



大数据 ›› 2023, Vol. 9 ›› Issue (6): 53-71.doi: 10.11959/j.issn.2096-0271.2022082
唐浩彬1,2, 张旭龙1, 王健宗1, 程宁1, 肖京1
出版日期:2023-11-15
发布日期:2023-11-01
作者简介:唐浩彬(1999- ),男,中国科学技术大学硕士生,平安科技(深圳)有限公司算法工程师,主要研究方向为人工智能、语音识别和语音合成等。基金资助:Haobin TANG1,2, Xulong ZHANG1, Jianzong WANG1, Ning CHENG1, Jing XIAO1
Online:2023-11-15
Published:2023-11-01
Supported by:摘要:
语音合成是语音、语言和机器学习领域的一个热门研究课题,旨在合成给定文本的可理解和自然的语音,在工业中有广泛的应用。语音合成的目标之一是合成自然的语音,而目前的语音合成在情感、韵律等方面还有很大的改进空间。对表现性语音合成进行了全面的调查,旨在更好地了解当前的研究现状和未来的趋势。对近年来基于情感及韵律的表现性语音合成进行了全面的总结、比较和分析。首先介绍了普通语音合成的传统实现方式及瓶颈;然后引入表现性语音合成并描述表现性语音合成在情感、韵律等方面为语音合成自然化带来的增益;最后对表现性语音合成进行了展望和总结。
中图分类号:
唐浩彬, 张旭龙, 王健宗, 程宁, 肖京. 表现性语音合成综述[J]. 大数据, 2023, 9(6): 53-71.
Haobin TANG, Xulong ZHANG, Jianzong WANG, Ning CHENG, Jing XIAO. A survey of expressive speech synthesis[J]. Big Data Research, 2023, 9(6): 53-71.
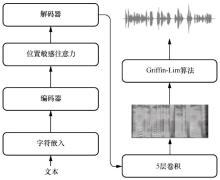
图1
自回归语音合成模型"
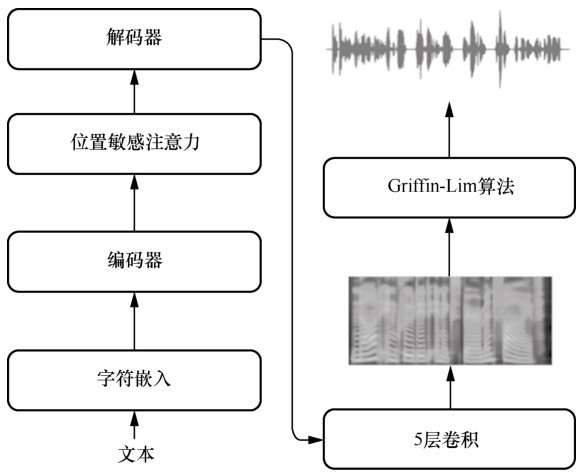
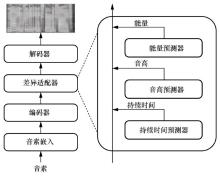
图2
非自回归语音合成FastSpeech2模型"
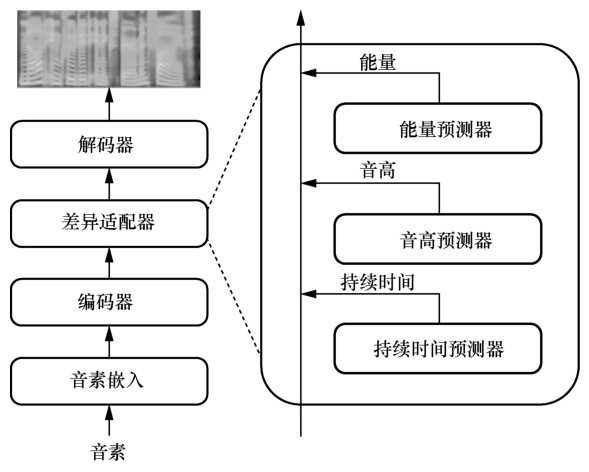

图3
神经网络语音合成模型组成"

表1
表现性语音合成信息的显式及隐式建模方法"
| 信息种类 | 描述 | 模型 |
| 显式 | 语言ID、说话人ID | SRM2TTS[ |
| 音高/持续时间/能量 | FastSpeech[ | |
| 隐式 | 参考编码器 | Skerry-Ryan R J等人[ |
| 全局风格标记(global style token,GST) | GST-Tacotron[ | |
| 变分自编码器(variational auto-encoder,VAE) | CHiVE[ | |
| 生成对抗网络(generative adversarial network,GAN) | WaveGAN[ |
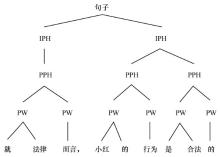
图4
韵律结构树示例"

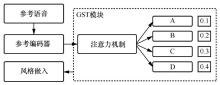
图5
GST模型"
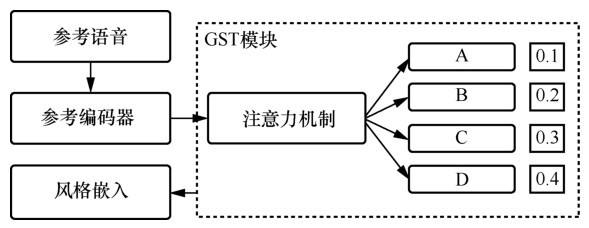
表2
参考编码器及全局风格标记建模模型对比"
| 建模方法分类 | 具体建模方法 | 描述 |
| 参考编码器 | Skerry-Ryan R J等人[ | 利用参考编码器实现对韵律信息的完整建模,缺点是不能实现韵律中信息的分离控制 |
| Gururani S等人[ | 将Skerry-Ryan R J等人整体建模的韵律嵌入分为音调和响度,分别建模,实现对音调和响度的控制 | |
| Li T等人[ | 在Skerry-Ryan R J等人的基础上引入两个情感分类器进行对抗训练,以实现从参考语音中情感迁移 | |
| 全局风格标记 | GST-Tacotron[ | 将学习到的多个有意义且可解释的全局风格标记的加权作为风格嵌入,缺点是不能了解每个风格标记代表的具体风格 |
| Kwon O等人[ | 将GST-Tacotron中的风格标记加权映射到情感空间,利用加权和表示特定情感 | |
| Um S Y等人[ | 在控制情感类别的基础上采用感知扩散方法控制每个情感的强度 | |
| Mellotron[ | 引入了基频信息,并将文本、说话人、基频、注意力映射和GST作为合成语音的条件 | |
| Liu D R等人[ | 存在在韵律迁移训练中使用相同文本的参考语音而推理时使用不同文本语音的问题,利用语音识别损失减小产生训练和推理之间的差距 | |
| Bian Y等[ | 引入多参考编码器和正交约束实现多种韵律信息的分离解耦和分别建模,缺点是不能在不相交数据集上学习风格分离 | |
| Whitehill M等人[ | 在Bian Y等人的基础上引入循环一致性损失,实现在不相交数据集上的说话人和情感迁移 |
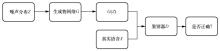
图6
GAN模型"

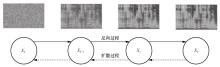
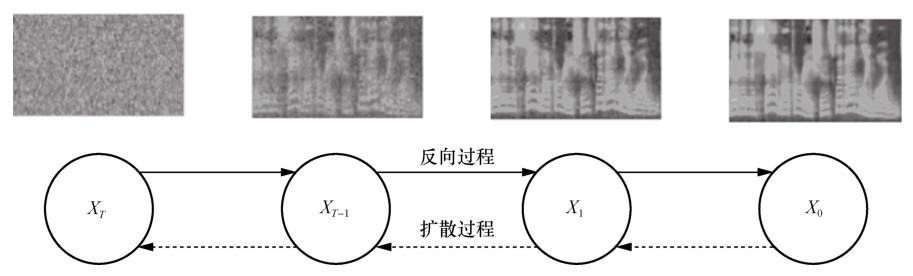
图7
扩散及反向过程"
| [1] | COKER C H . A model of articulatory dynamics and control[J]. Proceedings of the IEEE, 1976,64(4): 452-460. |
| [2] | CAPES T , COLES P , CONKIE A ,et al. Siri on-device deep learning-guided unit selection text-to-speech system[C]// Proceedings of Interspeech 2017.[S.l.:s.n.], 2017. |
