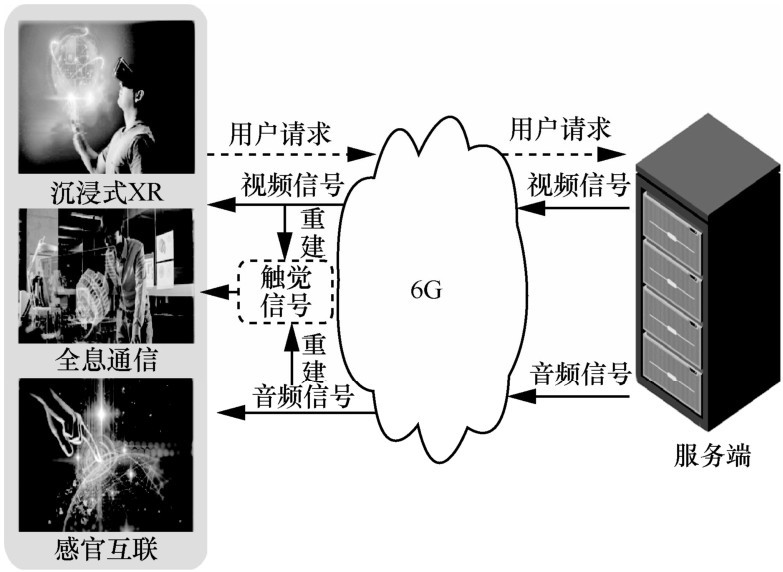
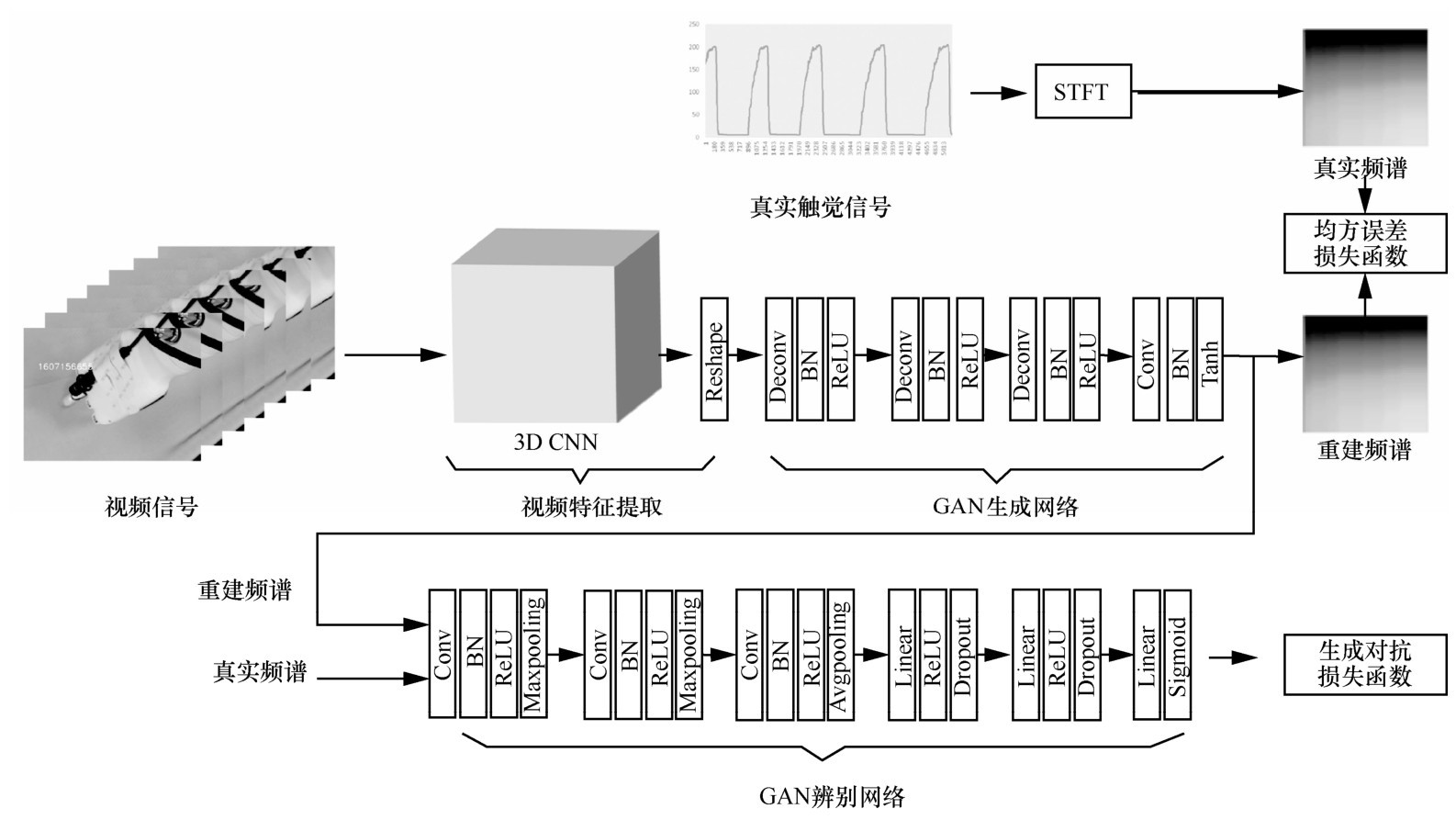
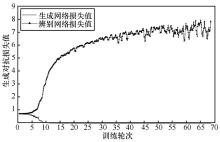
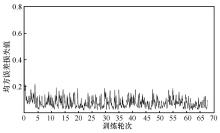
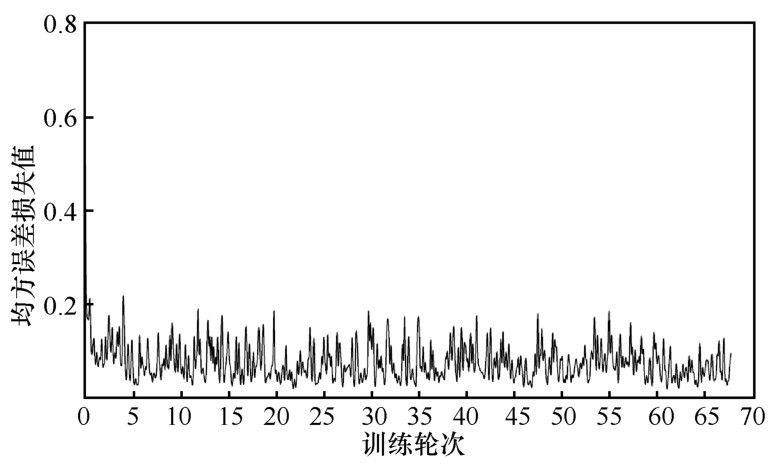
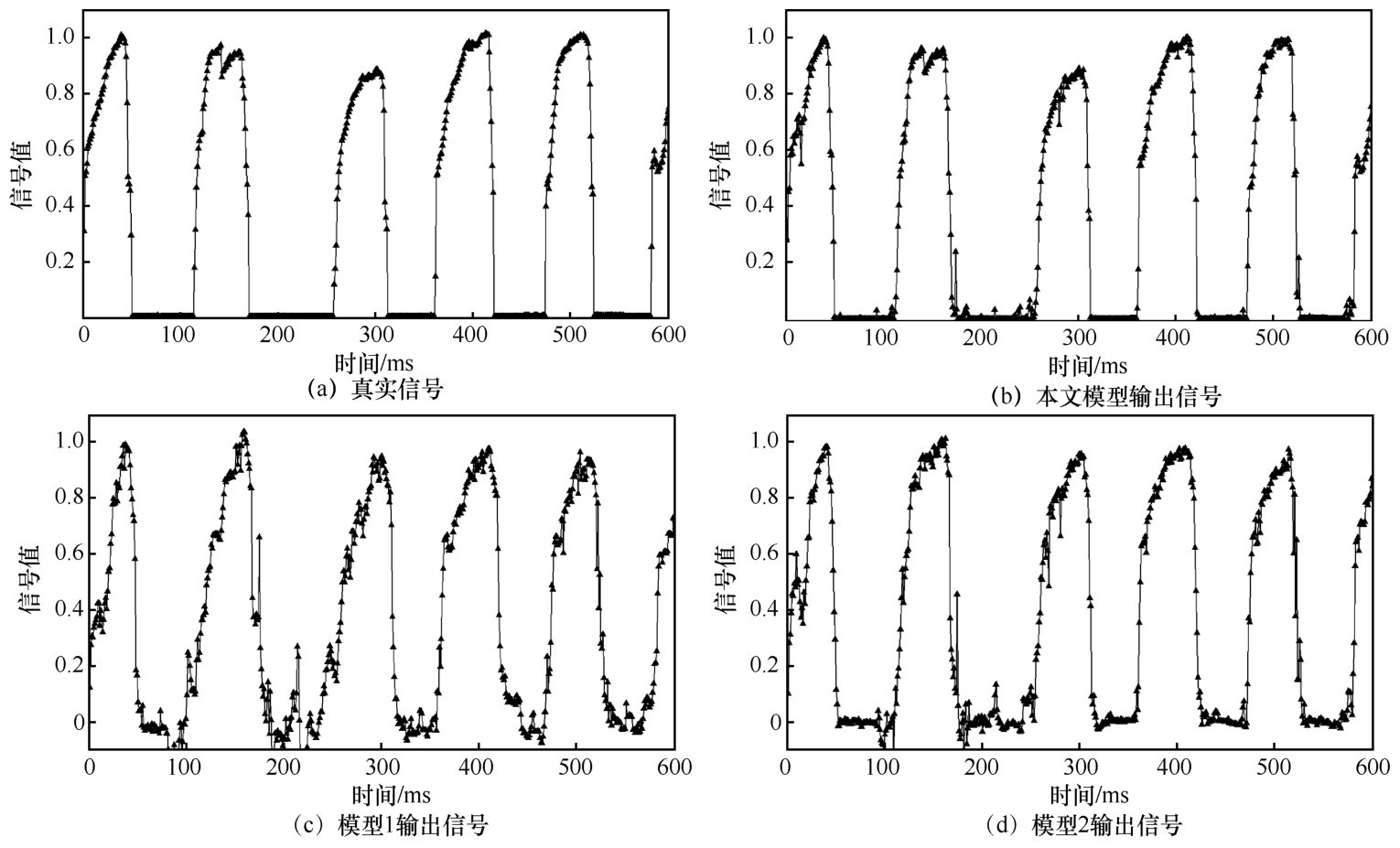
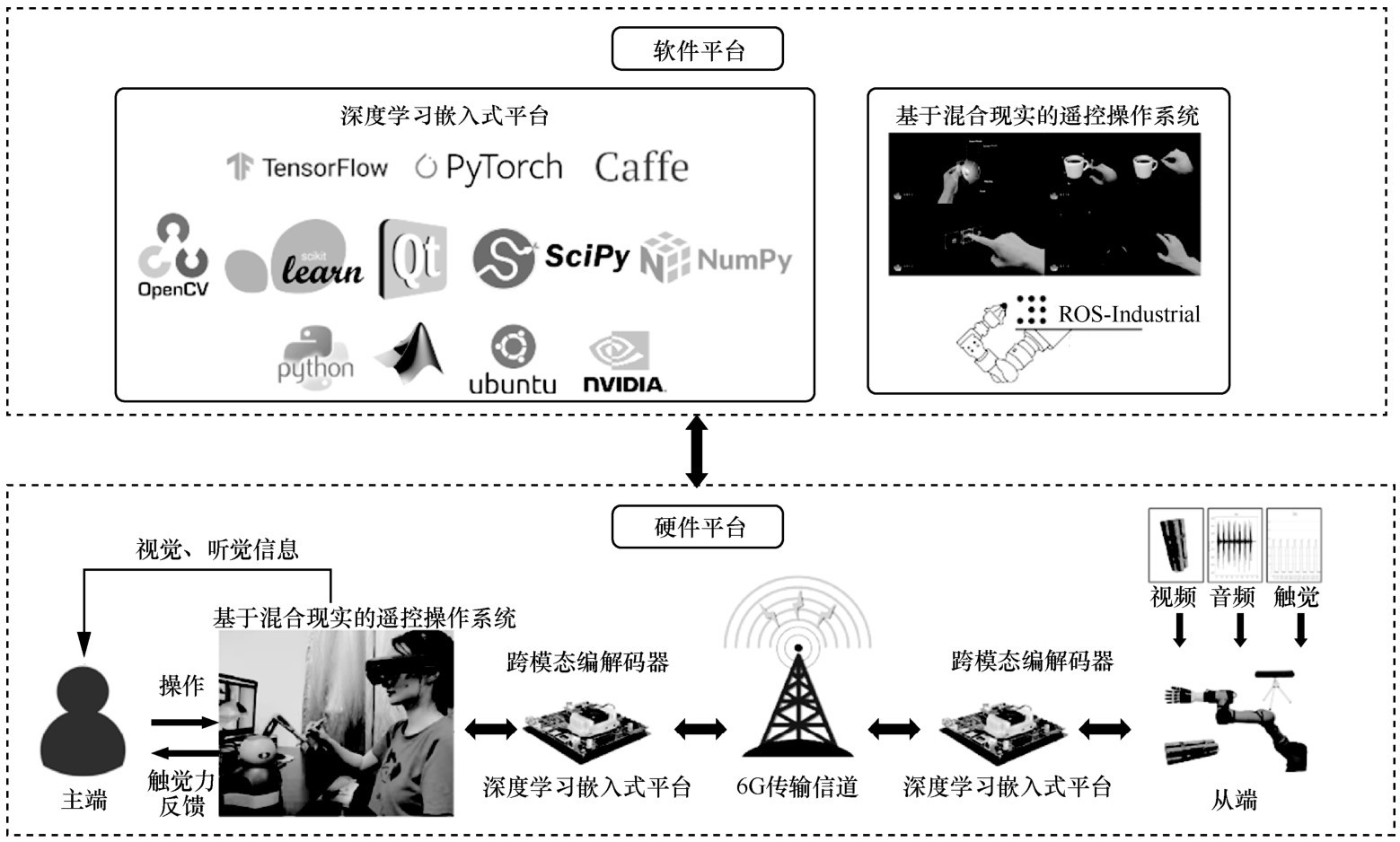
| [1] |
中国信息通信研究院. 6G 总体愿景与潜在关键技术白皮书[R]. 2021.
|
|
China Academy of Information and Communications Technology.. 6G overall vision and potential key technology white paper[R]. 2021.
|
| [2] |
VAN D B D , GLANS R , KONING D D ,et al. Challenges in haptic communications over the tactile Internet[J]. IEEE Access, 2017,5: 23502-23518.
|
| [3] |
ZHOU L , WU D , CHEN J X ,et al. Cross-modal collaborative communications[J]. IEEE Wireless Communications, 2020,27(2): 112-117.
|
| [4] |
WEI X , ZHOU L . AI-enabled cross-modal communications[J]. IEEE Wireless Communications, 2021,28(4): 182-189.
|
| [5] |
高赟, 魏昕, 周亮 . 跨模态通信理论及关键技术初探[J]. 中国传媒大学学报(自然科学版), 2021,28(1): 55-63.
|
|
GAO Y , WEI X , ZHOU L . Preliminary study on theory and key technology of cross-modal communications[J]. Journal of Communication University of China (Science and Technology), 2021,28(1): 55-63.
|
| [6] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6): 84-90.
