

Journal on Communications ›› 2013, Vol. 34 ›› Issue (11): 129-139.doi: 10.3969/j.issn.1000-436x.2013.11.015
• academic paper • Previous Articles Next Articles
Jun YU1,Quan LIU1,2,Qi-ming FU1,Hong-kun SUN1,Gui-xing CHEN1
Online:2013-11-25
Published:2017-06-23
Supported by:Jun YU,Quan LIU,Qi-ming FU,Hong-kun SUN,Gui-xing CHEN. Bayesian Q learning method with Dyna architecture and prioritized sweeping[J]. Journal on Communications, 2013, 34(11): 129-139.
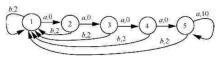
"

"
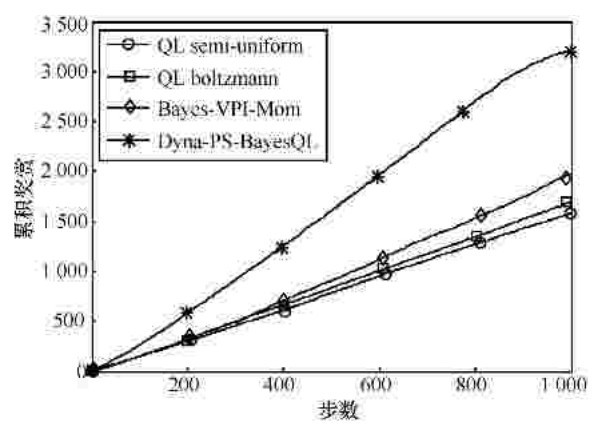
"
链问题 | 步数 | ||
500 | 1 000 | ||
QL semi-uniform | 783 | 1582 | |
QL Boltzmann | 829.8 | 1 692.8 | |
Bayes-VPI-Mom | 905.8 | 1 973.5 | |
Dyna-PS-BayesQL | 1 603.5 | 3 209.7 |
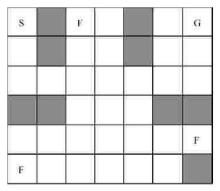
"

"
迷宫导航问题 | 步数 | ||
10 000 | 20 000 | ||
QL semi-uniform | 72 | 549 | |
QL Boltzmann | 56 | 148 | |
Bayes-VPI-Mom | 69 | 160 | |
Dyna-PS-BayesQL | 334 | 1 246 |

"
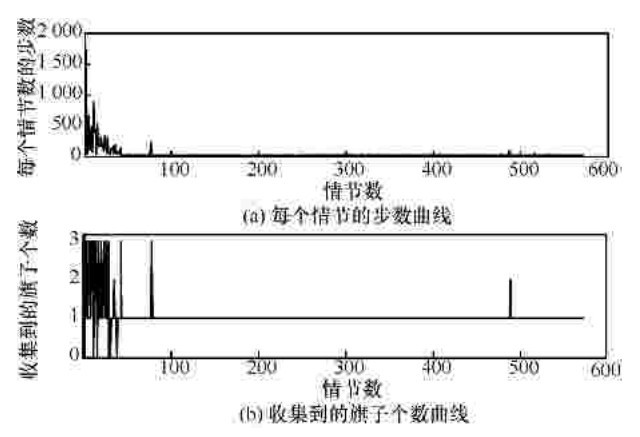
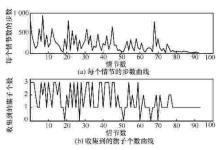
"
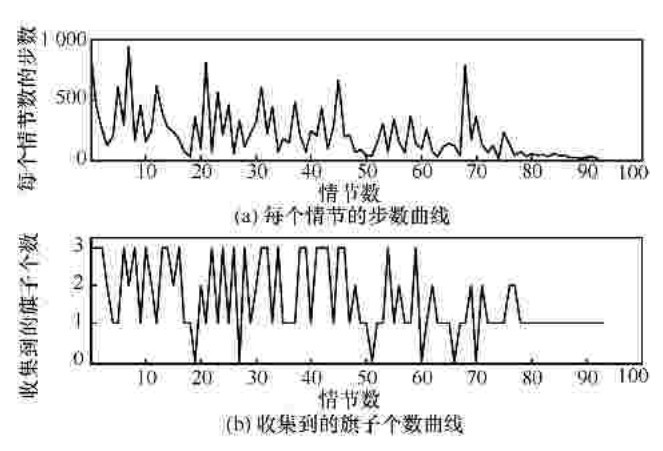
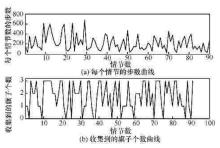
"
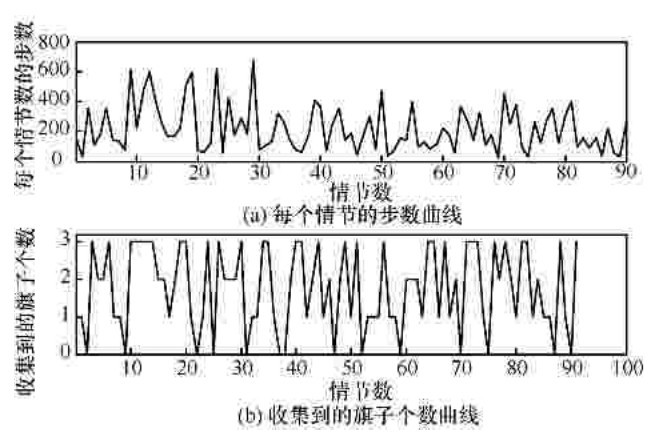
"
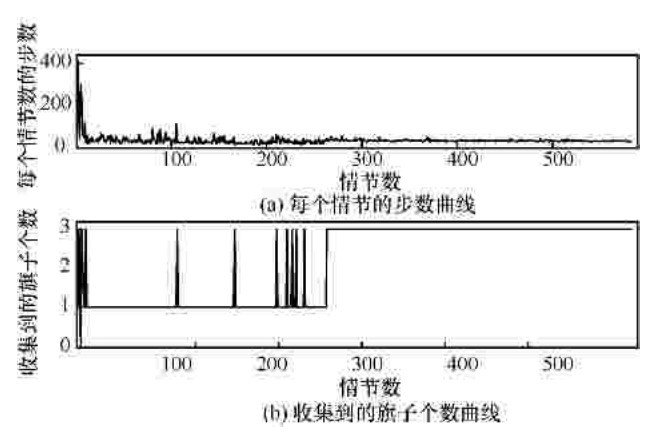
"

