


智能科学与技术学报 ›› 2020, Vol. 2 ›› Issue (4): 314-326.doi: 10.11959/j.issn.2096-6652.202034
刘朝阳1, 穆朝絮1, 孙长银2
修回日期:2020-12-03
出版日期:2020-12-15
发布日期:2020-12-01
作者简介:刘朝阳(1996- ),男,天津大学电气自动化与信息工程学院博士生,主要研究方向为强化学习、多智能体强化学习。基金资助:Zhaoyang LIU1, Chaoxu MU1, Changyin SUN2
Revised:2020-12-03
Online:2020-12-15
Published:2020-12-01
Supported by:摘要:
深度强化学习主要被用来处理感知-决策问题,已经成为人工智能领域重要的研究分支。概述了基于值函数和策略梯度的两类深度强化学习算法,详细阐述了深度Q网络、深度策略梯度及相关改进算法的原理,并综述了深度强化学习在视频游戏、导航、多智能体协作以及推荐系统等领域的应用研究进展。最后,对深度强化学习的算法和应用进行展望,针对一些未来的研究方向和研究热点给出了建议。
中图分类号:
刘朝阳,穆朝絮,孙长银. 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020, 2(4): 314-326.
Zhaoyang LIU,Chaoxu MU,Changyin SUN. An overview on algorithms and applications of deep reinforcement learning[J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 314-326.
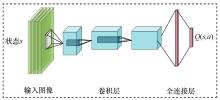
图1
DQN的网络结构"
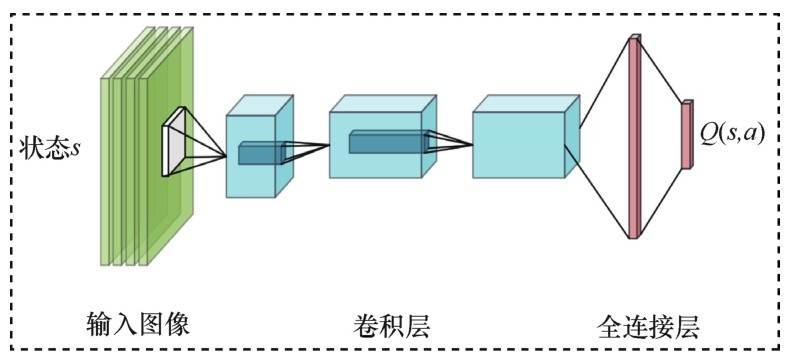
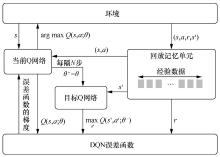
图2
DQN算法更新流程"
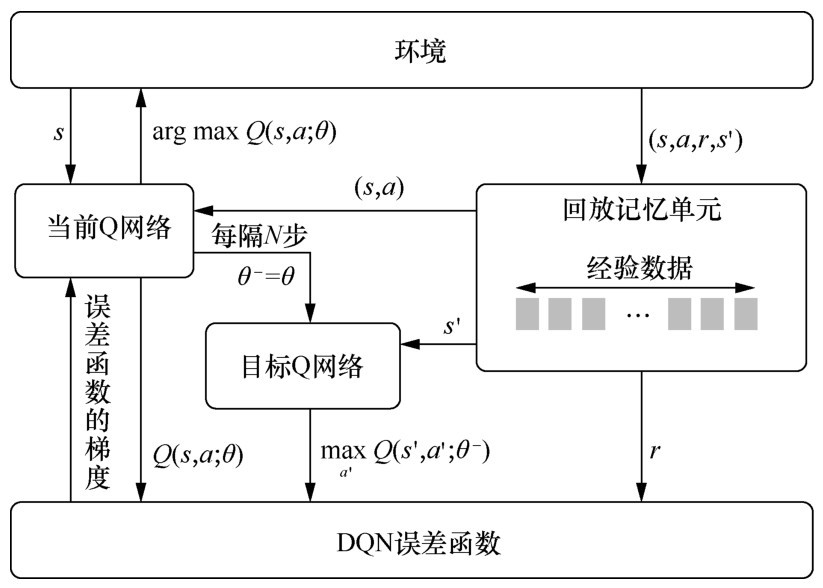
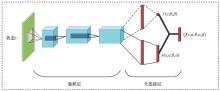
图3
Dueling DQN的网络结构"

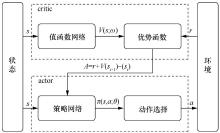
图4
A2C的基本结构"

表1
几类DRL的应用领域及研究意义"
| 应用领域 | 分类方式 | 参考文献 | 研究意义 |
| 视频游戏 | Atari 2600 | [5,14-17,24] | 将DRL应用在多种游戏环境中,提升DRL算法的通用性 |
| ViZDoom、StarCraftII等 | [25-34] | 将DRL应用到复杂的游戏场景中,提升智能体的决策能力 | |
| 导航 | 迷宫导航 | [35-40] | 根据应用场景设计迷宫环境,采用DRL处理特定的导航问题 |
| 室内导航 | [41-45] | 采用 DRL 算法训练智能体在室内环境进行导航,并尝试将虚拟环境中训练好的智能体应用到现实环境中 | |
| 街景导航 | [46-49] | 采用DRL处理城市与城市之间的长距离导航,并提升DRL算法的泛化能力 | |
| 多智能体协作 | 独立学习者协作 | [50-53, | 协作智能体在训练时使用独立DRL的方式,方便进行数量上的扩展 |
| 集中式评价器协作 | [60-64] | 协作智能体在训练时通过集中式的评价器获取其他智能体的信息,解决环境非静态问题 | |
| 通信协作 | [65-69] | 利用 DRL 处理多智能体之间可以通信的情况,并采用通信促进智能体之间的协作 | |
| 推荐系统 | 推荐算法 | [70-73] | 利用 DRL 进行推荐可以实时地对推荐策略进行调整,从而满足用户的动态偏好,并且推荐算法能够得到长期的回报 |

图5
Atari 2600典型游戏环境"


图6
DRL导航环境"
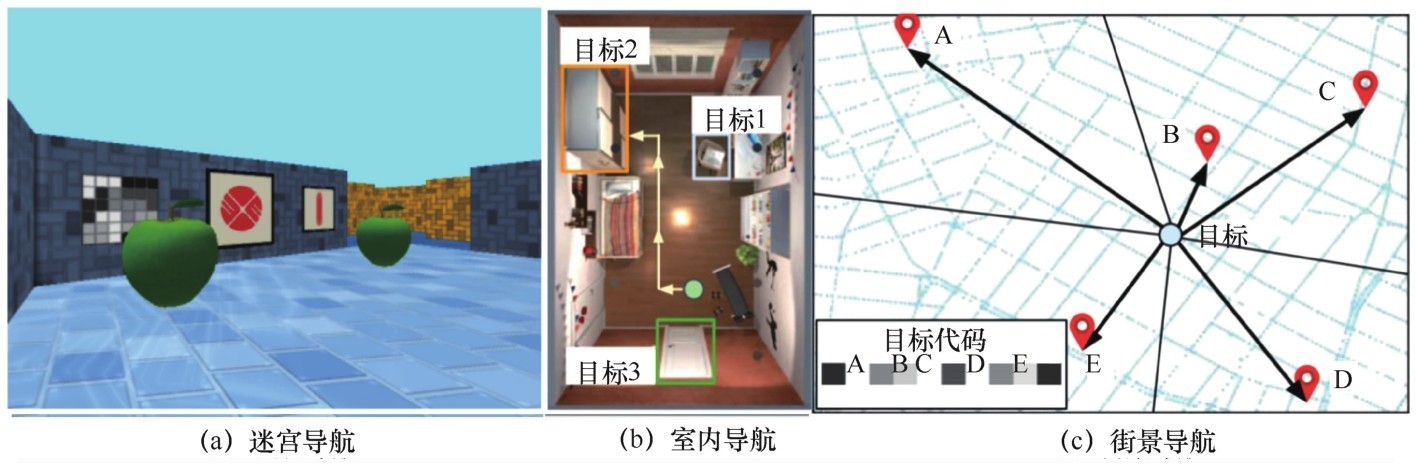
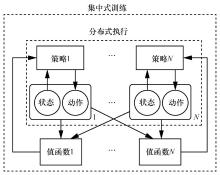
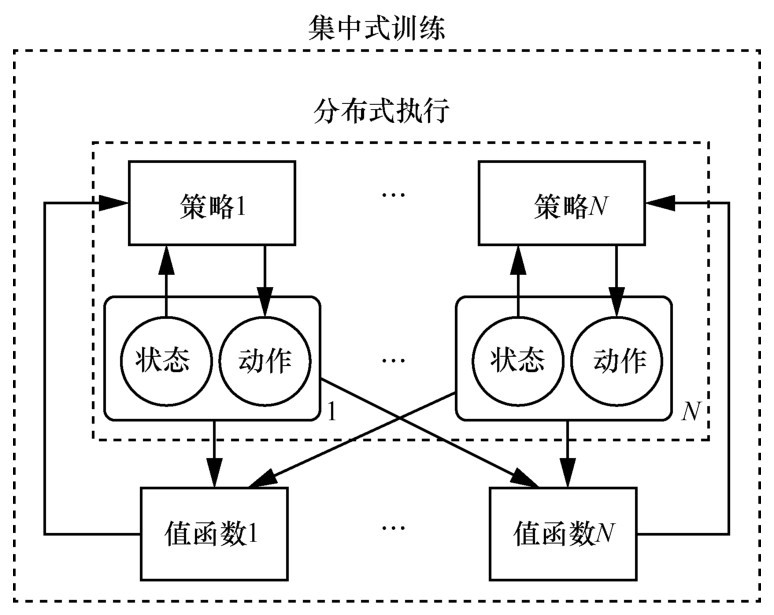
图7
MADDPG算法结构"
| [1] | SUTTON R S , BARTO A G . Reinforcement learning:an introduction[M]. Cambridge: MIT Press, 2018. |
| [2] | LECUN Y , BENGIO Y , HINTON G . Deep learning[J]. Nature, 2015,521(7553): 436-444. |
| [3] | 赵冬斌, 邵坤, 朱圆恒 ,等. 深度强化学习综述:兼论计算机围棋的发展[J]. 控制理论与应用, 2016,33(6): 701-717. |
| ZHAO D B , SHAO K , ZHU Y H ,et al. Review of deep reinforcement learning and discussions on the development of computer Go[J]. Control Theory & Applications, 2016,33(6): 701-717. | |