| [3] | GONZALVO X , TAZARI S , CHAN C A ,et al. Recent advances in google real-time HMM-driven unit selection synthesizer[C]// Proceedings of Interspeech 2016.[S.l.:s.n.], 2016. |
| [4] | HUNT A J , BLACK A W . Unit selection in a concatenative speech synthesis system using a large speech database[C]// Proceedings of 1996 IEEE International Conference on Acoustics,Speech,and Signal Processing Conference Proceedings. Piscataway:IEEE Press, 2002: 373-376. |
| [5] | MOULINES E , CHARPENTIER F . Pitchsynchronous waveform processing techniques for text-to-speech synthesis using diphones[J]. Speech Communication, 1990,9(5/6): 453-467. |
| [6] | ZEN H , NOSE T , YAMAGISHI J ,et al. The HMM-based speech synthesis system (HTS)[J]. SSW, 2007,6: 294-299. |
| [7] | SAITO Y , TAKAMICHI S , SARUWATARI H . Statistical parametric speech synthesis incorporating generative adversarial networks[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2017,26(1): 84-96. |
| [8] | NOSE T , NOSE T , NOSE T . Efficient implementation of global variance compensation for parametric speech synthesis[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2016,24(10): 1694-1704. |
| [9] | KAWAHARA H , MORISE M , TAKAHASHI T ,et al. TandemSTRAIGHT:a temporally stable power spectral representation for periodic signals and applications to interferencefree spectrum,F0,and aperiodicity estimation[C]// Proceedings of 2008 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2008: 3933-3936. |
| [10] | CHEN L H , RAITIO T , VALENTINIBOTINHAO C ,et al. A deep generative architecture for postfiltering in statistical parametric speech synthesis[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2015,23(11): 2003-2014. |
| [11] | LADD D R . Intonational phonology[M]. Cambridge: Cambridge University Press, 1996. |
| [12] | WATSON D G , WAGNER M , GIBSON E . Experimental and theoretical advances in prosody:a special issue of language and cognitive processes[M].[S.l.:s.n.], 2012. |
| [13] | YAN Y , TAN X , LI B ,et al. AdaSpeech 3:adaptive text to speech for spontaneous style[EB]. arXiv preprint, 2021,arXiv:2107.02530. |
| [14] | HONG Y W , CHO S J , KIM J M ,et al. Formant synthesis of Haegeum sounds using Cepstral envelope[J]. The Journal of the Acoustical Society of Korea, 2009,28: 526-533. |
| [15] | KHORINPHAN C , PHANSAMDAENG S , SAIYOD S . Thai speech synthesis with emotional tone:based on Formant synthesis for Home Robot[C]// Proceedings of 2014 3rd ICT International Student Project Conference. Piscataway:IEEE Press, 2014: 111-114. |
| [16] | KLATT D H . Software for a cascade/parallel formant synthesizer[J]. The Journal of the Acoustical Society of America, 1980,67(3): 971-995. |
| [17] | VOGTEN L , BERENDSEN E . From text to speech:the MITalk system[J]. Journal of Phonetics, 1988,16(3): 371-375. |
