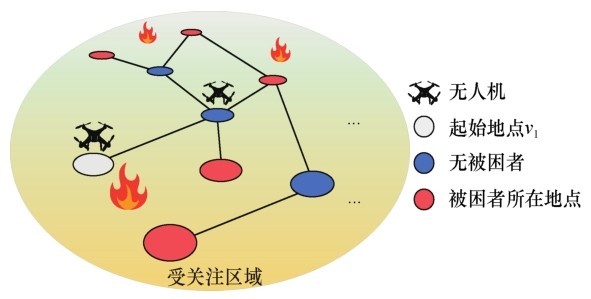
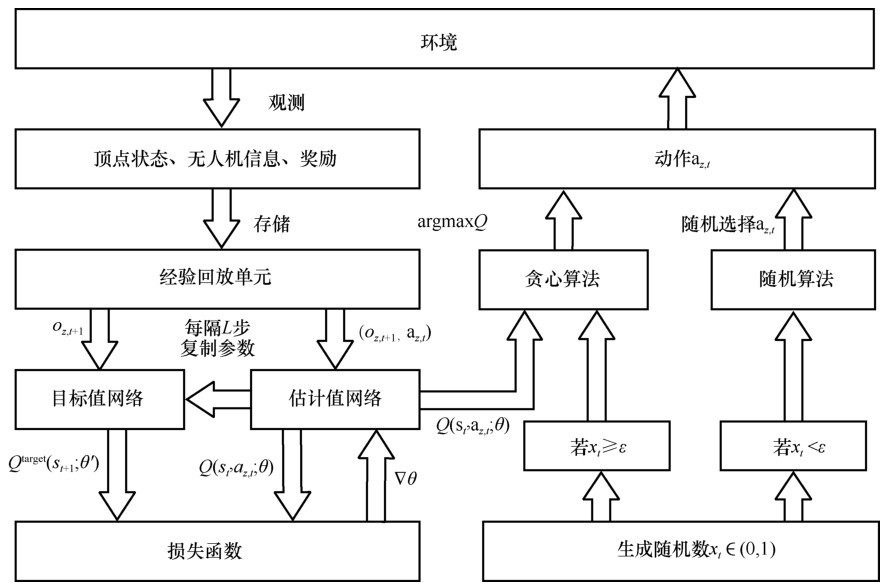
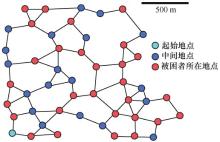
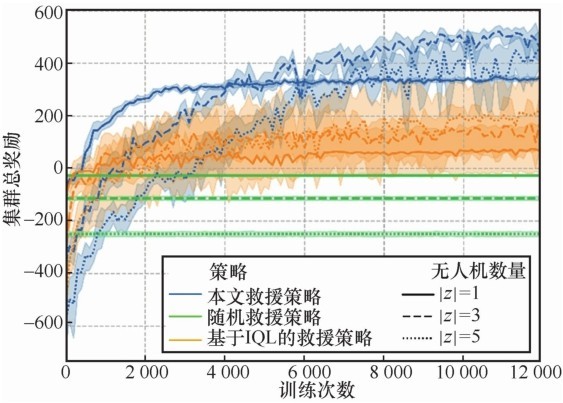
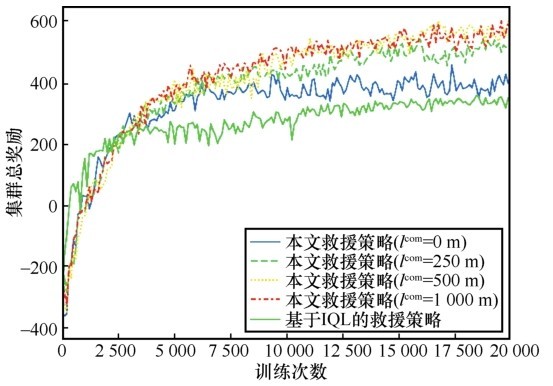
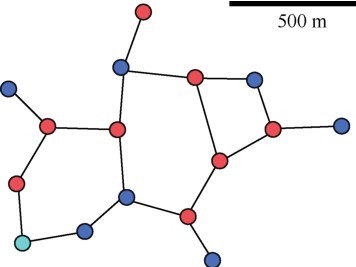
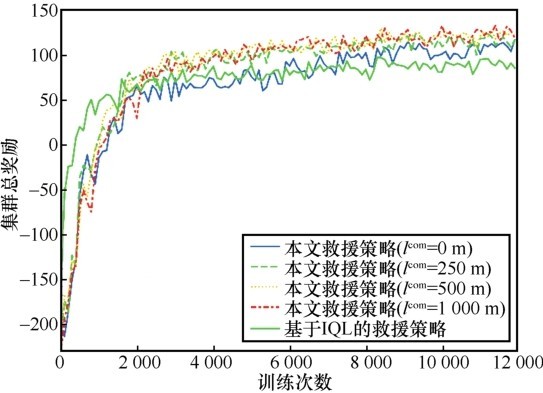
| [1] |
韩亮, 任章, 董希旺 ,等. 多无人机协同控制方法及应用研究[J]. 导航定位与授时, 2018,5(4): 1-7.