| [4] | 万里鹏, 兰旭光, 张翰博 ,等. 深度强化学习理论及其应用综述[J]. 模式识别与人工智能, 2019,32(1): 67-81. |
| WAN L P , LAN X G , ZHANG H B ,et al. A review of deep reinforcement learning theory and application[J]. Pattern Recognition and Artificial Intelligence, 2019,32(1): 67-81. | |
| [5] | MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533. |
| [6] | SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016,529(7587): 484-489. |
| [7] | SILVER D , SCHRITTWIESER J , SIMONYAN K ,et al. Mastering the game of go without human knowledge[J]. Nature, 2017,550(7676): 354-359. |
| [8] | BERNER C , BROCKMAN G , CHAN B ,et al. Dota2 with large scale deep reinforcement learning[J]. arXiv preprint, 2019,arXiv:1912. 06680. |
| [9] | VINYALS O , BABUSCHKIN I , CZARNECKI W M ,et al. Grandmaster level in StarCraftII using multi-agent reinforcement learning[J]. Nature, 2019,575(7782): 350-354. |
| [10] | 刘全, 翟建伟, 章宗长 ,等. 深度强化学习综述[J]. 计算机学报, 2018,41(1): 1-27. |
| LIU Q , ZHAI J W , ZHANG Z Z ,et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018,41(1): 1-27. | |
| [11] | 刘建伟, 高峰, 罗雄麟 . 基于值函数和策略梯度的深度强化学习综述[J]. 计算机学报, 2019,42(6): 1406-1438. |
| LIU J W , GAO F , LUO X L . Survey of deep reinforcement learning based on value function and policy gradient[J]. Chinese Journal of Computers, 2019,42(6): 1406-1438. | |
| [12] | SUTTON R S . Learning to predict by the methods of temporal differences[J]. Machine Learning, 1988,3(1): 9-44. |
| [13] | WATKINS C J C H , DAYAN P . Q-learning[J]. Machine Learning, 1992,8(3-4): 279-292. |
| [14] | VAN HASSELT H , GUEZ A , SILVER D ,et al. Deep reinforcement learning with double Q-learning[C]// The 30th AAAI Conference on Artificial Intelligence.[S.l.:s.n.], 2016. |
| [15] | SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[C]// The 4th International Conference on Learning Representations.[S.l.:s.n.], 2016. |
| [16] | WANG Z , SCHAUL T , HESSEL M ,et al. Dueling network architectures for deep reinforcement learning[C]// The 33rd International Conference on Machine Learning. New York:ACM Press, 2016. |
| [17] | NAIR A , SRINIVASAN P , BLACKWELL S ,et al. Massively parallel methods for deep reinforcement learning[J]. arXiv preprint, 2015,arXiv:1507. 04296 |
| [18] | SLIVER D , LEVER G , HEESS N ,et al. Deterministic policy gradient algorithms[C]// The 31st International Conference on Machine Learning. New York:ACM Press, 2014. |