| [18] | YOSHIMURA T , TOKUDA K , MASUKO T ,et al. Simultaneous modeling of spectrum,pitch and duration in HMMbased speech synthesis[C]// Proceedings of 6th European Conference on Speech Communication and Technology.[S.l.:s.n.], 1999. |
| [19] | FUKADA T , TOKUDA K , KOBAYASHI T ,et al. An adaptive algorithm for mel-cepstral analysis of speech[C]// Proceedings of 1992 IEEE International Conference on Acoustics,Speech,and Signal Processing. Piscataway:IEEE Press, 2002: 137-140. |
| [20] | IMAI S , SUMITA K , FURUICHI C . Mel log spectrum approximation (MLSA) filter for speech synthesis[J]. Electronics and Communications in Japan (Part I:Communications), 1983,66(2): 10-18. |
| [21] | WANG Y X , SKERRY-RYAN R J , STANTON D ,et al. Tacotron:towards end-to-end speech synthesis[C]// Proceedings of 2017 Interspeech.[S.l.:s.n.], 2017. |
| [22] | SHEN J , PANG R M , WEISS R J ,et al. Natural TTS synthesis by conditioning wavenet on MEL spectrogram predictions[C]// Proceedings of 2018 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2018: 4779-4783. |
| [23] | LI N H , LIU S J , LIU Y Q ,et al. Neural speech synthesis with transformer network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1): 6706-6713. |
| [24] | REN Y , RUAN Y J , TAN X ,et al. FastSpeech:fast,robust and controllable text to speech[EB]. arXiv preprint, 2019,arXiv:1905.09263. |
| [25] | REN Y , HU C X , TAN X ,et al. FastSpeech 2:fast and high-quality end-to-end text to speech[EB]. arXiv preprint, 2020,arXiv:2006.04558. |
| [26] | ITAKURA F . Line spectrum representation of linear predictor coefficients of speech signals[J]. The Journal of the Acoustical Society of America, 1975,57(S1): S35. |
| [27] | FUKADA T , TOKUDA K , KOBAYASHI T ,et al. An adaptive algorithm for mel-cepstral analysis of speech[C]// Proceedings of 1992 IEEE International Conference on Acoustics,Speech,and Signal Processing. Piscataway:IEEE Press, 2002: 137-140. |
| [28] | TOKUDA K , KOBAYASHI T , MASUKO T ,et al. Mel-generalized cepstral analysis - a unified approach to speech spectral estimation[C]// Proceedings of 3rd International Conference on Spoken Language Processing.[S.l.:s.n.], 1994. |
| [29] | KAWAHARA H , MASUDA-KATSUSE I , DE CHEVEIGNé A . Restructuring speech representations using a pitchadaptive time-frequency smoothing and an instantaneous-frequencybased F0 extraction:possible role of a repetitive structure in sounds[J]. Speech Communication, 1999,27(3/4): 187-207. |
| [30] | KAWAHARA H , ESTILL J , FUJIMURA O . Aperiodicity extraction and control using mixed mode excitation and group delay manipulation for a high quality speech analysis,modification and synthesis system STRAIGHT[J]. Second International Workshop on Models and Analysis of Vocal Emissions for Biomedical Applications, 2001. |
