

通信学报 ›› 2022, Vol. 43 ›› Issue (9): 194-208.doi: 10.11959/j.issn.1000-436x.2022178
王延文, 雷为民, 张伟, 孟欢, 陈新怡, 叶文慧, 景庆阳
修回日期:2022-08-22
出版日期:2022-09-25
发布日期:2022-09-01
作者简介:王延文(1998- ),女,辽宁辽阳人,东北大学博士生,主要研究方向为计算机视觉、视频图像压缩编码基金资助:Yanwen WANG, Weimin LEI, Wei ZHANG, Huan MENG, Xinyi CHEN, Wenhui YE, Qingyang JING
Revised:2022-08-22
Online:2022-09-25
Published:2022-09-01
Supported by:摘要:
基于像素相关性的传统视频压缩技术性能提升空间受限,语义压缩成为视频压缩编码的新方向,视频图像重建是语义压缩编码的关键环节。首先介绍了针对传统编码优化的视频图像重建方法,包括如何利用深度学习提升预测精度和利用超分辨率技术增强重建质量;其次讨论了基于变分自编码器、基于生成对抗网络、基于自回归模型和基于 Transformer 模型的视频图像重建方法,并根据图像的不同语义表征对模型进行分类,对比了各类方法的优缺点及其适用场景;最后总结了现有视频图像重建存在的问题,并进一步展望研究方向。
中图分类号:
王延文, 雷为民, 张伟, 孟欢, 陈新怡, 叶文慧, 景庆阳. 基于生成模型的视频图像重建方法综述[J]. 通信学报, 2022, 43(9): 194-208.
Yanwen WANG, Weimin LEI, Wei ZHANG, Huan MENG, Xinyi CHEN, Wenhui YE, Qingyang JING. Survey on video image reconstruction method based on generative model[J]. Journal on Communications, 2022, 43(9): 194-208.
表1
基于传统编码框架的视频图像重建的基本原理和主要方法"
| 类别 | 目的 | 原理 | 主要方法 |
| 帧内预测 | 消除空间冗余 | 基于相邻重建像素预测当前编码块 | 优化预测模式、直接预测像素值、对传统预测结果进行增强 |
| 帧间预测 | 消除时间冗余 | 基于先前重建帧为参考,利用运动估计和运动补偿完成预测 | 增强参考帧质量与多样性、双向帧间预测、分数像素插值、光流估计 |
| 超分辨率重建 | 提升图像质量 | 编码端下采样降低图像分辨率/解码端上采样提高重建图像分辨率 | 传统下采样+深度网络上采样、深度网络下采样+深度网络上采样 |

图1
基于超分辨率的编码重建框架"

表2
基于生成模型的重建方法的分析与比较"
| 模型 | 重建依据 | 特点 |
| 变分自编码器 | 编解码端学习条件分布,用于拟合真实分布 | 数学方法明确,易于训练,但对于复杂图像生成样本模糊 |
| 生成对抗网络 | 边缘、颜色、纹理 | 适用对象更广泛,但目前用于实验的视频分辨率较低 |
| 面部结构特征点、特征域关键点 | 压缩比更高,但对动作主体要求较为严格,适用场景单一 | |
| 语义分割图 | 同时建立语义与结构表示,但传输语义图会消耗较多码流 | |
| 自回归像素建模 | 将图像像素联合分布转换为条件分布,逐像素点预测 | 善于捕捉图像局部细节,但无法并行计算,重建速度慢且计算成本高 |
| Transformer | 直接对像素建模 | 善于建模图像长期相关性,增大感受野,但难以保证生成图像分辨率 |
| 自回归预测图像的离散视觉标记,将其映射回像素空间 | 离散数据使图像特征表示更高效,但自回归重建时间相对较长 | |
| 掩码视觉token | 更高效地利用数据进行表征学习,但对于视频的应用较少 | |
| 利用Transformer搭建GAN的生成框架 | 更好地捕捉全局信息,但计算成本较高 |
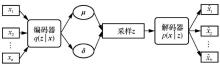
图2
变分自编码器网络架构"
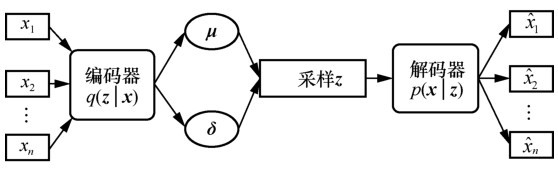
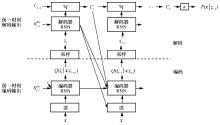
图3
DRAW网络结构"
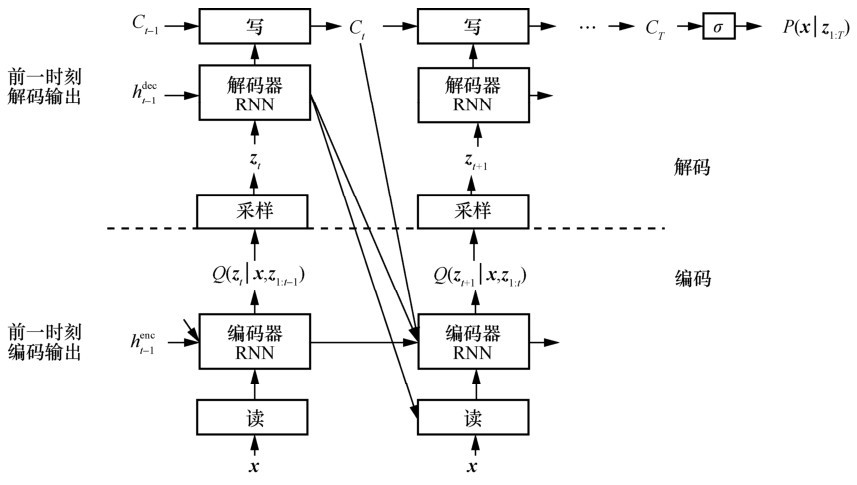
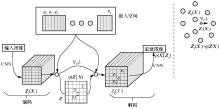
图4
VQ-VAE示意"
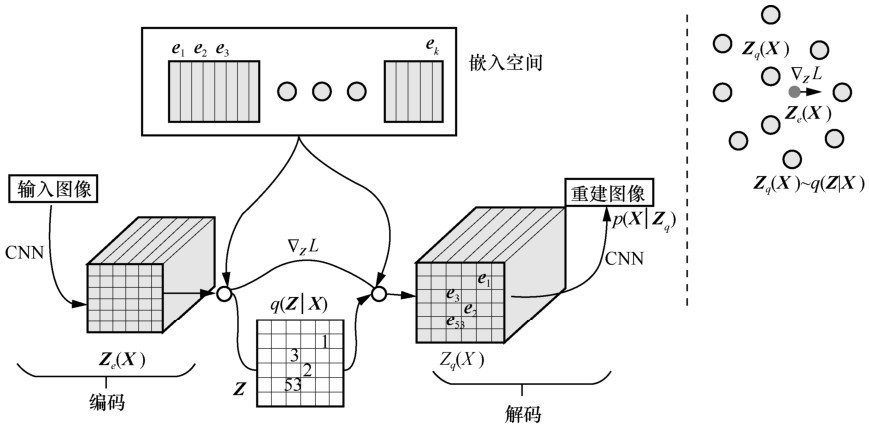
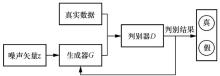
图5
生成对抗网络示意"

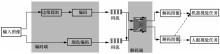
图6
基于边缘的编码重建框架"
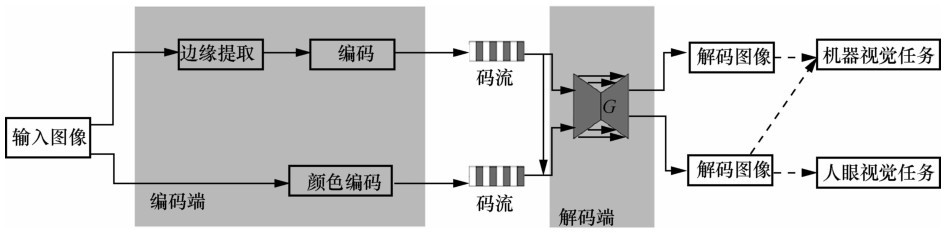

图7
层间感知的图像压缩和重建网络架构"

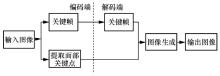
图8
基于面部关键点的视频重建网络架构"
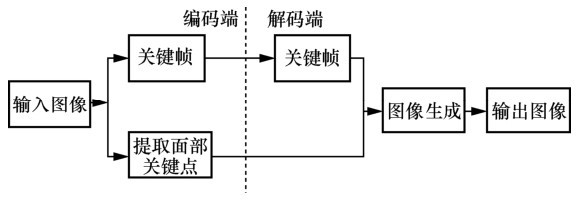
图9
基于关键点的talking-head视频合成整体框架"

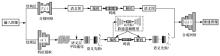
图10
基于语义先验建模的图像压缩和重建架构"
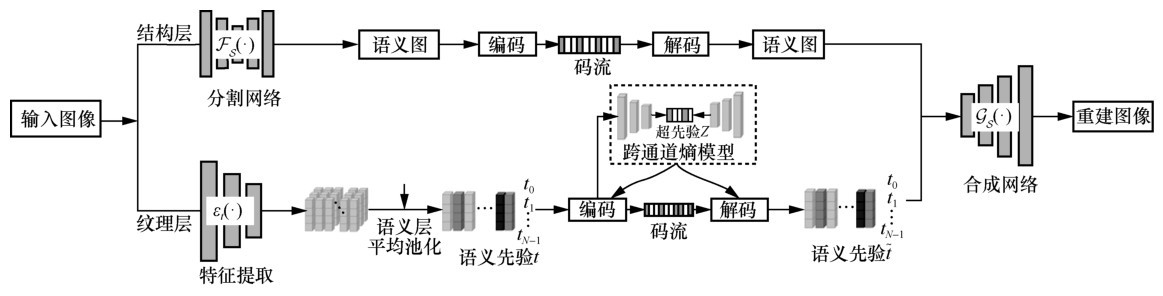
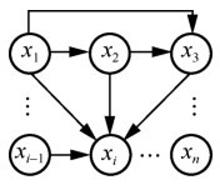
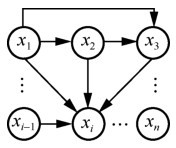
图11
像素概率预测示意"
| [11] | WANG W L , LI Z R . Advances in generative adversarial network[J]. Journal on Communications, 2018,39(2): 135-148. |
| [12] | LI J H , LI B , XU J Z ,et al. Fully connected network-based intra prediction for image coding[J]. IEEE Transactions on Image Processing, 2018,27(7): 3236-3247. |