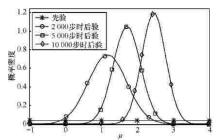
"
参数 | 平均次数 |
(1,2,2,20) | 50.5 |
(1,2,2,50) | 55.9 |
(1,2,2,200) | 69.1 |
| [1] | SUTTON R S , BARTO A G . Reinforcement Learning: An Introduc-tion[M]. Cambridge: MIT Press 1998. |
| [2] | 徐昕 . 增强学习与近似动态规划[M]. 北京: 科学出版社, 2010. XU X . Reinforcement Learning and Approximate Dynamic Program-ming[M]. Beijing: Science Press, 2010. |
| [3] | 刘全, 傅启明, 龚声蓉 等. 最小状态变元平均奖赏的强化学习方法[J]. 通信学报, 2011,32 (1): 66-71. LIU Q , FU Q M , GONG S R , et al. Reinforcement learning algorithm based on minimum state method and average reward[J]. Journal on Communications, 2011,32 (1): 66-71. |
| [4] | 肖飞, 刘全, 傅启明 等. 基于自适应势函数塑造奖赏机制的梯度下降Sarsa (?) 算法[J]. 通信学报, 2013,34 (1): 77-88. XIAO F , LIU Q , FU Q M , et al. Gradient descent Sarsa(?)algorithm based on the adaptive potential function shaping reward mechanism[J]. Journal on Communications, 2013,34 (1): 77-88. |
| [5] | SZEPESVáRI C . Algorithms for Reinforcement Learning[M]. San Rafael: Morgan Claypool 2010. |
| [6] | WATKINS C . Learning From Delayed Rewards[D]. Cambridge: Kings's College, University of Cambridge 1989. |
| [7] | SUTTON R S . Dyna, an integrated architecture for learning, planning, and reacting[J]. SIGART Bulletin, 1991,2: 160-163. |
| [8] | SUTTON R S , SZEPESVáRI C , GERAMIFARD A , et al. Dyna-style planning with linear function approximation and prioritized sweep-ing[A]. Proceedings of the 24th Conference on Uncertai y in Artifi-cial Intelligence[C]. Finland: AUAI, 2008. |
| [9] | WINGATE D , SEPPI K D . Prioritized methods for accelerating MDP solvers[J]. Journal of Machine Learning Research, 2005,6: 851-881. |
| [10] | MEULEAU N , BOURGINE P . Exploration of multi-state environ-ments: local measures and back-propagation of uncertainty[J]. Ma-chine Learning, 1999,35 (2): 117-154. |
| [11] | COGGAN M . Exploration and exploitation in reinforcement learn-ing[A]. Proceedings of the 4th International Conference on Computa-tional Intelligence and Multimedia Applications[C]. Japan, 2001. |
| [12] | ALEXANDER L , STREHL , MICHAEL L . A theoretical analysis of mod-el-based interval estimation[A]. Proceedings of the 22nd International Conference on Machine Learning[C]. New York: ACM, 2005. |
| [13] | MEULEAU N , BOURGINE P . Exploration of multi-state environ-ments: local measures and back-propagation of uncertainty[J]. Ma-chine Learning, 1999,35 (2): 117-154. |
| [14] | DEARDEN R , FRIEDMAN N , RUSSELL S . Bayesian Q learning[A]. Proceedings of 15th International Conference on Artifi ial Intelli-gence[C]. Menlo Park: AAAI Press, 1998. |
| [15] | DEARDEN R , FRIEDMAN N , ANDRE D . Model based Bayesian exploration[A]. Proceedings of 15th Conference on Uncertainty in Ar-tificial Intelligence[C]. San Francisco: Morgan Kaufmann, 1999. |
| [16] | ASMUTH J , MICHAEL L , et al Potential-based shaping in mod-el-based reinforcement learning[A]. Proceedings of the 23th AAAI Conference on Artificial Intelligence[C]. Chicago: AAAI Press, 2008. |
| [17] | PENG J , WILLIAMS R J . Efficient learning and planning within the dyna framework[J]. Adaptive Behavior, 1993,2: 437-454. |
| [18] | DEGROOT M , SCHERVISH M . Probability and Statistics[M]. New York: Person Edition 2010. |
| [19] | TEACY W , CHALKIADAKIS G , FARINELLI A . Decentralised Bayesian reinforcement learning for online agent collaboration[A]. Proceedings of 11th International Joint Conference on tonomous Agents and Multi-Agent Systems[C]. Spain: IFAAMAS, 2012. |