| [19] | LILLICRAP P T , HUNT J J , PRITZEL A ,et al. Continuous control with deep reinforcement learning[C]// The 4th International Conference on Learning Representations.[S.l.:s.n.], 2016. |
| [20] | MNIH V , BADIA A P , MIRZA M ,et al. Asynchronous methods for deep reinforcement learning[C]// The 33rd International Conference on Machine Learning. New York:ACM Press, 2016. |
| [21] | SCHULMAN J , WOLSKI F , DHARIWAL P ,et al. Proximal policy optimization algorithms[J]. arXiv preprint, 2017,arXiv:1707. 06347. |
| [22] | HAARNOJA T , ZHOU A , ABBEEL P ,et al. Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[J]. arXiv preprint, 2018,arXiv:1801. 01290. |
| [23] | 沈宇, 韩金朋, 李灵犀 ,等. 游戏智能中的 AI——从多角色博弈到平行博弈[J]. 智能科学与技术学报, 2020,2(3): 205-213. |
| SHEN Y , HAN J P , LI L X ,et al. AI in game intelligence—from multi-role game to parallel game[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(3): 205-213. | |
| [24] | BADIA A P , PIOT B , KAPTUROWSKI S ,et al. Agent57:outperforming the atari human benchmark[J]. arXiv preprint, 2020,arXiv:2003. 13350. |
| [25] | KEMPKA M , WYDMUCH M , RUNC G ,et al. Vizdoom:a doom-based AI research platform for visual reinforcement learning[C]// 2016 IEEE Conference on Computational Intelligence and Games (CIG). Piscataway:IEEE Press, 2016: 1-8. |
| [26] | LAMPLE G , CHAPLOT D S . Playing FPS games with deep reinforcement learning[C]// The 31st AAAI Conference on Artificial Intelligence.[S.l.:s.n.], 2017. |
| [27] | DOSOVITSKIY A , KOLTUN V . Learning to act by predicting the future[J]. arXiv preprint, 2016,arXiv:1611. 01779. |
| [28] | PATHAK D , AGRAWAL P , EFROS A A ,et al. Curiosity-driven exploration by self-supervised prediction[C]// The 34th International Conference on Machine Learning. New York:ACM Press, 2017. |
| [29] | WU Y , ZHANG W , SONG K . Master-slave curriculum design for reinforcement learning[C]// The 28th International Joint Conference on Artificial Intelligence. New York:ACM Press, 2018: 1523-1529. |
| [30] | VINYALS O , EWALDS T , BARTUNOV S ,et al. StarcraftII:a new challenge for reinforcement learning[J]. arXiv preprint, 2017,arXiv:1708. 04782. |
| [31] | ZAMBALDI V , RAPOSO D , SANTORO A ,et al. Relational deep reinforcement learning[J]. arXiv preprint, 2018,arXiv:1806. 01830. |