|
|
HAN L , REN Z , DONG X W ,et al. Research on cooperative control method and application for multiple unmanned aerial vehicles[J]. Navigation Positioning and Timing, 2018,5(4): 1-7.
|
| [2] |
HILDMANN H , KOVACS E . Review,using unmanned aerial vehicles (UAVs) as mobile sensing platforms (MSPs) for disaster response,civil security and public safety[J]. Drones, 2019,3(3): 59.
|
| [3] |
FAN B K , LI Y , ZHANG R Y ,et al. Review on the technological development and application of UAV systems[J]. Chinese Journal of Electronics, 2020,29(2): 199-207.
|
| [4] |
CAMPION M , RANGANATHAN P , FARUQUE S . UAV swarm communication and control architectures,a review[J]. Journal of Unmanned Vehicle Systems, 2019,7(2): 93-106.
|
| [5] |
ZHOU Y K , RAO B , WANG W . UAV swarm intelligence,recent advances and future trends[J]. IEEE Access, 8: 183856-183878.
|
| [6] |
BACCO M , CHESSA S , BENEDETTO M ,et al. UAVs and UAV swarms for civilian applications,communications and image processing in the SCIADRO project[C]// Wireless and Satellite Systems, 2018: 115-124.
|
| [7] |
RUETTEN L , REGIS P A , FEIL-SEIFER D ,et al. Area-optimized UAV swarm network for search and rescue operations[C]// Proceedings of 2020 10th Annual Computing and Communication Workshop and Conference (CCWC). Piscataway,IEEE Press, 2020: 613-618.
|
| [8] |
MATESE A , TOSCANO P , DI GENNARO S ,et al. Intercomparison of UAV,aircraft and satellite remote sensing platforms for precision viticulture[J]. Remote Sensing, 2015,7(3): 2971-2990.
|
| [9] |
KIM K S , KIM H Y , CHOI H L . A bid-based grouping method for communication-efficient decentralized multi-UAV task allocation[J]. International Journal of Aeronautical and Space Sciences, 2020,21(1): 290-302.
|
| [10] |
LADOSZ P , OH H , ZHENG G ,et al. Gaussian process based channel prediction for communication-relay UAV in urban environments[J]. IEEE Transactions on Aerospace and Electronic Systems, 2020,56(1): 313-325.
|
| [11] |
宗群, 王丹丹, 邵士凯 ,等. 多无人机协同编队飞行控制研究现状及发展[J]. 哈尔滨工业大学学报, 2017,49(3): 1-14.
|
|
ZONG Q , WANG D D , SHAO S K ,et al. Research status and development of multi UAV coordinated formation flight control[J]. Journal of Harbin Institute of Technology, 2017,49(3): 1-14.
|
| [12] |
张可为, 赵晓林, 李宗哲 ,等. 多无人机侦察任务分配方法研究综述[J]. 电光与控制, 2021,28(7): 68-72,82.
|
|
ZHANG K W , ZHAO X L , LI Z Z ,et al. A review of multi-UAV reconnaissance mission assignment methods[J]. Electronics Optics &Control, 2021,28(7): 68-72,82.
|
| [13] |
陈少飞 . 无人机集群系统侦察监视任务规划方法[D]. 长沙,国防科学技术大学, 2016.
|
|
CHEN S F . Planning for reconnaissance and monitoring using UAV swarms[D]. Changsha,National University of Defense Technology, 2016.