| [31] | KAWAHARA H . STRAIGHT,exploitation of the other aspect of VOCODER:perceptually isomorphic decomposition of speech sounds[J]. Acoustical Science and Technology, 2006,27(6): 349-353. |
| [32] | MORISE M , YOKOMORI F , OZAWA K . WORLD:a vocoder-based high-quality speech synthesis system for real-time applications[J]. IEICE Transactions on Information and Systems, 2016,E99.D(7): 1877-1884. |
| [33] | XIE Q C , LI T , WANG X S ,et al. Multispeaker multi-style text-to-speech synthesis with single-speaker singlestyle training data scenarios[C]// Proceedings of 2022 13th International Symposium on Chinese Spoken Language Processing (ISCSLP). Piscataway:IEEE Press, 2023: 66-70. |
| [34] | JIA Y , ZHANG Y , WEISS R J ,et al. Transfer learning from speaker verification to multispeaker text-tospeech synthesis[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. New York:ACM, 2018: 4485-4495. |
| [35] | ARIK S O , CHEN J , PENG K ,et al. Neural voice cloning with a few samples[EB]. arXiv preprint, 2018,arXiv:1802.06006. |
| [36] | ?A?CUCKI A . Fastpitch:parallel textto-speech with pitch prediction[C]// Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2021: 6588-6592. |
| [37] | SKERRY-RYAN R , BATTENBERG E , XIAO Y ,et al. Towards end-to-end prosody transfer for expressive speech synthesis with Tacotron[EB]. arXiv preprint, 2018,arXiv:1803.09047. |
| [38] | GURURANI S , GUPTA K , SHAH D ,et al. Prosody transfer in neural text to speech using global pitch and loudness features[EB]. arXiv preprint, 2019. |
| [39] | WANG Y , STANTON D , ZHANG Y ,et al. Style tokens:unsupervised style modeling,control and transfer in end-to-end speech synthesis[J]. arXiv preprint, 2018,arXiv:1803.09017. |
| [40] | VALLE R , LI J , PRENGER R ,et al. Mellotron:multispeaker expressive voice synthesis by conditioning on rhythm,pitch and global style tokens[C]// Proceedings of2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 6189-6193. |
| [41] | WAN V , CHAN C , KENTER T ,et al. CHiVE:varying prosody in speech synthesis with a linguistically driven dynamic hierarchical conditional variational network[EB]. arXiv preprint, 2019,arXiv:1905.07195. |
| [42] | HSU W N , ZHANG Y , WEISS R J ,et al. Disentangling correlated speaker and noise for speech synthesis via data augmentation and adversarial factorization[C]// Proceedings of 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 5901-5905. |
| [43] | DONAHUE C , MCAULEY J , PUCKETTE M ,et al. Adversarial audio synthesis[EB]. arXiv preprint, 2018,arXiv:1802.04208. |
| [44] | BI?KOWSKI M , DONAHUE J , DIELEMAN S ,et al. High fidelity speech synthesis with adversarial networks[EB]. arXiv preprint, 2019,arXiv:1909.11646. |
