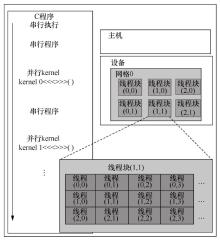
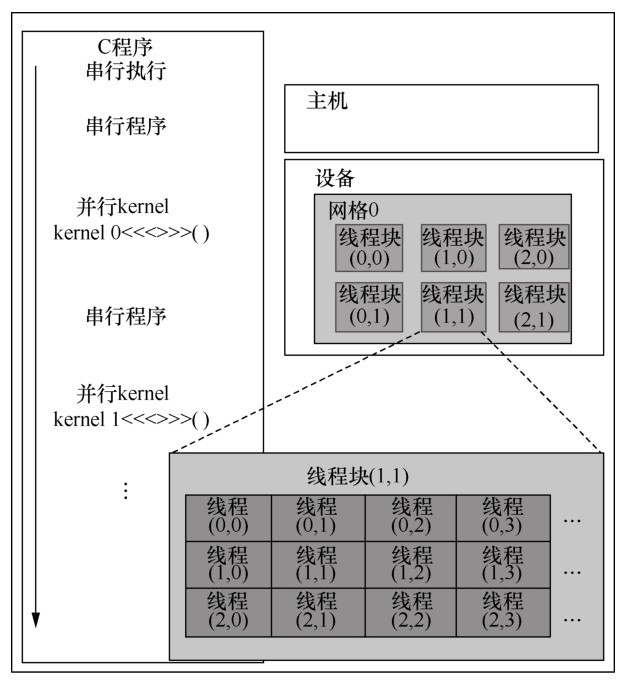
| [1] |
DENNIS J B . A preliminary architecture for a basic dataflow processor[J]. ACM SIGARCH Computer Architecture News, 1974,3(4): 126-132.
|
| [2] |
NIKHIL R S . Executing a program on the MIT tagged-token dataflow architecture[J]. IEEE Transactions on Computers, 1990,39(3): 300-318.
|
| [3] |
KHAILANY B , DALLY W J , KAPASI U J ,et al. Imagine:media processing with streams[J]. IEEE Micro, 2001,21(2): 35-46.
|
| [4] |
TAYLOR M , PSOTA J , SARAF A ,et al. Evaluation of the raw microprocessor:an exposed-wire-delay architecture for ILP and streams[J]. International Symposium on Computer Architecture, 2004,32(2): 2-13.
|
| [5] |
KOZYRAKIS C , PERISSAKIS S , PATTERSON D ,et al. Scalable processors in the billion-transistor era:IRAM[J]. IEEE Computer, 1997,30(9): 75-78.
|
| [6] |
SANKARALINGAM K , NAGARAJAN R , LIU H ,et al. Exploiting ILP,TLP,and DLP with the polymorphous TRIPS architecture[J]. International Symposium on Computer Architecture, 2003,31(2): 422-433.
|
| [7] |
YANG Q M , WU N , HE Y ,et al. Implementation of the MASA-I stream processor on FPGA[J]. Computer Engineering and Science, 2008,30(3): 114-118.
|
| [8] |
D ALLY W J , LABONTE F , DAS A ,et al. Merrimac:supercomputing with streams[C]// The 2003 ACM/IEEE Conference on Supercomputing. Piscataway:IEEE Press, 2003:35.
|
| [9] |
NVIDIA. Compute unified device architecture programming guide[Z]. 2007.
|
| [10] |
DEAN J , GHEMAWAT S . MapReduce:simplified data processing on large clusters[J]. Communications of The ACM, 2008,51(1): 107-113.
|
| [11] |
ZAHARIA M , CHOWDHURY M , DAS T ,et al. Resilient distributed datasets:a fault-tolerant abstraction for in-memory cluster computing[C]// The 9th USENIX Conference on Networked Systems Design and Implementation. Berkeley:USENIX Association, 2012:2.
|
| [12] |
ABADI D J , CARNEY D , ?ETINTEMEL U ,et al. Aurora:a new model and architecture for data stream management[J]. The International Journal on Very Large Data Bases, 2003(12): 120-139.
|
| [13] |
ABADI D J , AHMAD Y , BALAZINSKA M ,et al. The design of the borealis stream processing engine[C]// The 2nd Biennial Conference on Innovative Data Systems Research(CIDR 2005). New York:ACM Press, 2005: 277-289.