| [13] | CUI W X , ZHANG T , ZHANG S P ,et al. Convolutional neural networks based intra prediction for HEVC[J]. arXiv Preprint,arXiv:1808.05734, 2018. |
| [14] | HU Y Y , YANG W H , LI M D ,et al. Progressive spatial recurrent neural network for intra prediction[J]. IEEE Transactions on Multimedia, 2019,21(12): 3024-3037. |
| [15] | ZHU L W , KWONG S , ZHANG Y ,et al. Generative adversarial network-based intra prediction for video coding[J]. IEEE Transactions on Multimedia, 2020,22(1): 45-58. |
| [16] | ZHAO L , WANG S Q , ZHANG X F ,et al. Enhanced motion-compensated video coding with deep virtual reference frame generation[J]. IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society, 2019,28(10): 4832-4844. |
| [17] | GUO Y , LIU Z Z , CHEN Z Z ,et al. Deep inter coding with interpolated reference frame for hierarchical coding structure[C]// Proceedings of 2020 IEEE International Conference on Visual Communications and Image Processing. Piscataway:IEEE Press, 2020: 302-305. |
| [18] | ZHAO Z H , WANG S Q , WANG S S ,et al. Enhanced bi-prediction with convolutional neural network for high-efficiency video coding[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019,29(11): 3291-3301. |
| [19] | YAN N , LIU D , LI H Q ,et al. Convolutional neural network-based fractional-pixel motion compensation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019,29(3): 840-853. |
| [20] | WANG Z H , CHEN J , HOI S C H . Deep learning for image super-resolution:a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021,43(10): 3365-3387. |
| [21] | LI Y , LIU D , LI H Q ,et al. Convolutional neural network-based block up-sampling for intra frame coding[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018,28(9): 2316-2330. |
| [22] | AFONSO M , ZHANG F , BULL D R . Video compression based on spatio-temporal resolution adaptation[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2019,29(1): 275-280. |
| [23] | KIM J , LEE J K , LEE K M . Accurate image super-resolution using very deep convolutional networks[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 1646-1654. |
| [24] | JIANG F , TAO W , LIU S H ,et al. An end-to-end compression framework based on convolutional neural networks[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2018,28(10): 3007-3018. |
| [25] | SOHN K , YAN X C , LEE H ,et al. Learning structured output representation using deep conditional generative models[C]// Proceedings of International Conference on Neural Information Processing Systems. Massachusetts:MIT Press, 2015: 3483-3491. |
| [26] | ESSER P , SUTTER E . A variational U-net for conditional appearance and shape generation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 8857-8866. |