| [1] | Ling MA, Qiliang FAN, Ting XU, Guanchen GUO, Shenglin ZHANG, Yongqian SUN, Yuzhi ZHANG. Scheduling framework based on reinforcement learning in online-offline colocated cloud environment [J]. Journal on Communications, 2023, 44(6): 90-102. |
| [2] | Biao JIN, Yikang LI, Zhiqiang YAO, Yulin CHEN, Jinbo XIONG. GenFedRL: a general federated reinforcement learning framework for deep reinforcement learning agents [J]. Journal on Communications, 2023, 44(6): 183-197. |
| [3] | Yuancheng LI, Yongtai QIN. Deep reinforcement learning based algorithm for real-time QoS optimization of software-defined security middle platform [J]. Journal on Communications, 2023, 44(5): 181-192. |
| [4] | Dacheng ZHOU, Hongchang CHEN, Weizhen HE, Guozhen CHENG, Hongchao HU. Research on multidimensional dynamic defense strategy for microservice based on deep reinforcement learning [J]. Journal on Communications, 2023, 44(4): 50-63. |
| [5] | Guoliang XU, Feng TAN, Yongyi RAN, Feng CHEN. Joint beam hopping and coverage control optimization algorithm for multibeam satellite system [J]. Journal on Communications, 2023, 44(4): 78-86. |
| [6] | Wenjun XU, Silei WU, Fengyu WANG, Lan LIN, Guojun LI, Zhi ZHANG. Large-scale post-disaster user distributed coverage optimization based on multi-agent reinforcement learning [J]. Journal on Communications, 2022, 43(8): 1-16. |
| [7] | Zongxuan SHA, Ru HUO, Chuang SUN, Shuo WANG, Tao HUANG. Forwarding efficiency aware traffic scheduling algorithm based on deep reinforcement learning [J]. Journal on Communications, 2022, 43(8): 30-40. |
| [8] | Shuai MA, Bing LI, Haihong SHENG, Rongyan GU, Hui ZHOU, Hongmei WANG, Yue WANG, Shiyin LI. Research on power allocation of integrated VLPC based on deep reinforcement learning [J]. Journal on Communications, 2022, 43(8): 121-130. |
| [9] | Yu ZHANG, Min CHENG. Joint optimization of edge computing and caching in NDN [J]. Journal on Communications, 2022, 43(8): 164-175. |
| [10] | Peiliang ZUO, Shaolong HOU, Chao GUO, Hua JIANG, Wenbo WANG. Security decision method for the edge of multi-layer satellite network based on reinforcement learning [J]. Journal on Communications, 2022, 43(6): 189-199. |
| [11] | Xianchao ZHANG, Yao ZHAO, Haijun YE, Rui FAN. Intelligent transmit power control algorithm for the multi-user interference of wireless network [J]. Journal on Communications, 2022, 43(2): 15-21. |
| [12] | Chuanhuang LI, Yangting CHEN, Jingjing TANG, Jiali LOU, Renhua XIE, Chuntao FANG, Weiming WANG, Chao CHEN. QL-STCT: an intelligent routing convergence method for SDN link failure [J]. Journal on Communications, 2022, 43(2): 131-142. |
| [13] | Jinyin CHEN, Shulong HU, Changyou XING, Guomin ZHANG. Deception defense method against intelligent penetration attack [J]. Journal on Communications, 2022, 43(10): 106-120. |
| [14] | Xin SU, Leilei MENG, Yiqing ZHOU, Wu CELIMUGE. Maritime mobile edge computing offloading method based on deep reinforcement learning [J]. Journal on Communications, 2022, 43(10): 133-145. |
| [15] | Li’na DU, Li ZHUO, Shuo YANG, Jiafeng LI, Jing ZHANG. Survey on reinforcement learning based adaptive bit rate algorithm for mobile video streaming services [J]. Journal on Communications, 2021, 42(9): 205-217. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||