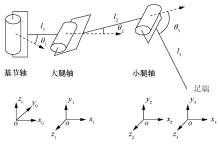
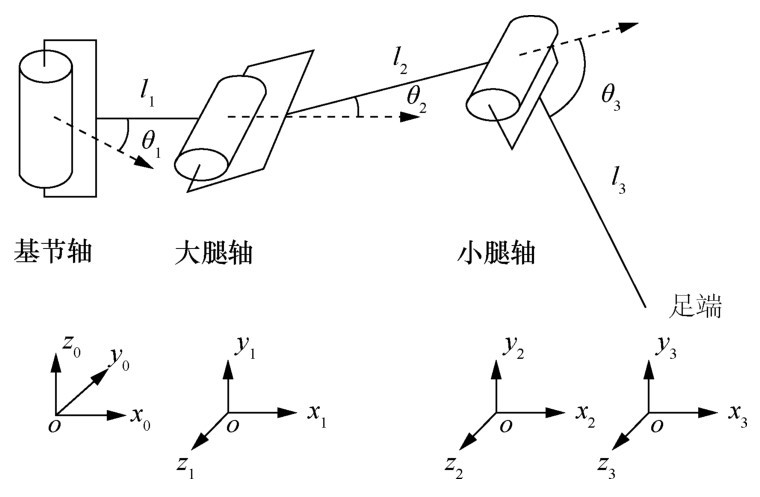
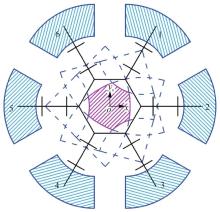
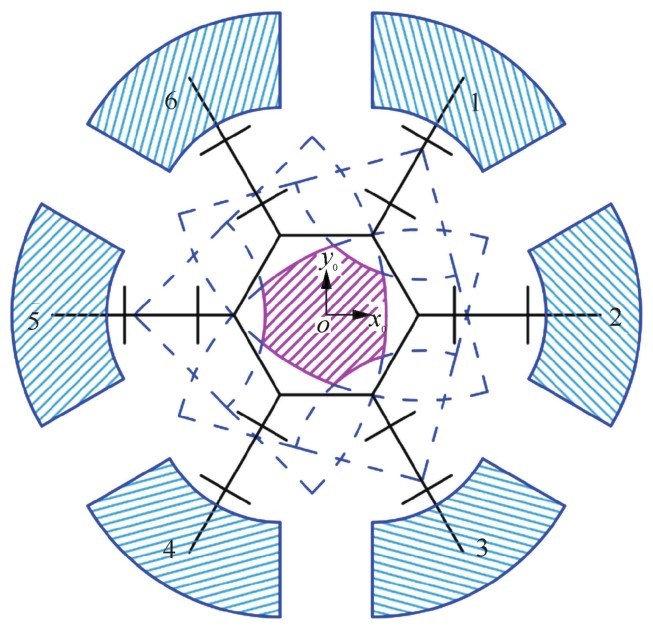
| [10] |
BU X J . Research on robot path planning under unknown environment based on deep reinforcement learning[D]. Harbin:Harbin Institute of Technology, 2018.
|
| [11] |
孙长银, 穆朝絮 . 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020(7): 1301-1312.
|
|
SUN C Y , MU C X . Important scientific problems of multi-agent deep reinforcement learning[J]. Acta Automatica Sinica, 2020(7): 1301-1312.
|
| [12] |
GARIBALDI JONATHAN M, 陈虹宇, 李小双 . 差异与学习:模糊系统与模糊推理[J]. 智能科学与技术学报, 2019,1(4): 319-326.
|
|
GARIBALDI JONATHAN M , CHEN H Y , LI X S . Variation and learning:fuzzy system and fuzzy inference[J]. Chinese Journal of Intelligent Science and Technology, 2019,1(4): 319-326.
|
| [13] |
陈德旺, 蔡际杰, 黄允浒 . 面向可解释性人工智能与大数据的模糊系统发展展望[J]. 智能科学与技术学报, 2019,1(4): 327-334.
|
|
CHEN D W , CAI J J , HUANG Y H . Development prospect of fuzzy system oriented to interpretable artificial intelligence and big data[J]. Chinese Journal of Intelligent Science and Technology, 2019,1(4): 327-334.
|
| [14] |
WANG Z , CHEN C L , LI H X ,et al. Incremental reinforcement learning with prioritized sweeping for dynamic environments[J]. IEEE/ASME Transactions on Mechatronics, 2019,24(2): 621-632.
|
| [15] |
TSOUNIS V , ALGE M , LEE J ,et al. Deepgait:planning and control of quadrupedal gaits using deep reinforcement learning[J]. IEEE Robotics and Automation Letters, 2020,5(2): 3699-3706.
|
| [16] |
SHAHRIARI M , KHAYYAT A A . Gait analysis of a six-legged walking robot using fuzzy reward reinforcement learning[C]// IEEE 13th Iranian Conference on Fuzzy Systems. Piscataway:IEEE Press, 2013: 1-4.