| [27] | ISOLA P , ZHU J Y , ZHOU T H ,et al. Image-to-image translation with conditional adversarial networks[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 5967-5976. |
| [28] | GREGOR K , DANIHELKA I , GRAVES A ,et al. Draw:a recurrent neural network for image generation[C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. New York:PMLR, 2015: 1462-1471. |
| [29] | GREGOR K , BESSE F , REZENDE D J ,et al. Towards conceptual compression[J]. arXiv Preprint,arXiv:1604.08772, 2016. |
| [30] | S?NDERBY C K , RAIKO T , MAAL?E L , ,et al. Ladder variational autoencoders[J]. arXiv Preprint,arXiv:1602.02282, 2016. |
| [31] | MAAL?E L , FRACCARO M , LIéVIN V , ,et al. BIVA:a very deep hierarchy of latent variables for generative modeling[J]. arXiv Preprint,arXiv:1902.02102, 2019. |
| [32] | VAHDAT A , KAUTZ J . NVAE:a deep hierarchical variational autoencoder[J]. arXiv Preprint,arXiv:2007.03898, 2020. |
| [33] | KINGMA D P , SALIMANS T , JOZEFOWICZ R ,et al. Improved variational inference with inverse autoregressive flow[J]. arXiv Preprint,arXiv:1606.04934, 2016. |
| [34] | OORD A V D , VINYALS O , KAVUKCUOGLU K . Neural discrete representation learning[J]. arXiv Preprint,arXiv:1711.00937, 2017. |
| [35] | RAZAVI A , OORD A V D , VINYALS O . Generating diverse high-fidelity images with VQ-VAE-2[J]. arXiv Preprint,arXiv:1906.00446, 2019. |
| [36] | MIRZA M , OSINDERO S . Conditional generative adversarial nets[J]. arXiv Preprint,arXiv:1411.1784, 2014. |
| [37] | WANG T C , LIU M Y , ZHU J Y ,et al. High-resolution image synthesis and semantic manipulation with conditional GANs[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 8798-8807. |
| [38] | HU Y Y , YANG S , YANG W H ,et al. Towards coding for human and machine vision:a scalable image coding approach[C]// Proceedings of 2020 IEEE International Conference on Multimedia and Expo. Piscataway:IEEE Press, 2020: 1-6. |
| [39] | KIM S , PARK J S , BAMPIS C G ,et al. Adversarial video compression guided by soft edge detection[C]// Proceedings of 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 2193-2197. |
| [40] | CHANG J H , MAO Q , ZHAO Z H ,et al. Layered conceptual image compression via deep semantic synthesis[C]// Proceedings of 2019 IEEE International Conference on Image Processing. Piscataway:IEEE Press, 2019: 694-698. |
| [41] | CHANG J H , ZHAO Z H , JIA C M ,et al. Conceptual compression via deep structure and texture synthesis[J]. IEEE Transactions on Image Processing:a Publication of the IEEE Signal Processing Society, 2022,31: 2809-2823. |
| [42] | DOLLáR P , ZITNICK C L . Structured forests for fast edge detection[C]// Proceedings of 2013 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2013: 1841-1848. |
| [43] | XIE S N , TU Z W . Holistically-nested edge detection[C]// Proceedings of 2015 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2015: 1395-1403. |
