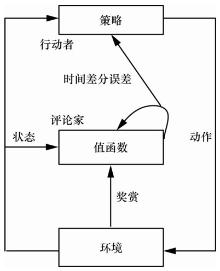
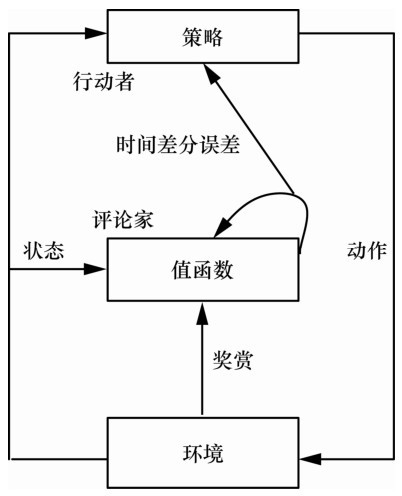
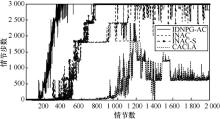
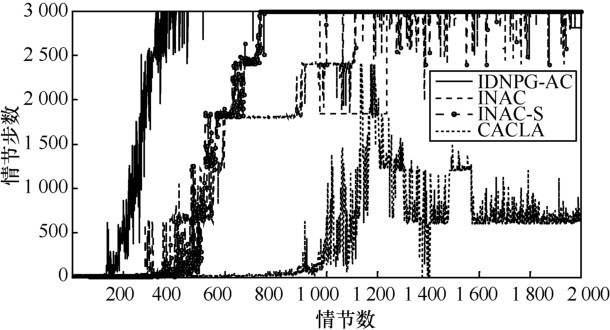
| [1] |
SUTTON R S , BARTO A G . Reinforcement learning:an introduction[M]. Cambridge Massachusetts: MIT pressPress, 1998.
|
| [2] |
BUSONIU L , BABUSKA R , SCHUTTER B D ,et al. Reinforcement learning and dynamic programming using function approximators[M]. Florida: CRC PressPress, 2010.
|
| [3] |
LEE D , SEO H , JUNG M W . Neural basis of reinforcement learning and decision making[J]. Annual Review of Neuroscience, 2012,35(5): 287-308.
|
| [4] |
WIERING M , VAN O M . Reinforcement learning:STATE-OFTHE-Art[M]. Berlin Heidelberg:Springer. 2014.
|
| [5] |
SUTTON R S , MCALLESTER D A , SINGH S P ,et al. Policy gradient methods for reinforcement learning with function approximation[C]// NIPS. 1999,99: 1057-1063.
|
| [6] |
PETERS J , SCHAAL S . NATURAL A C[J]. Neurocomputing, 2008,71(7-9): 1180-1190.
|
| [7] |
PETERS J , VIJAYAKUMAR S , SCHAAL S . Reinforcement learning for humanoid robotics[J]. Autonomous Robot, 2003,12(1): 1-20.
|
| [8] |
VAN H H . Reinforcement learning in continuous state and action spaces[M]. Reinforcement Learning. Springer Berlin Heidelberg, 2012: 207-251.
|
| [9] |
WIERSTRA D , SCHAUL T , PETERS J ,et al. Natural evolution strategies[C]// 2008 IEEE Congress on Evolutionary Computation (IEEE World Congress on Computational Intelligence). 2008: 3381-3387.
|
| [10] |
SUN Y , WIERSTRA D , SCHAUL T ,et al. Efficient natural evolution strategies[C]// The 11th Annual Conference on Genetic and Evolutionary Computation. 2009: 539-546.
|
| [11] |
RUBINSTEIN R Y , KROESE D P . The cross-entropy method[J]. Information Science & Statistics, 2008,50(1): 92-92.
|
| [12] |
BOTEV Z I , KROESE D P , RUBINSTEIN R Y ,et al. The cross-entropy method for optimization[J]. Machine Learning:Theory and Applications,Chennai:Elsevier BV, 2013,31: 35-59.
|
| [13] |
MARTIN H J A , DE LOPE J . x<α>:an effective algorithm for continuous actions reinforcement learning problems[C]// The IEEE Industrial Electronics Society. 2009: 2063-2068.
|
| [14] |
LILLICRAP T P , HUNT J J , PRITZEL A ,et al. Continuous control with deep reinforcement learning[J]. Computer Science, 2015,8(6): A187.
|
| [15] |
GU S , LILLICRAP T , SUTSKEVER I ,et al. Continuous deep Q-learning with model-based acceleration[J]. arXiv Preprint arXiv:1603.00748, 2016.
|
| [16] |
KHAMASSI M , TZAFESTAS C . Active exploration in parameterized reinforcement learning[J]. arXiv preprint arXiv:1610, 2016.
|
| [17] |
BHATNAGAR S , GHAVAMZADEH M , LEE M ,et al. Incremental natural actor-critic algorithms[C]// Advances in neural information processing systems. 2007: 105-112.
|
| [18] |
VIJAY R , KONDA , JOHN N. . Tsitsiklis.actor-critic algorithms[J]. Siam Journal on Control & Optimization, 2001,42(4): 1008-1014.
|
| [19] |
BERENJI H R , KHEDKAR P . Learning and tuning fuzzy logic controllers through reinforcements[J]. IEEE Transactions on Neural Networks, 1992,3(5): 724-740.
|
| [20] |
SINGH S P , SUTTON R S . Reinforcement learning with replacing eligibility traces[J]. Machine Learning, 1996,22(1-3): 123-158.
|
| [21] |
SUTTON R S . Generalization in reinforcement learning:successful examples using sparse coarse coding[J]. Neural Information Processing Systems, 1996: 1038-1044.
|