|
| [17] |
唐开强 . 基于迁移强化学习的六足机器人步态学习研究[D]. 南京:南京大学, 2019.
|
|
TANG K Q . Research on gait learning of hexapod robot based on transfer reinforcement learning[D]. Nanjing:Nanjing University, 2019.
|
| [18] |
HOU Y N , LIU L F , WEI Q ,et al. A novel DDPG method with prioritized experience replay[C]// 2017 IEEE International Conference on Systems,Man,and Cybernetics. Piscataway:IEEE Press, 2017: 316-321.
|
| [19] |
REN Z P , DONG D Y , LI H X ,et al. Self-paced prioritized curriculum learning with coverage penalty in deep reinforcement learning[J]. IEEE Transactions on Neural Networks and Learning Systems, 2018,29(6): 2216-2226.
|
| [20] |
SHI W J , SONG S J , WU H ,et al. Regularizedanderson acceleration for off-policy deep reinforcement learning[J]. arXiv preprint, 2019,arXiv:1909. 03245.
|
| [21] |
TING L H , BLICKHAN R , FULL R J . Dynamic and static stability in hexapedal runners[J]. Journal of Experimental Biology, 1994,197(1): 251-269.
|
| [1] |
李满宏, 张明路, 张建华 ,等. 六足机器人关键技术综述[J]. 机械设计, 2015,32(10): 1-8.
|
|
LI M H , ZHANG M L , ZHANG J H ,et al. Review on key technology of the hexapod robot[J]. Journal of Machine Design, 2015,32(10): 1-8.
|
| [22] |
SUTTON R , BARTO A . Reinforcement learning:an introduction[M]. Cambridge: MIT Press, 1998.
|
| [23] |
WATKINS C . Learning from delayed rewards[J]. PhD thesis,University of Cambridge, 1989.
|
| [2] |
STELZER A , HIRSCHMüLLER H , G?RNER M . Stereo-visionbased navigation of a six-legged walking robot in unknown rough terrain[J]. The International Journal of Robotics Research, 2012,31(4): 381-402.
|
| [3] |
HOMBERGER T , BJELONIC M , KOTTEGE N ,et al. Terrain-dependant control of hexapod robots using vision[M]// International Symposium on Experimental Robotics. Cham: Springer, 2016: 92-102.
|
| [24] |
SILVER D , LEVER G , HEESS N ,et al. Deterministic policy gradient algorithms[C]// The 31st International Conference on Machine Learning. New York:ACM Press, 2014: 387-395.
|
| [25] |
IOFFE S , SZEGEDY C . Batch normalization:accelerating deep network training by reducing internal covariate shift[C]// Proceedings of Machine Learning Research.[S.l.:s.n.], 2015,37 448-456.
|
| [4] |
胡勇 . 六足机器人梅花桩行走步态研究[D]. 绵阳:西南科技大学, 2019.
|
|
HU Y . Study on gait of hexapod robot walking on plum pile[D]. Mianyang:Southwest University of Science and Technology, 2019.
|
| [26] |
LILLICRAP T P , HUNT J J , PRITZEL A ,et al. Continuous control with deep reinforcement learning[J]. arXiv preprint, 2015,arXiv:1509. 02971.
|
| [27] |
SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[J]. arXiv preprint, 2015,arXiv:1511. 05952.
|
| [5] |
?í?EK P , MASRI D , FAIGL J . Foothold placement planning with a hexapod crawling robot[C]// 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2017: 4096-4101.
|
| [6] |
MOSTAFA K , CHIANG J Y , WEI K T ,et al. Image-based method for determining better walking strategies for hexapods[J]. International Journal of Advanced Robotic Systems, 2015,12(5): 58.
|
| [7] |
沈宇, 韩金朋, 李灵犀 ,等. 游戏智能中的 AI——从多角色博弈到平行博弈[J]. 智能科学与技术学报, 2020,2(3): 205-213.
|
|
SHEN Y , HAN J P , LI L X ,et al. AI in game intelligence—from multi-role game to parallel game[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(3): 205-213.
|
| [8] |
王飞跃, 曹东璞, 魏庆来 . 强化学习:迈向知行合一的智能机制与算法[J]. 智能科学与技术学报, 2020,2(2): 101-106.
|
|
WANG F Y , CAO D P , WEI Q L . Reinforcement learning:toward action-knowledge merged intelligent mechanisms and algorithms[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(2): 101-106.
|
| [9] |
刘全, 翟建伟, 章宗长 ,等. 深度强化学习综述[J]. 计算机学报, 2018,41(1): 1-27.
|
|
LIU Q , ZHAI J W , ZHANG Z Z ,et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018,41(1): 1-27.
|
| [10] |
卜祥津 . 基于深度强化学习的未知环境下机器人路径规划的研究[D]. 哈尔滨:哈尔滨工业大学, 2018.
|
| [28] |
MAHMOOD A R , HASSELT H P , SUTTON R S . Weighted importance sampling for off-policy learning with linear function approximation[C]// Conference and Workshop on Neural Information Processing Systems. New York:ACM Press, 2014: 3014-3022.
|