| [44] | HA S , KERSNER M , KIM B ,et al. MarioNETte:few-shot face reenactment preserving identity of unseen targets[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2020: 10893-10900. |
| [45] | ZHAO R Q , WU T Y , GUO G D . Sparse to dense motion transfer for face image animation[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). Piscataway:IEEE Press, 2021: 1991-2000. |
| [46] | ZAKHAROV E , IVAKHNENKO A , SHYSHEYA A ,et al. Fast bi-layer neural synthesis of one-shot realistic head avatars[C]// European Conference on Computer Vision. Berlin:Springer, 2020: 524-540. |
| [47] | FENG D H , HUANG Y , ZHANG Y W ,et al. A generative compression framework for low bandwidth video conference[C]// Proceedings of 2021 IEEE International Conference on Multimedia & Expo Workshops. Piscataway:IEEE Press, 2021: 1-6. |
| [48] | NIRKIN Y , KELLER Y , HASSNER T . FSGAN:subject agnostic face swapping and reenactment[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2019: 7183-7192. |
| [49] | OQUAB M , STOCK P , GAFNI O ,et al. Low bandwidth video-chat compression using deep generative models[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway:IEEE Press, 2021: 2388-2397. |
| [50] | PARK T , LIU M Y , WANG T C ,et al. Semantic image synthesis with spatially-adaptive normalization[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 2332-2341. |
| [51] | HONG F T , ZHANG L , SHEN L ,et al. Depth-aware generative adver-saril network for talking head video generation[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2022: 3397-3406. |
| [52] | SIAROHIN A , LATHUILIèRE S , TULYAKOV S ,et al. Animating arbitrary objects via deep motion transfer[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 2372-2381. |
| [53] | SIAROHIN A , LATHUILIèRE S , TULYAKOV S ,et al. First order motion model for image animation[J]. arXiv Preprint,arXiv:2003.00196, 2020. |
| [54] | WANG T C , MALLYA A , LIU M Y . One-shot free-view neural talking-head synthesis for video conferencing[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 10034-10044. |
| [55] | KONUKO G , VALENZISE G , LATHUILIèRE S , . Ultra-low bitrate video conferencing using deep image animation[C]// Proceedings of 2021 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2021: 4210-4214. |
| [56] | WANG T C , LIU M Y , TAO A ,et al. Few-shot video-to-video synthesis[J]. arXiv Preprint,arXiv:1910.12713, 2019. |
| [57] | CHAN C , GINOSAR S , ZHOU T H ,et al. Everybody dance now[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision (ICCV). Piscataway:IEEE Press, 2019: 5932-5941. |
| [58] | XIA S F , LIANG K , YANG W H ,et al. An emerging coding paradigm vcm:a scalable coding approach beyond feature and signal[C]// Proceedings of 2020 IEEE International Conference on Multimedia and Expo. Piscataway:IEEE Press, 2020: 1-6. |
