2022.
|
| [9] |
WANG J , WANG S X , DAI J C ,et al. Perceptual learned source-channel coding for high-fidelity image semantic transmission[C]// Proceedings of IEEE Global Communications Conference. Piscataway:IEEE Press, 2023: 3959-3964.
|
| [10] |
WANG Q , SHEN L Q , SHI Y . Recognition-driven compressed image generation using semantic-prior information[J]. IEEE Signal Processing Letters, 2020,27: 1150-1154.
|
| [11] |
HU Q Y , ZHANG G Y , QIN Z J ,et al. Robust semantic communications against semantic noise[C]// Proceedings of 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall). Piscataway:IEEE Press, 2022:doi.org/10.1109/VTC2022-Fall57202.2022.10012843.
|
| [12] |
LIU X Y , WU Y , LIANG W K ,et al. High resolution SAR image classification using global-local network structure based on vision transformer and CNN[J]. IEEE Geoscience and Remote Sensing Letters, 2022,19: 1-5.
|
| [13] |
ZHANG P , XU W J , GAO H ,et al. Toward wisdom-evolutionary and primitive-concise 6G:a new paradigm of semantic communication networks[J]. Engineering, 2022,8: 60-73.
|
| [14] |
PARMAR N , VASWANI A , USZKOREIT J ,et al. Image transformer[C]// Proceedings of the 35th International Conference on Machine Learning. New York:PMLR, 2018: 4055-4064.
|
| [15] |
PU Y C , GAN Z , HENAO R ,et al. Variational autoencoder for deep learning of images,labels and captions[C]// Proceedings of the 30th International Conference on Neural Information Processing Systems. New York:ACM Press, 2016: 2360-2368.
|
| [16] |
ZHANG H W , SHAO S , TAO M X ,et al. Deep learning-enabled semantic communication systems with task-unaware transmitter and dynamic data[J]. IEEE Journal on Selected Areas in Communications, 2023,41(1): 170-185.
|
| [17] |
SHANNON C E . A mathematical theory of communication[J]. The Bell System Technical Journal, 1948,27(3): 379-423.
|
| [18] |
CHEN C F R , FAN Q F , PANDA R . CrossViT:cross-attention multi-scale vision transformer for image classification[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2022: 347-356.
|
| [19] |
ZHU X Z , SU W J , LU L W ,et al. Deformable DETR:deformable transformers for end-to-end object detection[J]. arXiv Preprint,arXiv:201004159, 2020.
|
| [20] |
DOSOVITSKIY A , BEYER L , KOLESNIKOV A ,et al. An image is worth 16×16 words:transformers for image recognition at scale[J]. arXiv Preprint,arXiv:201011929, 2020.
|
| [21] |
ZHAO H S , JIA J Y , KOLTUN V . Exploring self-attention for image recognition[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2020: 10073-10082.
|
| [22] |
VASWANI A , SHAZEER N , PARMAR N ,et al. Attention is all You need[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York:ACM Press, 2017: 6000-6010.
|
| [23] |
KOHL S , BONEKAMP D , SCHLEMMER H P ,et al. Adversarial networks for the detection of aggressive prostate cancer[J]. arXiv Preprint,arXiv:170208014, 2017.
|
| [24] |
ISOLA P , ZHU J Y , ZHOU T H ,et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2017: 5967-5976.
|
| [25] |
YU J H , JIANG Y N , WANG Z Y ,et al. UnitBox:an advanced object detection network[C]// Proceedings of the 24th ACM International Conference on Multimedia. New York:ACM Press, 2016: 516-520.
|
| [26] |
WU W B , PAN Y . Adaptive modular convolutional neural network for image recognition[J]. Sensors, 2022,22(15): 5488.
|
| [27] |
THECKEDATH D , SEDAMKAR R R . Detecting affect states using VGG16,ResNet50 and SE-ResNet50 networks[J]. SN Computer Science, 2020,1(2): 79.
|
| [28] |
BOCHKOVSKIY A , WANG C Y , LIAO H Y M . YOLOv4:optimal speed and accuracy of object detection[J]. arXiv Preprint,arXiv:200410934, 2020.
|
| [29] |
PARIKH H , PATEL S , PATEL V . Evaluation of deep learning and transform domain feature extraction techniques for land cover classification:balancing through augmentation[J]. Environmental Science and Pollution Research, 2023,30(6): 14464-14483.
|
| [30] |
ZHANG Z J , . Improved Adam optimizer for deep neural networks[C]// Proceedings of 2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS). Piscataway:IEEE Press, 2019: 1-2.
|