| [45] | KUMAR K , KUMAR R , DE BOISSIERE T ,et al. MelGAN:generative adversarial networks for conditional waveform synthesis[EB]. arXiv preprint, 2019,arXiv:1910.06711. |
| [46] | EYBEN F , BUCHHOLZ S , BRAUNSCHWEILER N ,et al. Unsupervised clustering of emotion and voice styles for expressive TTS[C]// Proceedings of 2012 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2012: 4009-4012. |
| [47] | ZEN H , NOSE T , YAMAGISHI J ,et al. The HMM-based speech synthesis system[J]. IEICE Technical Report Natural Language Understanding & Models of Communication, 2007. |
| [48] | ROSENBERG A . AutoBI - a tool for automatic toBI annotation[C]// Proceedings of the 2010 Interspeech.[S.l.:s.n.], 2010. |
| [49] | MORRISON M , JIN Z , SALAMON J ,et al. Controllable Neural Prosody Synthesis[C]// Proceedings of the 2020 Interspeech.[S.l.:s.n.], 2020. |
| [50] | SUN J W , YANG J , ZHANG J P ,et al. Chinese prosody structure prediction based on conditional random fields[C]// Proceedings of 2009 5th International Conference on Natural Computation. Piscataway:IEEE Press, 2009: 602-606. |
| [51] | LI T , YANG S , XUE L M ,et al. Controllable emotion transfer for endto-end speech synthesis[C]// Proceedings of 2021 12th International Symposium on Chinese Spoken Language Processing. Piscataway:IEEE Press, 2021: 1-5. |
| [52] | JOHNSON J , ALAHI A , LI F F ,et al. Perceptual losses for real-time style transfer and super-resolution[EB]. arXiv preprint, 2016,arXiv:1603.08155. |
| [53] | GATYS L , ECKER A , BETHGE M . A neural algorithm of artistic style[J]. Journal of Vision, 2016,16(12). |
| [54] | GATYS L A , ECKER A S , BETHGE M . Image style transfer using convolutional neural networks[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 2414-2423. |
| [55] | KWON O , JANG I , AHN C ,et al. An effective style token weight control technique for end-to-end emotional speech synthesis[J]. IEEE Signal Processing Letters, 2019,26(9): 1383-1387. |
| [56] | UM S Y , OH S , BYUN K ,et al. Emotional speech synthesis with rich and granularized control[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 7254-7258. |
| [57] | KWON O , SONG E , KIM J M ,et al. Effective parameter estimation methods for an ExcitNet model in generative textto-speech systems[EB]. arXiv preprint, 2019,arXiv:1905.08486. |
| [58] | LIU D R , YANG C Y , WU S L ,et al. Improving Unsupervised Style Transfer in end-to-end Speech Synthesis with end-to-end Speech Recognition[C]// Proceedings of 2018 IEEE Spoken Language Technology Workshop. Piscataway:IEEE Press, 2019: 640-647. |
| [59] | BIAN Y Y , CHEN C B , KANG Y G ,et al. Multi-reference Tacotron by intercross training for style disentangling,transfer and control in speech synthesis[EB]. arXiv preprint, 2019,arXiv:1904.02373. |