|
| [14] |
ZHAO J W , ZHAO J J . Study on multi-UAV task clustering and task planning in cooperative reconnaissance[C]// Proceedings of 2014 Sixth International Conference on Intelligent Human-Machine Systems and Cybernetics. Piscataway,IEEE Press, 2014: 392-395.
|
| [15] |
黄捷, 陈谋, 姜长生 . 无人机空对地多目标攻击的满意分配决策技术[J]. 电光与控制, 2014,21(7): 10-13,30.
|
|
HUANG J , CHEN M , JIANG C S . Satisficing decision-making on task allocation for UAVs in air-to-ground attacking[J]. Electronics Optics & Control, 2014,21(7): 10-13,30.
|
| [16] |
SU C X , YE F , WANG L C ,et al. UAV-assisted wireless charging for energy-constrained IoT devices using dynamic matching[J]. IEEE Internet of Things Journal, 2020,7(6): 4789-4800.
|
| [17] |
ABEDIN S F , MUNIR M S , TRAN N H ,et al. Data freshness and energy-efficient UAV navigation optimization,a deep reinforcement learning approach[J]. IEEE Transactions on Intelligent Transportation Systems, 2021,22(9): 5994-6006.
|
| [18] |
WHITBROOK A , MENG Q G , CHUNG P W H . Reliable,distributed scheduling and rescheduling for time-critical,multiagent systems[J]. IEEE Transactions on Automation Science and Engineering, 2018,15(2): 732-747.
|
| [19] |
杜永浩, 邢立宁, 蔡昭权 . 无人飞行器集群智能调度技术综述[J]. 自动化学报, 2020,46(2): 222-241.
|
|
DU Y H , XING L N , CAI Z Q . Survey on intelligent scheduling technologies for unmanned flying craft clusters[J]. Acta Automatica Sinica, 2020,46(2): 222-241.
|
| [20] |
BALDAZO D , PARRAS J , ZAZO S . Decentralized multi-agent deep reinforcement learning in swarms of drones for flood monitoring[C]// Proceedings of 2019 27th European Signal Processing Conference (EUSIPCO). Piscataway,IEEE Press, 2019: 1-5.
|
| [21] |
左益宏, 柳长安, 罗昌行 ,等. 多无人机监控航路规划[J]. 飞行力学, 2004,22(3): 31-34.
|
|
ZUO Y H , LIU C G , LUO C X ,et al. Path planning for surveillance of multiple unmanned air vehicles[J]. Flight Dynamics, 2004,22(3): 31-34.
|
| [22] |
WU H S , LI H , XIAO R B ,et al. Modeling and simulation of dynamic ant colony's labor division for task allocation of UAV swarm[J]. Physica A,Statistical Mechanics and Its Applications, 2018,491: 127-141.
|
| [23] |
成成, 张跃, 储海荣 ,等. 分布式多无人机协同编队队形控制仿真[J]. 计算机仿真, 2019,36(5): 31-37.
|
|
CHENG C , ZHANG Y , CHU H R ,et al. Simulation of distributed cooperative formation control for multi-UAVs[J]. Computer Simulation, 2019,36(5): 31-37.
|
| [24] |
ZHAO Y Y , WANG X K , WANG C ,et al. Systemic design of distributed multi-UAV cooperative decision-making for multi-target tracking[J]. Autonomous Agents and Multi-Agent Systems, 2019,33(1/2): 132-158.
|
| [25] |
FU X W , PAN J , WANG H X ,et al. A formation maintenance and reconstruction method of UAV swarm based on distributed control[J]. Aerospace Science and Technology, 2020,104,105981.
|
| [26] |
SAMVELYAN M , RASHID T , DE WITT C S ,et al. The StarCraft multi-agent challenge[C]// Proceedings of AAMAS '19,Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems. 2019: 2186-2188.
|
| [27] |
MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533.
|
| [28] |
KRAEMER L , BANERJEE B . Multi-agent reinforcement learning as a rehearsal for decentralized planning[J]. Neurocomputing, 2016,190: 82-94.
|
| [29] |
WANG Z , SCHAUL T , HESSEL M ,et al. Dueling network architectures for deep reinforcement learning[C]// International Conference on Machine Learning. PMLR, 2016: 1995-2003.
|
| [30] |
TAMPUU A , MATIISEN T , KODELJA D ,et al. Multiagent cooperation and competition with deep reinforcement learning[J]. PLoS One, 2017,12(4): e0172395.
|