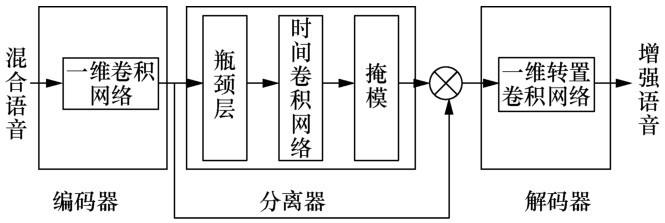
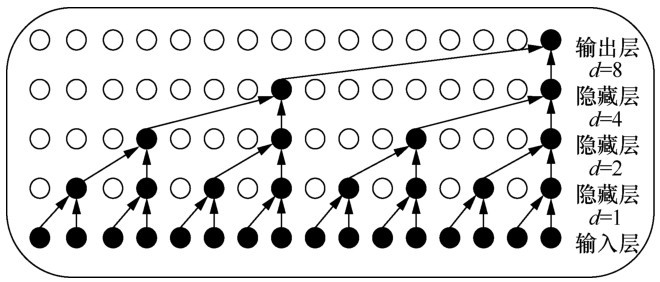
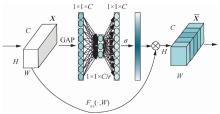
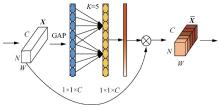
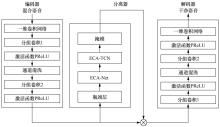
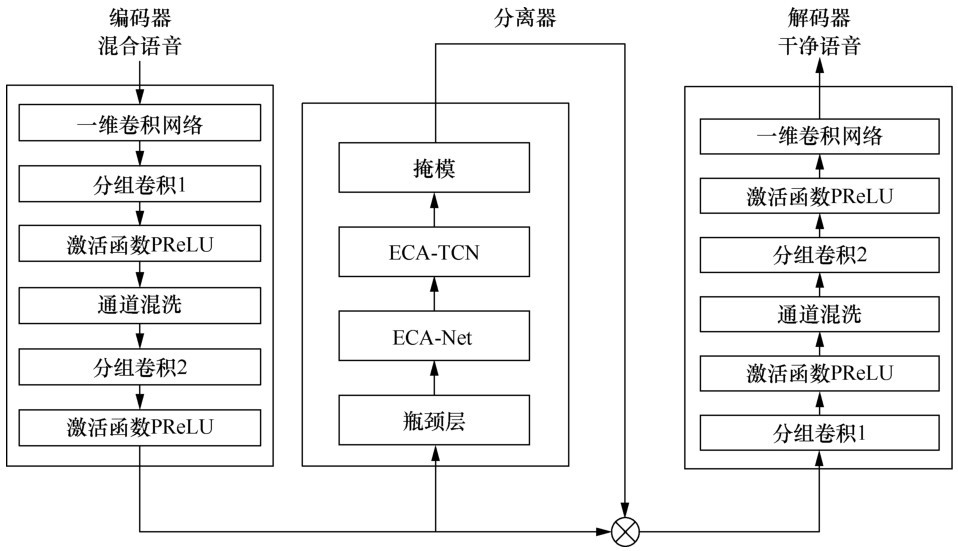
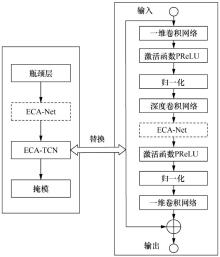