|
| [7] |
SIMONYAN K , ZISSERMAN A . Very deep convolutional networks for large-scale image recognition[J]. arXiv Preprint,arXiv:1409.1556, 2014.
|
| [8] |
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778.
|
| [9] |
BAZZICA A , VAN GEMERT J C , LIEM C C S ,et al. Vision-based detection of acoustic timed events:a case study on clarinet note onsets[J]. arXiv Preprint,arXiv:1706.09556, 2017.
|
| [10] |
LI B C , LIU X Z , DINESH K ,et al. Creating a multitrack classical music performance dataset for multimodal music analysis:challenges,insights,and applications[J]. IEEE Transactions on Multimedia, 2019,21(2): 522-535.
|
| [11] |
ZHAO H , GAN C , ROUDITCHENKO A ,et al. The sound of pixels[C]// Proceedings of the European Conference on Computer Vision. Berlin:Springer, 2018: 570-586.
|
| [12] |
MONTESINOS J F , SLIZOVSKAIA O , HARO G . Solos:a dataset for audio-visual music analysis[C]// Proceedings of 2020 IEEE 22nd International Workshop on Multimedia Signal Processing. Piscataway:IEEE Press, 2020: 1-6.
|
| [13] |
KURMI V K , BAJAJ V , PATRO B N ,et al. Collaborative learning to generate audio-video jointly[C]// Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2021: 4180-4184.
|
| [14] |
ROTH J , CHAUDHURI S , KLEJCH O ,et al. Ava active speaker:an audio-visual dataset for active speaker detection[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 4492-4496.
|
| [15] |
TSUCHIDA S , FUKAYAMA S , HAMASAKI M ,et al. AIST dance video database:multi-genre,multi-dancer,and multi-camera database for dance information processing[C]// Proceedings of the 20th International Society for Music Information Retrieval Conference.[S.l.:s.n.], 2019: 501-510.
|
| [16] |
LI R L , YANG S , ROSS D A ,et al. AI choreographer:music conditioned 3D dance generation with AIST++[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2021: 13381-13392.
|
| [17] |
HONG S , IM W , YANG H S . Content-based video-music retrieval using soft intra-modal structure constraint[J]. arXiv Preprint,arXiv:1704.06761, 2017.
|
| [18] |
LI Y Z , ZHU J Y , TEDRAKE R ,et al. Connecting touch and vision via cross-modal prediction[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 10601-10610.
|
| [19] |
YUAN W Z , DONG S Y , ADELSON E H . GelSight:high-resolution robot tactile sensors for estimating geometry and force[J]. Sensors (Basel,Switzerland), 2017,17(12): 2762.
|
| [20] |
SUNDARAM S , KELLNHOFER P , LI Y Z ,et al. Learning the signatures of the human grasp using a scalable tactile glove[J]. Nature, 2019,569(7758): 698-702.
|
| [21] |
DUAN B , WANG W , TANG H ,et al. Cascade attention guided residue learning GAN for cross-modal translation[C]// Proceedings of 2020 25th International Conference on Pattern Recognition (ICPR). Piscataway:IEEE Press, 2021: 1336-1343.
|
| [22] |
HAO W L , ZHANG Z X , GUAN H . CMCGAN:a uniform framework for cross-modal visual-audio mutual generation[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2018: 6886-6893.
|
| [23] |
CHATTERJEE M , CHERIAN A . Sound2Sight:generating visual dynamics from sound and context[C]// European Conference on Computer Vision. Berlin:Springer, 2020: 701-719.
|
| [24] |
WEI X , SHI Y Y , ZHOU L . Haptic signal reconstruction for cross-modal communications[J]. IEEE Transactions on Multimedia, 2021:doi.org/10.1109/TMM.2021.3119860.
|
| [25] |
王万良, 李卓蓉 . 生成式对抗网络研究进展[J]. 通信学报, 2018,39(2): 135-148.
|
|
WANG W L , LI Z R . Advances in generative adversarial network[J]. Journal on Communications, 2018,39(2): 135-148.
|