| [32] | VASWANI A , SHAZEER N , PARMAR N ,et al. Attention is all you need[C]// Advances in Neural Information Processing Systems. New York:ACM Press, 2017: 5998-6008. |
| [33] | RASHID T , SAMVELYAN M , DE WITT C S ,et al. QMIX:monotonic value function factorisation for deep multi-agent reinforcement learning[J]. arXiv preprint, 2018,arXiv:1803. 11485. |
| [34] | YE D , LIU Z , SUN M ,et al. Mastering complex control in MOBA games with deep reinforcement learning[C]// The 34th AAAI Conference on Artificial Intelligence.[S.l.:s.n.], 2020: 6672-6679. |
| [35] | OH J , CHOCKALINGAM V , SINGH S ,et al. Control of memory,active perception,and action in minecraft[C]// The 33rd International Conference on Machine Learning. New York:ACM Press, 2016. |
| [36] | JADERBERG M , MNIH V , CZARNECKI W M ,et al. Reinforcement learning with unsupervised auxiliary tasks[J]. arXiv preprint, 2016,arXiv:1611. 05397. |
| [37] | MIROWSKI P , PASCANU R , VIOLA F ,et al. Learning to navigate in complex environments[J]. arXiv preprint, 2016,arXiv:1611. 03673. |
| [38] | WANG Y , HE H , SUN C . Learning to navigate through complex dynamic environment with modular deep reinforcement learning[J]. IEEE Transactions on Games, 2018,10(4): 400-412. |
| [39] | SHI H , SHI L , XU M ,et al. End-to-end navigation strategy with deep reinforcement learning for mobile robots[J]. IEEE Transactions on Industrial Informatics, 2020,16(4): 2393-2402. |
| [40] | SAVINOV N , RAICHUK A , MARINIER R ,et al. Episodic curiosity through reachability[C]// The 7th International Conference on Learning Representations.[S.l.:s.n.], 2019. |
| [41] | ZHU Y , MOTTAGHI R , KOLVE E ,et al. Target-driven visual navigation in indoor scenes using deep reinforcement learning[C]// 2017 IEEE international conference on robotics and automation (ICRA). Piscataway:IEEE Press, 2017: 3357-3364. |
| [42] | TAI L , LIU M . Towards cognitive exploration through deep reinforcement learning for mobile robots[J]. arXiv preprint, 2016,arXiv:1610. 01733. |
| [43] | TAI L , PAOLO G , LIU M . Virtual-to-real deep reinforcement learning:continuous control of mobile robots for mapless navigation[C]// 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway:IEEE Press, 2017: 31-36. |
| [44] | WU Y , RAO Z , ZHANG W ,et al. Exploring the task cooperation in multi-goal visual navigation[C]// The 28th International Joint Conference on Artificial Intelligence.[S.l.:s.n.], 2019: 609-615. |
