


Chinese Journal of Intelligent Science and Technology ›› 2022, Vol. 4 ›› Issue (2): 157-173.doi: 10.11959/j.issn.2096-6652.202209
• Surveys and Prospectives • Previous Articles Next Articles
Yuxiang SUN1, Yihui PENG1, Bin LI1, Jiawei ZHOU1, Xinlei ZHANG1, Xianzhong ZHOU1,2
Online:2022-06-15
Published:2022-06-01
Supported by:CLC Number:
Yuxiang SUN, Yihui PENG, Bin LI, et al. Overview of intelligent game:enlightenment of game AI to combat deduction[J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 157-173.
"
| 游戏/兵棋 | 状态空间 | 动作空间 | 决策数量 | 胜利条件 | 回报值设置 | 战争迷雾 | 观察信息 | 对手建模 | 想定设计 |
| 《Go》 | 中等 | 中等 | 中等 | 数子法/数目法 | 简单 | 无 | 简单 | 中等 | 固定 |
| 《星际争霸Ⅱ》 | 复杂 | 复杂 | 较多 | 单任务目标 | 中等 | 有 | 中等 | 中等 | 变化较小 |
| 《Dota 2》 | 复杂 | 复杂 | 较多 | 单任务目标 | 中等 | 有 | 中等 | 中等 | 固定 |
| 《CMANO》 | 非常复杂 | 非常复杂 | 巨大 | 多任务目标 | 复杂 | 有 | 复杂 | 复杂 | 变化较大 |
| 《智戎?未来指挥官》 | 非常复杂 | 非常复杂 | 巨大 | 多任务目标/积分 | 复杂 | 有 | 复杂 | 复杂 | 变化较大 |
| 《王者荣耀》 | 复杂 | 复杂 | 较多 | 单任务目标 | 中等 | 有 | 中等 | 中等 | 固定 |
| 《战争游戏:红龙》 | 非常复杂 | 非常复杂 | 巨大 | 多任务目标 | 复杂 | 有 | 复杂 | 复杂 | 变化较大 |
| 《MaCA》 | 中等 | 中等 | 中等 | 积分 | 简单 | 有 | 中等 | 中等 | 固定 |
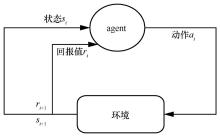
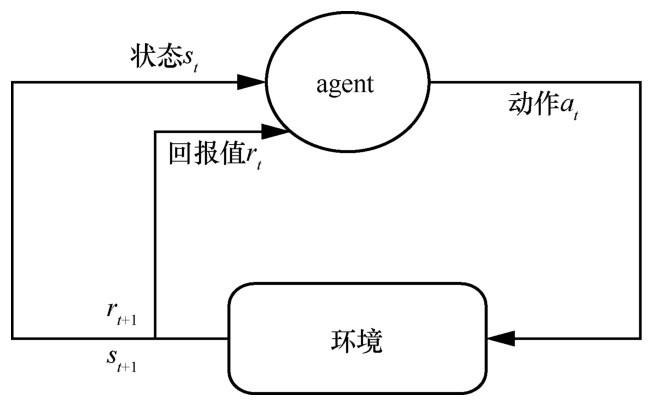
"
| [1] | 沈宇, 韩金朋, 李灵犀 ,等. 游戏智能中的 AI:从多角色博弈到平行博弈[J]. 智能科学与技术学报, 2020,2(3): 205-213. |
| SHEN Y , HAN J P , LI L X ,et al. AI in game intelligence—from multi-role game to parallel game[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(3): 205-213. | |
| [2] | 胡晓峰, 贺筱媛, 陶九阳 . AlphaGo 的突破与兵棋推演的挑战[J]. 科技导报, 2017,35(21): 49-60. |
| HU X F , HE X Y , TAO J Y . AlphaGo’s breakthrough and challenges of wargaming[J]. Science & Technology Review, 2017,35(21): 49-60. | |
| [3] | 叶利民, 龚立, 刘忠 . 兵棋推演系统设计与建模研究[J]. 计算机与数字工程, 2011,39(12): 58-61. |
| YE L M , GONG L , LIU Z . Research and modeling of a rehearsal system of naval battle[J]. Computer & Digital Engineering, 2011,39(12): 58-61. | |
| [4] | 谭鑫 . 基于规则的计算机兵棋系统技术研究[D]. 长沙:国防科学技术大学, 2010. |
| TAN X . Research on rule-based computer wargame system technology[D]. Changsha:National University of Defense Technology, 2010. | |
| [5] | 胡晓峰, 齐大伟 . 智能决策问题探讨——从游戏博弈到作战指挥,距离还有多远[J]. 指挥与控制学报, 2020,6(4): 356-363. |
| HU X F , QI D W . On problems of intelligent decision-making—how far is it from game-playing to operational command[J]. Journal of Command and Control, 2020,6(4): 356-363. | |
| [6] | YE D H , CHEN G B , ZHAO P L ,et al. Supervised learning achieves human-level performance in MOBA games:a case study of honor of kings[J]. IEEE Transactions on Neural Networks and Learning Systems, 2020: 1-11. |
