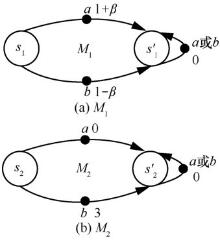
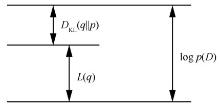
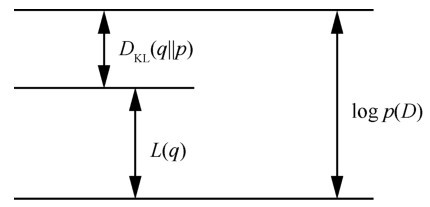
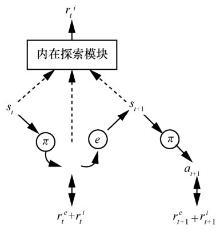
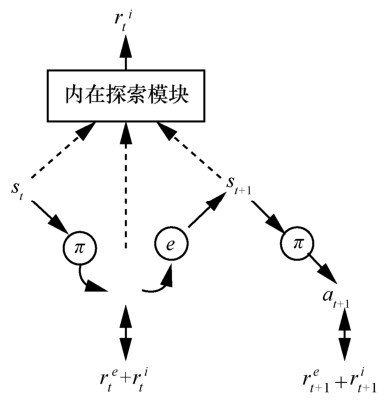
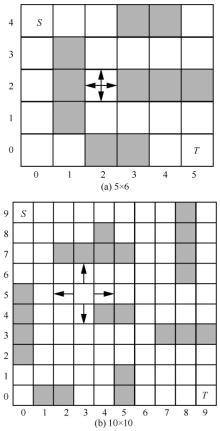
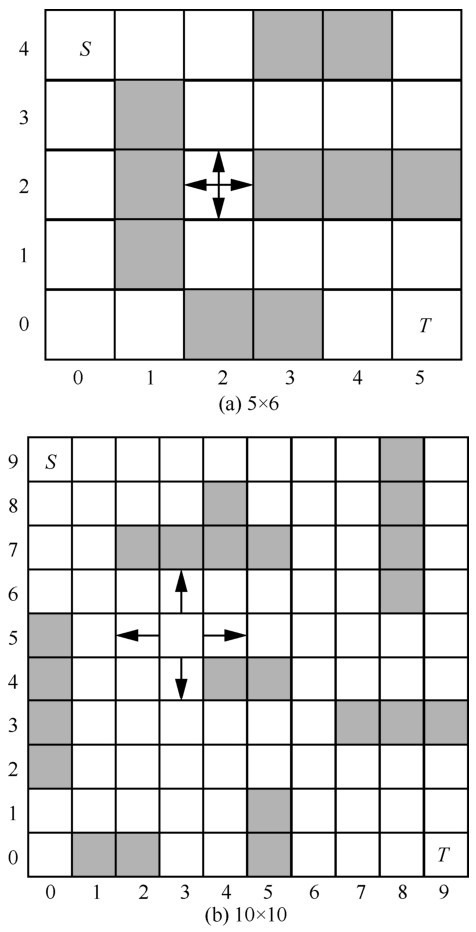
| [1] |
SUTTON R S , BARTO G A . Reinforcement learning:an introduction[M]. Cambridge: MIT PressPress, 1998.
|
| [2] |
SCHMIDHUBER J , INFORMATIK T T . On learning how to learn learning strategies[R]. Germany:Technische University, 1995.
|
| [3] |
AMMAR H B , EATON E , LUNA J M ,et al. Autonomous cross-domain knowledge transfer in lifelong policy gradient reinforcement learning[C]// The 15th International Conference on Artificial Intelligence. 2015: 3345-3351.
|
| [4] |
GUPTA A , DEVIN C , LIU Y X ,et al. Learning invariant feature spaces to transfer skills with reinforcement learning[C]// The 5th International Conference on Learning Representations. 2017: 2147-2153.
|
| [5] |
LAROCHE R , BARLIER M . Transfer reinforcement learning with shared dynamics[C]// The 31th International Conference on the Association for the Advance of Artificial Intelligence. 2017: 2147-2153.
|
| [6] |
BARRETO A , DABNEY W , MUNOS R ,et al. Successor features for transfer in reinforcement learning[C]// The 32th International Conference on Neural Information Processing Systems. 2017: 4055-4065.
|
| [7] |
DEARDEN R , NIR F , STUART R . Bayesian Q-learning[C]// The 21th International Conference on the Association for the Advance of Artificial Intelligence. 1998: 761-768.
|
| [8] |
GUEZ A , SILVER D , DAYAN P . Scalable and efficient Bayes- adaptive reinforcement learning based on Monte-Carlo tree search[J]. Journal of Artificial Intelligence Research, 2013,48(1): 841-883.
|
| [9] |
LITTLE D Y , SOMMER F T . Learning and exploration in action-perception loops[J]. Frontiers in Neural Circuits, 2013,7(7): 37-56.
|
| [10] |
MANSOUR Y , SLIVKINS A , SYRGKANIS V . Bayesian incentive-compatible bandit exploration[C]// The 16th International Conference on Economics and Computation. 2015: 565-582.
|
| [11] |
VIEN N A , LEE S G , CHUNG T C . Bayes-adaptive hierarchical MDPs[J]. Applied Intelligence, 2016,45(1): 112-126.
|
| [12] |
WU B , FENG Y . Monte-Carlo Bayesian reinforcement learning using a compact factored representation[C]// The 4th International Conference on Information Science and Control Engineering. 2017: 466-469.
|
| [13] |
傅启明, 刘全, 伏玉琛 ,等. 一种高斯过程的带参近似策略迭代算法[J]. 软件学报, 2013,24(11): 2676-2687.
|
|
FU Q M , LIU Q , FU Y C ,et al. Parametric approximation policy strategy iteration algorithm based on Gaussian process[J]. Journal of Software, 2013,24(11): 2676-2687.
|
| [14] |
GIVAN R , DEAN T , GREIG M . Equivalence notions and model minimization in Markov decision processes[J]. Artificial Intelligence, 2003,147(1): 163-223.
|
| [15] |
FERNS N , PANANGADEN P , PRECUP D . Metrics for finite Markov decision processes[C]// The 20th International Conference on Uncertainty in Artificial Intelligence. 2004: 162-169.
|
| [16] |
BEAL M J . Variational algorithms for approximate Bayesian inference[D]. London:University of London, 2003.
|
| [17] |
傅启明, 刘全, 尤树华 ,等. 一种新的基于值函数迁移的快速Sarsa算法[J]. 电子学报, 2014,42(11): 2157-2161.
|
|
FU Q M , LIU Q , YOU S H ,et al. A novel fast sarsa algorithm based on value function transfer[J]. Acta Electronica Sinica, 2014,42(11): 2157-2161.
|
| [18] |
MIERING M , HASSELT H V . The QV family compared to other reinforcement learning algorithms[C]// The 17th International Conference on Approximate Dynamic Programming and Reinforcement Learning. 2008: 101-108.
|
| [19] |
CHUNG J J , LAWRANCE N R J , SUKKARIEH S . Gaussian processes for informative exploration in reinforcement learning[C]// The 20th International Conference on Robotics and Automation. 2013: 2633-2639.
|

 )
)