| [1] | WIEGAND T , SULLIVAN G J , BJONTEGAARD G ,et al. Overview of the H.264/AVC video coding standard[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2003,13(7): 560-576. |
| [2] | SULLIVAN G J , OHM J R , HAN W J ,et al. Overview of the high efficiency video coding (HEVC) standard[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2012,22(12): 1649-1668. |
| [59] | PRABHAKAR R , CHANDAK S , CHIU C ,et al. Reducing latency and bandwidth for video streaming using keypoint extraction and digital puppetry[J]. arXiv Preprint,arXiv:2011.03800, 2020. |
| [60] | WU Y J , HE T Y , CHEN Z B . Memorize,then recall:a generative framework for low bit-rate surveillance video compression[C]// Proceedings of 2020 IEEE International Symposium on Circuits and Systems. Piscataway:IEEE Press, 2020: 1-5. |
| [3] | SEGALL A , BARONCINI V , BOYCE J ,et al. JVET-H1002:joint call for proposals on video compression with capability beyond HEVC[J]. Joint Video Exploration Team (JVET) of ITU-T SG, 2017,16: 18-24. |
| [4] | 胡铭菲, 左信, 刘建伟 . 深度生成模型综述[J]. 自动化学报, 2022,48(1): 40-74. |
| [61] | SHI X , CHEN Z , WANG H ,et al. Convolutional LSTM network:a machine learning approach for precipitation nowcasting[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. Massachusetts:MIT Press, 2015: 802-810. |
| [62] | WANG T C , LIU M Y , ZHU J Y ,et al. Video-to-video synthesis[J]. arXiv Preprint,arXiv:1808.06601, 2018. |
| [4] | HU M F , ZUO X , LIU J W . Survey on deep generative model[J]. Acta Automatica Sinica, 2022,48(1): 40-74. |
| [5] | SUN Q , GUO C , YANG Y ,et al. Semantic-assisted image compression[J]. arXiv Preprint,arXiv:2201.12599, 2022. |
| [63] | PAN J T , WANG C Y , JIA X ,et al. Video generation from single semantic label map[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 3728-3737. |
| [64] | ZHU P H , ABDAL R , QIN Y P ,et al. SEAN:image synthesis with semantic region-adaptive normalization[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2020: 5103-5112. |
| [6] | LUO S H , YANG Y Z , YIN Y L ,et al. DeepSIC:deep semantic image compression[C]// International Conference on Neural Information Processing. Berlin:Springer, 2018: 96-106. |
| [7] | KINGMA D P , WELLING M . Auto-encoding variational Bayes[J]. arXiv Preprint,arXiv:1312.6114, 2013. |
| [65] | AKBARI M , LIANG J , HAN J N . DSSLIC:deep semantic segmentation-based layered image compression[C]// Proceedings of 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 2042-2046. |
| [66] | HOANG T M , ZHOU J J , FAN Y B . Image compression with encoder-decoder matched semantic segmentation[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway:IEEE Press, 2020: 619-623. |
| [8] | CRESWELL A , WHITE T , DUMOULIN V ,et al. Generative adversarial networks:an overview[J]. IEEE Signal Processing Magazine, 2018,35(1): 53-65. |