| [45] | ZHANG W , ZHANG Y , LIU N . Map-less navigation:a single DRL-based controller for robots with varied dimensions[J]. arXiv preprint, 2020,arXiv:2002. 06320. |
| [46] | MIROWSKI P , GRIMES M K , MALINOWSKI M ,et al. Learning to navigate in cities without a map[C]// Advances in Neural Information Processing Systems.[S.l.:s.n.], 2018: 2419-2430. |
| [47] | LI A , HU H , MIROWSKI P ,et al. Cross-view policy learning for street navigation[C]// The IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2019: 8100-8109. |
| [48] | HERMANN K M , MALINOWSKI M , MIROWSKI P ,et al. Learning to follow directions in street view[C]// The 34th AAAI Conference on Artificial Intelligence.[S.l.:s.n.], 2020. |
| [49] | CHANCá N M , MILFORD M . CityLearn:diverse real-world environments for sample-efficient navigation policy learning[J]. arXiv preprint, 2020,arXiv:1910. 04335. |
| [50] | 孙长银, 穆朝絮 . 多智能体深度强化学习的若干关键科学问题[J]. 自动化学报, 2020,46(7): 1301-1312. |
| SUN C Y , MU C X . Important scientific problems of multi-agentdeep reinforcement learning[J]. Acta Automatica Sinica, 2020,46(7): 1301-1312. | |
| [51] | OROOJLOOYJADID A , HAJINEZHAD D . A review of cooperative multi-agent deep reinforcement learning[J]. arXiv preprint, 2019,arXiv:1908. 03963. |
| [52] | OMIDSHAFIEI S , PAZIS J , AMATO C ,et al. Deep decentralized multi-task multi-agent reinforcement learning under partial observability[C]// The 34th International Conference on Machine Learning. New York:ACM Press, 2017. |
| [53] | MATIGNON L , LAURENT G J , LE FORT-PIAT N . Hysteretic Q-learning:an algorithm for decentralized reinforcement learning in cooperative multi-agent teams[C]// 2007 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2007: 64-69. |
| [54] | FOERSTER J , NARDELLI N , FARQUHAR G ,et al. Stabilising experience replay for deep multi-agent reinforcement learning[C]// The 34th International Conference on Machine Learning. New York:ACM Press, 2017. |
| [55] | PALMER G , TUYLS K , BLOEMBERGEN D ,et al. Lenient multi-agent deep reinforcement learning[C]// The 17th International Conference on Autonomous agents and Multiagent Systems. New York:ACM Press, 2018. |
| [56] | EVERETT R , ROBERTS S . Learning against non-stationary agents with opponent modelling and deep reinforcement learning[C]// 2018 AAAI Spring Symposium Series.[S.l.:s.n.], 2018. |