|
| [14] |
THIES W , KARCZMAREK M , AMARASINGHE S ,et al. StreamIt:a language for streaming applications[C]// The 11th International Conference on Compiler Construction. New York:ACM Press, 2002: 179-196.
|
| [15] |
GEDIK B , ANDRADE H , WU K ,et al. SPADE:the system s declarative stream processing engine[C]// International Conference on Management of Data.[S.l.:s.n]. 2008: 1123-1134.
|
| [16] |
ANDERSON Q . Storm real-time processing cookbook[M]. Birmingham: Packt Publishing LtdPress, 2013.
|
| [17] |
ZAHARIA M , DAS T , LI H ,et al. Discretized streams:an efficient and fault-tolerant model for stream processing on large clusters[C]// The 4th USENIX Workshop on Hot Topics in Cloud Computing. Berkeley:USENIX Association, 2012:10.
|
| [18] |
KULKARNi S , BHAGAT N , FU M ,et al. Twitter Heron:stream processing at scale[C]// International Conference on Management of Data. New York:ACM Press, 2015: 239-250.
|
| [19] |
CARBONE P , KATSIFODIMOS A , EWEN S ,et al. Apache Flink:stream and batch processing in a single engine[J]. IEEE Database Engineering Bulletin, 2015,36(4): 28-33.
|
| [20] |
BUDDHIKA T , PALLICKARA S . NEPTUNE:real time stream processing for Internet of things and sensing environments[C]// 2016 IEEE International Parallel and Distributed Processing Symposium(IPDPS). Piscataway:IEEE Press, 2016: 1143-1152.
|
| [21] |
AKIDAU T , BALIKOV A , BEKIROGLU K ,et al. MillWheel:fault-tolerant stream processing at internet scale[J]. The International Journal on Very Large Data Bases, 2013,6(11): 1033-1044.
|
| [22] |
NEUMEYER L , ROBBINS B , NAIR A ,et al. S4:distributed stream computing platform[C]// International Conference on Data Mining. Piscataway:IEEE Press, 2010: 170-177.
|
| [23] |
VAVILAPALLI V K , MURTHY A C , DOUGLAS C ,et al. Apache Hadoop YARN:yet another resource negotiator[C]// The 4th Annual Symposium on Cloud Computing. New York:ACM Press, 2013.
|
| [24] |
HE B S , FANG W B , LUO Q ,et al. Mars:a MapReduce framework on graphics processors[C]// 2008 International Conference on Parallel Architectures and Compilation Techniques(PACT). Piscataway:IEEE Press, 2008: 260-269.
|
| [25] |
HONG C T , CHEN D H , CHEN W G ,et al. MapCG:writing parallel program portable between CPU and GPU[C]// 2010 19th International Conference on Parallel Architectures and Compilation Techniques (PACT). Piscataway:IEEE Press, 2010: 217-226.
|
| [26] |
CATANZARO B , SUNDARAM N , KEUTZER K . A MapReduce framework for programming graphics processors[C]// The Third Workshop on Software Tools for MultiCore Systems. New York:ACM Press, 2008.
|
| [27] |
JI F , MA X S . Using shared memory to accelerate MapReduce on graphicsunits[C]// 2011 IEEE International Parallel &Distributed Processing Symposium. Piscataway:IEEE Press, 2011: 805-816.
|
| [28] |
CHEN L C , AGRAWAL G . Optimizing MapReduce for GPUs with effective shared memory usage[C]// The 21st International Symposium on High-Performance Parallel and Distributed Computing. New York:ACM Press, 2012: 199-210.
|
| [29] |
STUART J A , OWENS J D . MultiGPU MapReduce on GPU clusters[C]// International Parallel and Distributed Processing Symposium. Piscataway:IEEE Press, 2011: 1068-1079.
|
| [30] |
CHEN Y , QIAO Z , JIANG H ,et al. MGMR:multi-GPU based MapReduce[C]// International Conference on Grid and Pervasive Computing. Berlin:SpringerVerlag, 2013: 433-442.
|
| [31] |
JIANG H , CHEN Y , QIAO Z ,et al. Accelerating MapReduce framework on multi-GPU systems[J]. Cluster Computing, 2014,17(2): 293-301.
|
 ),梅松竹,李荣春,窦勇
),梅松竹,李荣春,窦勇