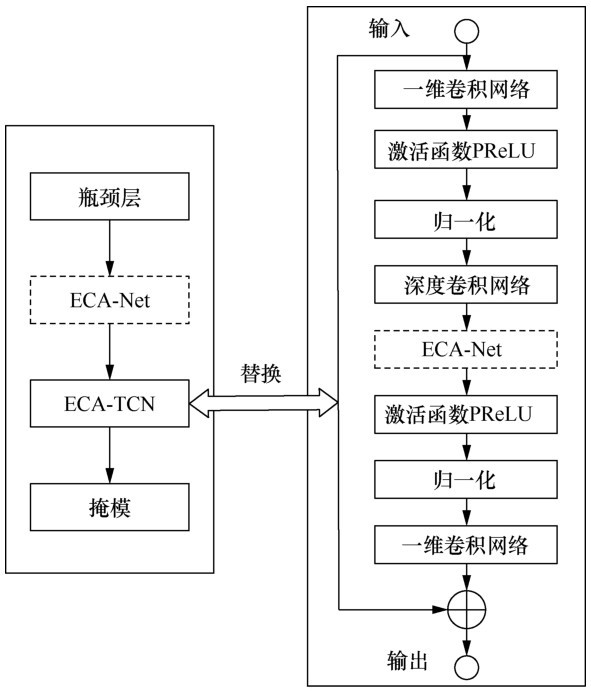
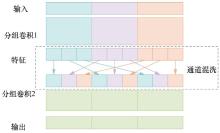
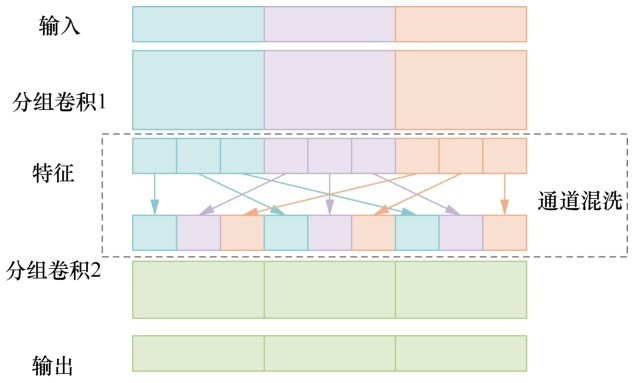
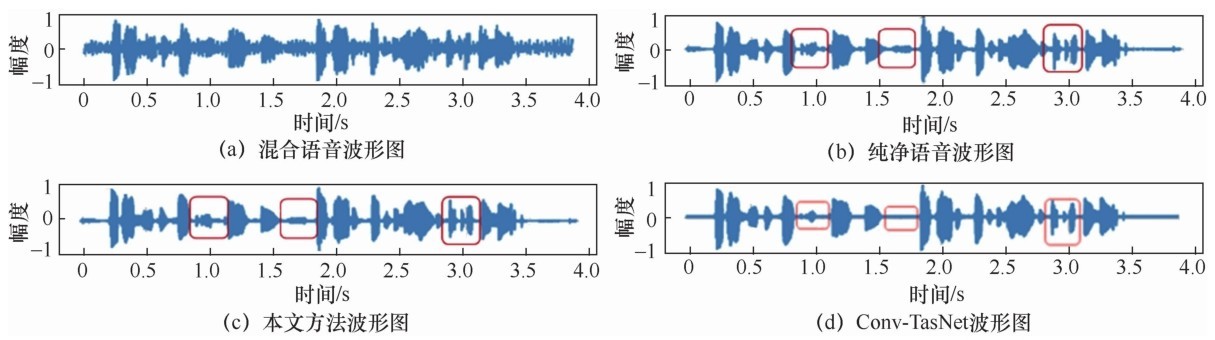
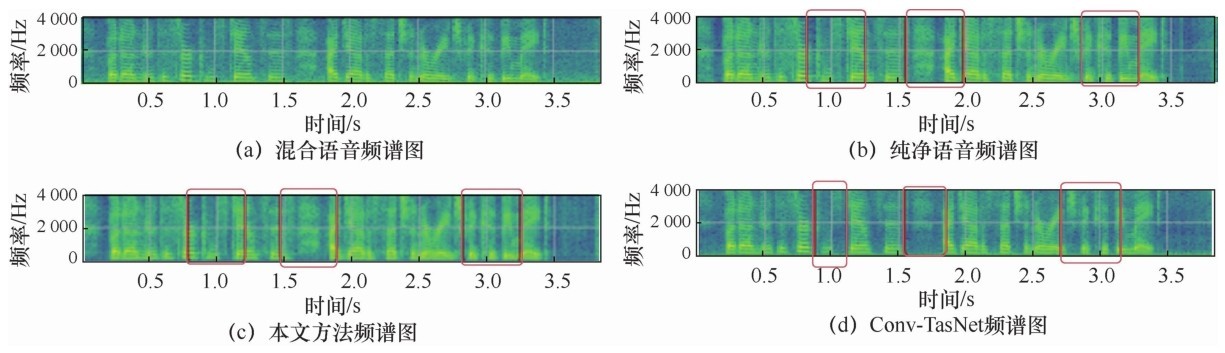
| [1] |
LOIZOU P . Speech enhancement:theory and practice[M]. Boca Raton: CRC Press, 2007.