| [57] | JIN Y , WEI S , YUAN J ,et al. Stabilizing multi-agent deep reinforcement learning by implicitly estimating other agents’ behaviors[C]// 2020 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2020: 3547-3551. |
| [58] | LIU X , TAN Y . Attentive relational state representation in decentralized multiagent reinforcement learning[J]. IEEE Transactions on Cybernetics, 2020. |
| [59] | GUPTA J K , EGOROV M , KOCHENDERFER M . Cooperative multi-agent control using deep reinforcement learning[C]// The 16th International Conference on Autonomous Agents and Multiagent Systems. Cham:Springer, 2017: 66-83. |
| [60] | LOWE R , WU Y , TAMAR A ,et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]// Advances in Neural Information Processing Systems. New York:ACM Press, 2017: 6379-6390. |
| [61] | FOERSTER J , FARQUHAR G , AFOURAS T ,et al. Counterfactual multi-agent policy gradients[C]// The 32nd AAAI Conferenceon Artificial Intelligence.[S.l.:s.n.], 2018. |
| [62] | SUNEHAG P , LEVER G , GRUSLYS A ,et al. Value-decomposition networks for cooperative multi-agent learning[J]. arXiv preprint, 2011,arXiv:1706. 05296. |
| [63] | MAO H , ZHANG Z , XIAO Z ,et al. Modelling the dynamic joint policy of teammates with attention multi-agent DDPG[C]// The 18th International Conference on Autonomous Agentsand Multiagent Systems. New York:ACM Press, 2019. |
| [64] | IQBAL S , SHA F . Actor-attention-critic for multi-agent reinforcement learning[C]// International Conference on Machine Learning.[S.l.:s.n.], 2019: 2961-2970. |
| [65] | FOERSTER J N , ASSAEL Y M , DE FREITAS N ,et al. Learning to communicate with deep multi-agent reinforcement learning[C]// Advances in Neural Information Processing Systems. New York:ACM Press, 2016: 2137-2145. |
| [66] | SUKHBAATAR S , SZLAM A , FERGUS R . Learning multiagent communication with back propagation[C]// Advances in Neural Information Processing Systems. New York:ACM Press, 2016: 2244-2252. |
| [67] | JIANG J , LU Z . Learning attentional communication for multi-agent cooperation[C]// Advances in Neural Information Processing Systems. New York:ACM Press, 2018: 7254-7264. |
| [68] | KIM D , MOON S , HOSTALLERO D ,et al. Learning to schedule communication in multi-agent reinforcement learning[C]// The 7th International Conference on Learning Representations.[S.l.:s.n.], 2019. |