| [9] | AKAIKE H . Fitting autoregressive models for prediction[J]. Annals of the Institute of Statistical Mathematics, 1969,21(1): 243-247. |
| [67] | CHANG J H , ZHAO Z H , YANG L B ,et al. Thousand to one:semantic prior modeling for conceptual coding[C]// Proceedings of 2021 IEEE International Conference on Multimedia and Expo. Piscataway:IEEE Press, 2021: 1-6. |
| [68] | OORO A V D , KALCHBRENNER N , KAVUKCUOGLU K . Pixel recurrent neural networks[C]// Proceedings of the 33th International Conference on International Conference on Machine Learning. New York:PMLR, 2016: 1747-1756. |
| [10] | VASWANI A , SHAZEER N , PARMAR N ,et al. Attention is all you need[J]. arXiv Preprint,arXiv:1706.03762, 2017. |
| [11] | 王万良, 李卓蓉 . 生成式对抗网络研究进展[J]. 通信学报, 2018,39(2): 135-148. |
| [69] | OORO A V D , KALCHBRENNER N , VINYALS O ,et al. Conditional image generation with PixelCNN decoders[J]. arXiv Preprint,arXiv:1606.05328, 2016. |
| [70] | SALIMANS T , KARPATHY A , CHEN X ,et al. PixelCNN++:improving the PixelCNN with discretized logistic mixture likelihood and other modifications[J]. arXiv Preprint,arXiv:1701.05517, 2017. |
| [71] | CHEN X , MISHRA N , ROHANINEJAD M ,et al. Pixelsnail:an improved autoregressive generative model[C]// Proceedings of the 35th International Conference on International Conference on Machine Learning. New York:PMLR, 2018: 864-872. |
| [72] | MENICK J , KALCHBRENNER N . Generating high fidelity images with subscale pixel networks and multidimensional upscaling[J]. arXiv Preprint,arXiv:1812.01608, 2018. |
| [73] | KALCHBRENNER N , OORD A , SIMONYAN K ,et al. Video pixel networks[C]// Proceedings of the 34th International Conference on International Conference on Machine Learning. New York:PMLR, 2017: 1771-1779. |
| [74] | PARMAR N , VASWANI A , USZKOREIT J ,et al. Image transformer[C]// Proceedings of the 35th International Conference on International Conference on Machine Learning. New York:PMLR, 2018: 4055-4064. |
| [75] | ESSER P , ROMBACH R , OMMER B . Taming transformers for high-resolution image synthesis[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 12868-12878. |
| [76] | CHEN M , RADFORD A , CHILD R ,et al. Generative pretraining from pixels[C]// Proceedings of the 37th International Conference on International Conference on Machine Learning. New York:PMLR, 2020: 1691-1703. |
| [77] | YAN W , ZHANG Y Z , ABBEEL P ,et al. VideoGPT:video generation using VQ-VAE and transformers[J]. arXiv Preprint,arXiv:2104.10157, 2021. |
| [78] | RAKHIMOV R , VOLKHONSKIY D , ARTEMOV A ,et al. Latent video transformer[J]. arXiv Preprint,arXiv:2006.10704, 2020. |
| [79] | WU C F , LIANG J , JI L ,et al. NüWA:visual synthesis pre-training for neural visual world creation[J]. arXiv Preprint,arXiv:2111.12417, 2021. |