|
| [2] |
ZHOU N , DU J , TU Y H ,et al. A speech enhancement neural network architecture with SNR-progressive multi-target learning for robust speech recognition[C]// Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference. Piscataway:IEEE Press, 2019: 873-877.
|
| [3] |
WU B , YU M , CHEN L W ,et al. Distortionless multi-channel target speech enhancement for overlapped speech recognition[J]. arXiv preprints,2020,arXiv:2007.01566.
|
| [4] |
张钹 . 人工智能进入后深度学习时代[J]. 智能科学与技术学报, 2019,1(1): 4-6.
|
|
ZHANG B . Artificial intelligence is entering the post deep-learning era[J]. Chinese Journal of Intelligent Science and Technology, 2019,1(1): 4-6.
|
| [5] |
GRZYWALSKI T , DRGAS S . Using recurrences in time and frequency within U-Net architecture for speech enhancement[C]// Proceedings of the 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 6970-6974.
|
| [6] |
TAN K , WANG D L . A convolutional recurrent neural network for real-time speech enhancement[C]// Proceedings of the INTERSPEECH 2018.[S.l.:s.n.], 2018: 3229-3233.
|
| [7] |
WANG D , LIM J . The unimportance of phase in speech enhancement[J]. IEEE Transactions on Acoustics,Speech,and Signal Processing, 1982,30(4): 679-681.
|
| [8] |
PALIWAL K , WóJCICKI K , SHANNON B . The importance of phase in speech enhancement[J]. Speech Communication, 2011,53(4): 465-494.
|
| [9] |
LU X G , TSAO Y , MATSUDA S ,et al. Speech enhancement based on deep denoising autoencoder[C]// Proceedings of the INTERSPEECH 2018.[S.l.:s.n.], 2018: 436-440.
|
| [10] |
DEN OORD A V , DIELEMAN S , ZEN H ,et al. WaveNet:a generative model for raw audio[J]. arXiv preprint,2016,arXiv:1609.03499.
|
| [11] |
PANDEY A , WANG D L . A new framework for CNN-based speech enhancement in the time domain[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2019,27(7): 1179-1188.
|
| [12] |
LUO Y , MESGARANI N . Conv-TasNet:surpassing ideal time- frequency magnitude masking for speech separation[J]. IEEE/ACM Transactions on Audio,Speech,and Language Processing, 2019,27(8): 1256-1266.
|
| [13] |
BAI S J , KOLTER J Z , KOLTUN V . An empirical evaluation of generic convolutional and recurrent networks for sequence modeling[J]. arXiv preprint,2018,arXiv:1803.01271.
|
| [14] |
SHI Z Q , LIN H B , LIU L ,et al. Deep attention gated dilated temporal convolutional networks with intra-parallel convolutional modules for end-to-end monaural speech separation[C]// Proceedings of the INTERSPEECH 2019.[S.l.:s.n.], 2019: 3183-3187.