| [69] | DAS A , GERVET T , ROMOFF J ,et al. TarMAC:targeted multi-agent communication[C]// The 36th International Conference on MachineLearning.[S.l.:s.n.], 2019. |
| [70] | SHANI G , HECKERMAN D , BRAFMAN R I ,et al. An MDP-based recommender system[J]. Journal of Machine Learning Research, 2005,6(Sep): 1265-1295. |
| [71] | ZHAO X , XIA L , TANG J ,et al. Deep reinforcement learning for search,recommendation,and online advertising:a survey[J]. ACM SIGWEB Newsletter, 2019(Spring): 1-15. |
| [72] | ZHAO X , XIA L , ZHANG L ,et al. Deep reinforcement learning for page-wise recommendations[C]// The 12th ACM Conference on Recommender Systems. New York:ACM Press, 2018: 95-103. |
| [73] | ZHENG G , ZHANG F , ZHENG Z ,et al. DRN:a deep reinforcement learning framework for news recommendation[C]// The 2018 World Wide Web Conference. New York:ACM Press, 2018: 167-176. |
| [1] | 王飞跃, 缪青海, 张军平, 郑文博, 丁文文. 探讨AI for Science的影响与意义:现状与展望[J]. 智能科学与技术学报, 2023, 5(1): 1-6. |
| [2] | 张军欢, 朱正一, 蔡可玮. 人工智能与量化交易的课程建设[J]. 智能科学与技术学报, 2023, 5(1): 104-112. |
| [3] | 田永林, 陈苑文, 杨静, 王雨桐, 王晓, 缪青海, 王子然, 王飞跃. 元宇宙与平行系统:发展现状、对比及展望[J]. 智能科学与技术学报, 2023, 5(1): 121-132. |
| [4] | 卢经纬, 程相, 王飞跃. 求解微分方程的人工智能与深度学习方法:现状及展望[J]. 智能科学与技术学报, 2022, 4(4): 461-476. |
| [5] | 蔡莹皓, 杨华, 安璇, 王文硕, 杜沂东, 张嘉韬, 王志刚. 神经符号学及其应用研究[J]. 智能科学与技术学报, 2022, 4(4): 560-570. |
| [6] | 武强, 季雪庭, 吕琳媛. 元宇宙中的人工智能技术与应用[J]. 智能科学与技术学报, 2022, 4(3): 324-334. |
| [7] | 赖文柱, 陈德旺, 何振峰, 邓新国, GIUSEPPE CARLO Marano. 地铁列车驾驶技术发展综述:从人工驾驶到智能无人驾驶[J]. 智能科学与技术学报, 2022, 4(3): 335-343. |
| [8] | 马帅, 傅启明, 陈建平, 冯帆, 陆悠, 李铮伟, 裘舒年. 基于双池DQN的HVAC无模型优化控制方法[J]. 智能科学与技术学报, 2022, 4(3): 426-444. |
| [9] | 孙宇祥, 彭益辉, 李斌, 周佳炜, 张鑫磊, 周献中. 智能博弈综述:游戏AI对作战推演的启示[J]. 智能科学与技术学报, 2022, 4(2): 157-173. |
| [10] | 刘家成, 张向文. 基于TD3的电动汽车复合电源能量管理策略研究[J]. 智能科学与技术学报, 2022, 4(2): 277-287. |
| [11] | 冯埔, 吴文峻, 罗杰, 于鑫, 田雍恺. 基于群体熵的机器人群体智能汇聚度量[J]. 智能科学与技术学报, 2022, 4(1): 65-74. |
| [12] | 胡东伟, 冯晓璐. 大脑建模的理论框架及热点问题[J]. 智能科学与技术学报, 2021, 3(4): 412-434. |
| [13] | 李亚玲, 杨林瑶, 葛俊, 覃缘琪, 王晓. 博弈5.0:基于平行系统和机器博弈的社会认知平行博弈[J]. 智能科学与技术学报, 2021, 3(4): 507-520. |
| [14] | 王飞跃. 平行哲学与智能技术:平行产业与智慧社会的对偶方程与测试基础[J]. 智能科学与技术学报, 2021, 3(3): 245-255. |
| [15] | 刘文, 胡琨林, 李岩, 刘钊. 移动目标轨迹预测方法研究综述[J]. 智能科学与技术学报, 2021, 3(2): 149-160. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||