| [60] | WHITEHILL M , MA S , MCDUFF D ,et al. Multi-reference neural TTS stylization with adversarial cycle consistency[C]// Proceedings of Interspeech 2020.[S.l.:s.n.], 2020. |
| [61] | KINGMA D P , WELLING M . Autoencoding variational bayes[EB]. arXiv preprint,2014,arXiv:1312. 6114. |
| [62] | ZHANG Y J , PAN S F , HE L ,et al. Learning latent representations for style control and transfer in end-toend speech synthesis[C]// Proceedings of 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 6945-6949. |
| [63] | SUN G Z , ZHANG Y , WEISS R J ,et al. Fully-hierarchical fine-grained prosody modeling for interpretable speech synthesis[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 6264-6268. |
| [64] | GOODFELLOW I J , POUGET-ABADIE J , MIRZA M , et al . Generative adversarial nets[C]// Proceedings of the 27th International Conference on Neural Information Processing Systems. New York:ACM Press, 2014: 2672-2680. |
| [65] | ZHU J Y , PARK T , ISOLA P ,et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]// Proceedings of 2017 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2017: 2242-2251. |
| [66] | YU L T , ZHANG W N , WANG J ,et al. SeqGAN:sequence generative adversarial nets with policy gradient[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2017,31(1). |
| [67] | MA S , MCDUFF D , SONG Y L . Neural TTS stylization with adversarial and collaborative games[C]// Proceedings of 2019 International Conference on Learning Representations,[S.l.:s.n.], 2019. |
| [68] | LEE S H , YOON H W , NOH H R ,et al. Multi-SpectroGAN:high-diversity and high-fidelity spectrogram generation with adversarial style combination for speech synthesis[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021,35(14): 13198-13206. |
| [69] | VALLE R , SHIH K , PRENGER R ,et al. Flowtron:an autoregressive flow-based generative network for text-to-speech synthesis[EB]. arXiv preprint, 2020. |
| [70] | MIAO C F , LIANG S , CHEN M C ,et al. Flow-TTS:a non-autoregressive network for text to speech based on flow[C]// Proceedings of2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 7209-7213. |
| [71] | KIM J , KIM S , KONG J ,et al. Glow-TTS:a generative flow for text-to-speech via monotonic alignment search[EB]. arXiv preprint, 2020,arXiv:2005.11129. |
| [72] | AN X C , SOONG F K , XIE L . Disentangling style and speaker attributes for TTS style transfer[J]. IEEE/ACM Transactions on Audio,Speech and Language Processing, 2022,30: 646-658. |
| [73] | JEONG M , KIM H , CHEON S J ,et al. DiffTTS:a denoising diffusion model for text-to-speech[C]// Proceedings of Interspeech 2021.[S.l.:s.n.], 2021. |