| [80] | LEE J , KIM D , HAM B . Network quantization with element-wise gradient scaling[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2021: 6444-6453. |
| [81] | BAO H B , DONG L , WEI F . BEiT:BERT pre-training of image transformers[J]. arXiv Preprint,arXiv:2106.08254, 2021. |
| [82] | HE K , CHEN X , XIE S ,et al. Masked autoencoders are scalable vision learners[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2022: 16000-16009. |
| [83] | XIE Z , ZHANG Z , CAO Y ,et al. Simmim:a simple framework for masked image modeling[C]// Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2022: 9653-9663. |
| [84] | CHANG H W , ZHANG H , JIANG L ,et al. MaskGIT:masked generative image transformer[J]. arXiv Preprint,arXiv:2202.04200, 2022. |
| [85] | JIANG Y , CHANG S , WANG Z . TransGAN:two pure transformers can make one strong GAN,and that can scale up[J]. Advances in Neural Information Processing Systems, 2021,34: 14745-14758. |
| [86] | ZHAO L , ZHANG Z Z , CHEN T ,et al. Improved transformer for high-resolution GANs[J]. Advances in Neural Information Processing Systems, 2021,34: 18367-18380. |
| [87] | ZHANG B W , GU S Y , ZHANG B ,et al. StyleSwin:transformer-based GAN for high-resolution image generation[J]. arXiv Preprint,arXiv:2112.10762, 2021. |
| [88] | KARRAS T , LAINE S , AILA T M . A style-based generator architecture for generative adversarial networks[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Piscataway:IEEE Press, 2019: 4396-4405. |
| [1] | 张佳乐, 朱诚诚, 孙小兵, 陈兵. 基于GAN的联邦学习成员推理攻击与防御方法[J]. 通信学报, 2023, 44(5): 193-205. |
| [2] | 苏新, 张桂福, 行鸿彦, Zenghui Wang. 基于平衡生成对抗网络的海洋气象传感网入侵检测研究[J]. 通信学报, 2023, 44(4): 124-136. |
| [3] | 王一丰, 郭渊博, 陈庆礼, 方晨, 林韧昊, 周永良, 马佳利. 基于对比增量学习的细粒度恶意流量分类方法[J]. 通信学报, 2023, 44(3): 1-11. |
| [4] | 霍纬纲, 梁锐, 李永华. 基于随机Transformer的多维时间序列异常检测模型[J]. 通信学报, 2023, 44(2): 94-103. |
| [5] | 刘延华, 李嘉琪, 欧振贵, 高晓玲, 刘西蒙, MENG Weizhi, 刘宝旭. 对抗训练驱动的恶意代码检测增强方法[J]. 通信学报, 2022, 43(9): 169-180. |
| [6] | 李昂, 陈建新, 魏昕, 周亮. 面向6G的跨模态信号重建技术[J]. 通信学报, 2022, 43(6): 28-40. |
| [7] | 段雪源, 付钰, 王坤. 基于VAE-WGAN的多维时间序列异常检测方法[J]. 通信学报, 2022, 43(3): 1-13. |
| [8] | 向夏雨, 王佳慧, 王子睿, 段少明, 潘鹤中, 庄荣飞, 韩培义, 刘川意. 基于生成对抗网络技术的医疗仿真数据生成方法[J]. 通信学报, 2022, 43(3): 211-224. |
| [9] | 王一丰, 郭渊博, 陈庆礼, 方晨, 林韧昊. 基于对比学习的细粒度未知恶意流量分类方法[J]. 通信学报, 2022, 43(10): 12-25. |
| [10] | 陆彦辉, 柳寒, 李航, 朱光旭. 基于多鉴别器生成对抗网络的时间序列生成模型[J]. 通信学报, 2022, 43(10): 167-176. |
| [11] | 刘威, 陈成, 江锐, 卢涛. 四通道无监督学习图像去雾网络[J]. 通信学报, 2022, 43(10): 210-222. |
| [12] | 周志立, 王美民, 杨高波, 朱剑宇, 孙星明. 基于轮廓自动生成的构造式图像隐写方法[J]. 通信学报, 2021, 42(9): 144-154. |
| [13] | 邹福泰, 谭越, 王林, 蒋永康. 基于生成对抗网络的僵尸网络检测[J]. 通信学报, 2021, 42(7): 95-106. |
| [14] | 王洪雁, 杨晓, 姜艳超, 汪祖民. 基于多通道GAN的图像去噪算法[J]. 通信学报, 2021, 42(3): 229-237. |
| [15] | 何遵文, 侯帅, 张万成, 张焱. 通信特定辐射源识别的多特征融合分类方法[J]. 通信学报, 2021, 42(2): 103-112. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||