|
| [15] |
SHI Z Q , LIN H B , LIU L ,et al. End-to-end monaural speech separation with multi-scale dynamic weighted gated dilated convolutional pyramid network[C]// Proceedings of the INTERSPEECH 2019.[S.l.:s.n.], 2019: 4614-4618.
|
| [16] |
马玮良, 彭轩, 熊倩 ,等. 深度学习中的内存管理问题研究综述[J]. 大数据, 2020,6(4): 56-68.
|
|
MA W L , PENG X , XIONG Q ,et al. Memory management in deep learning:a survey[J]. Big Data Research, 2020,6(4): 56-68.
|
| [17] |
COSENTINO J , PARIENTE M , CORNELL S ,et al. LibriMix:an open-source dataset for generalizable speech separation[J]. arXiv preprint,2020,arXiv:2005.11262.
|
| [18] |
HE K M , ZHANG X Y , REN S Q ,et al. Delving deep into rectifiers:surpassing human-level performance on ImageNet classification[C]// Proceedings of the 2015 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2015: 1026-1034.
|
| [19] |
LEA C , VIDAL R , REITER A ,et al. Temporal convolutional networks:a unified approach to action segmentation[M]. Lecture notes in computer science. Cham: Springer International Publishing, 2016.
|
| [20] |
HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778.
|
| [21] |
HOWARD A G , ZHU M L , CHEN B ,et al. MobileNets:efficient convolutional neural networks for mobile vision applications[J]. arXiv preprint,2017,arXiv:1704.04861.
|
| [22] |
LUO Y , MESGARANI N . TaSNet:time-domain audio separation network for real-time,single-channel speech separation[C]// Proceedings of the 2018 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2018: 696-700.
|
| [23] |
WANG Q L , WU B G , ZHU P F ,et al. ECA-Net:efficient channel attention for deep convolutional neural networks[C]// Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11531-11539.
|
| [24] |
HU J , SHEN L , ALBANIE S ,et al. Squeeze-and-excitation networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020,42(8): 2011-2023.
|
| [25] |
SZEGEDY C , LIU W JIA Y Q ,et al. Going deeper with convolutions[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2014.
|
| [26] |
BELL S , ZITNICK C L , BALA K ,et al. Inside-Outside net:detecting objects in context with skip pooling and recurrent neural networks[C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 2874-2883.
|
| [27] |
ZHANG X Y , ZHOU X Y , LIN M X ,et al. ShuffleNet:an extremely efficient convolutional neural network for mobile devices[C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 6848-6856.
|
| [28] |
KRIZHEVSKY A , SUTSKEVER I , HINTON G E . ImageNet classification with deep convolutional neural networks[J]. Communications of the ACM, 2017,60(6): 84-90.
|
| [29] |
PANAYOTOV V , CHEN G G , POVEY D ,et al. LibriSpeech:an ASR corpus based on public domain audio books[C]// Proceedings of the 2015 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2015: 5206-5210.
|
| [30] |
WICHERN G , ANTOGNINI J , FLYNN M ,et al. WHAM!:extending speech separation to noisy environments[C]// Proceedings of the INTERSPEECH 2019.[S.l.:s.n.], 2019.
|
| [31] |
ROUX J L , WISDOM S , ERDOGAN H ,et al. SDR – half-baked or well done?[C]// Proceedings of the 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 626-630.
|
| [32] |
RIX ANTONY W , BEERENDS JOHN G , HOLLIER MICHAEL P ,et al. Perceptual evaluation of speech quality (PESQ) - a new method for speech quality assessment of telephone networks and codecs[C]// Proceedings of the 2001 IEEE International Conference on Acoustics,Speech,and Signal Processing. Piscataway:IEEE Press, 2002: 749-752.
|
| [33] |
TAAL C H , HENDRIKS R C , HEUSDENS R ,et al. An algorithm for intelligibility prediction of time–frequency weighted noisy speech[J]. IEEE Transactions on Audio Speech & Language Processing, 2011,19(7): 2125-2136.
|