| [74] | ARIK S ? , DIAMOS G , GIBIANSKY A ,et al. Deep voice 2:multi-speaker neural text-to-speech[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. New York:ACM, 2017: 2966-2974. |
| [75] | WEI P , PENG K N , GIBIANSKY A ,et al. Deep Voice 3:2000-speaker neural text-to-speech[EB]. arXiv preprint, 2017,arXiv:1710.07654. |
| [76] | COOPER E , LAI C I , YASUDA Y ,et al. Zero-shot multi-speaker text-to-speech with state-of-the-art neural speaker embeddings[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 6184-6188. |
| [77] | NACHMANI E , POLYAK A , TAIGMAN Y ,et al. Fitting new speakers based on a short untranscribed sample[EB]. arXiv preprint, 2018,arXiv:1802.06984. |
| [78] | HUYBRECHTS G , MERRITT T , COMINI G ,et al. Low-resource expressive text-to-speech using data augmentation[C]// Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2021: 6593-6597. |
| [79] | TERASHIMA R , YAMAMOTO R , SONG E ,et al. Cross-speaker emotion transfer for low-resource text-to-speech using non-parallel voice conversion with pitchshift data augmentation[C]// Proceedings of Interspeech 2022.[S.l.:s.n.], 2022. |
| [80] | SAM RIBEIRO M , ROTH J , COMINI G ,et al. Cross-speaker style transfer for text-to-speech using data augmentation[C]// Proceedings of ICASSP 2022 - 2022 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2022: 6797-6801. |
| [81] | SHAH R , POKORA K , EZZERG A ,et al. Nonautoregressive TTS with explicit duration modelling for low-resource highly expressive speech[C]// Proceedings of 11th ISCA Speech Synthesis Workshop.[S.l.:s.n.], 2021. |
| [82] | LAJSZCZAK M , PRASAD A , VAN KORLAAR A ,et al. Distribution augmentation for lowresource expressive text-to-speech[C]// Proceedings of ICASSP 2022 - 2022 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2022: 8307-8311. |
| [1] | 张伶俐, 褚琦凯, 王桂娟, 张巍瀚, 蒲慧, 宋振金, 吴亚东. 文本情感可视分析技术及其在人文领域的应用[J]. 大数据, 2022, 8(6): 56-73. |
| [2] | 吴建汉, 司世景, 王健宗, 肖京. 联邦学习攻击与防御综述[J]. 大数据, 2022, 8(5): 12-32. |
| [3] | 任帅, 陈丹丹, 储根深, 白鹤, 李慧昭, 何远杰, 胡长军. 基于材料数值计算大数据的材料辐照机理发现[J]. 大数据, 2021, 7(6): 3-18. |
| [4] | 于璠. 新一代深度学习框架研究[J]. 大数据, 2020, 6(4): 69-80. |
| [5] | 张旭东, 孙圣力, 王洪超. 基于数据挖掘的触诊成像乳腺癌智能诊断模型和方法[J]. 大数据, 2019, 5(1): 68-76. |
| [6] | 肖时耀, 吕慰, 陈洒然, 秦烁, 黄格, 蔡梦思, 谭跃进, 谭旭, 吕欣. 基于百度贴吧的HIV高危人群特征分析[J]. 大数据, 2019, 5(1): 98-108. |
| [7] | 王秉睿, 兰慧盈, 陈云霁. 深度学习编程框架[J]. 大数据, 2018, 4(4): 56-63. |
| [8] | 张国宾, 王晓蓉, 邓春宇. 基于关联分析与机器学习的配网台区重过载预测方法[J]. 大数据, 2018, 4(1): 105-116. |
| [9] | 王冬海,卢峰,方晓蓉,郭刚. 海洋大数据关键技术及在灾害天气下船舶行为预测上的应用[J]. 大数据, 2017, 3(4): 81-90. |
| [10] | 牟少敏, 温孚江, 宋长青. 农业大数据研究生培养模式探索[J]. 大数据, 2016, 2(1): 53-58. |
| [11] | 林春雨, 李崇纲, 许方圆, 许会泉, 石磊, 卢祥虎. 基于大数据技术的P2P网贷平台风险预警模型[J]. 大数据, 2015, 1(4): 18-28. |
| [12] | 黄宜华. 大数据机器学习系统研究进展[J]. 大数据, 2015, 1(1): 35-54. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||