| [7] | FU H T , TANG H Y , HAO J Y ,et al. Deep multi-agent reinforcement learning with discrete-continuous hybrid action spaces[C]// Proceedings of the 28th International Joint Conference on Artificial Intelligence. California:International Joint Conferences on Artificial Intelligence Organization, 2019. |
| [8] | WANG X J , SONG J X , QI P H ,et al. SCC:an efficient deep reinforcement learning agent mastering the game of StarCraft II[J]. arXiv preprint,2020,arXiv:2012.13169. |
| [9] | 周超, 胡晓峰, 郑书奎 ,等. 战略战役兵棋演习系统兵力聚合问题研究[J]. 指挥与控制学报, 2017,3(1): 19-26. |
| ZHOU C , HU X F , ZHENG S K ,et al. Force integration in strategic and operational war-game maneuver system[J]. Journal of Command and Control, 2017,3(1): 19-26. | |
| [10] | 黄凯奇, 兴军亮, 张俊格 ,等. 人机对抗智能技术[J]. 中国科学:信息科学, 2020,50(4): 540-550. |
| HUANG K Q , XING J L , ZHANG J G ,et al. Intelligent technologies of human-computer gaming[J]. Scientia Sinica (Informationis), 2020,50(4): 540-550. | |
| [11] | LIU X , ZHAO M J , DAI S ,et al. Tactical intention recognition in wargame[C]// Proceedings of 2021 IEEE 6th International Conference on Computer and Communication Systems. Piscataway:IEEE Press, 2021: 429-434. |
| [12] | SUN Y X , YUAN B , ZHANG T ,et al. Research and implementation of intelligent decision based on a priori knowledge and DQN algorithms in wargame environment[J]. Electronics, 2020,9(10): 1668. |
| [13] | 陈希亮, 李清伟, 孙彧 . 基于博弈对抗的空战智能决策关键技术[J]. 指挥信息系统与技术, 2021,12(2): 1-6. |
| CHEN X L , LI Q W , SUN Y . Key technologies for air combat intelligent decision based on game confrontation[J]. Command Information System and Technology, 2021,12(2): 1-6. | |
| [14] | 孙彧, 李清伟, 徐志雄 ,等. 基于多智能体深度强化学习的空战博弈对抗策略训练模型[J]. 指挥信息系统与技术, 2021,12(2): 16-20. |
| SUN Y , LI Q W , XU Z X ,et al. Game confrontation strategy training model for air combat based on multi-agent deep reinforcement learning[J]. Command Information System and Technology, 2021,12(2): 16-20. | |
| [15] | 瞿崇晓, 高翔, 夏少杰 ,等. 一种基于深度强化学习的无监督智能作战推演系统:CN109636699A[P]. 2019. |
| QU C X , GAO X , XIA S J ,et al. Unsupervised intelligent combat deduction system based on deep reinforcement learning:CN109636699A[P]. 2019. | |
| [16] | 张振, 黄炎焱, 张永亮 ,等. 基于近端策略优化的作战实体博弈对抗算法[J]. 南京理工大学学报, 2021,45(1): 77-83. |
| ZHANG Z , HUANG Y Y , ZHANG Y L ,et al. Battle entity confrontation algorithm based on proximal policy optimization[J]. Journal of Nanjing University of Science and Technology, 2021,45(1): 77-83. | |
| [17] | 李琛, 黄炎焱, 张永亮 ,等. Actor-Critic 框架下的多智能体决策方法及其在兵棋上的应用[J]. 系统工程与电子技术, 2021,43(3): 755-762. |
| LI C , HUANG Y Y , ZHANG Y L ,et al. Multi-agent decision-making method based on Actor-Critic framework and its application in wargame[J]. Systems Engineering and Electronics, 2021,43(3): 755-762. | |
| [18] | 程恺, 陈刚, 余晓晗 ,等. 知识牵引与数据驱动的兵棋AI设计及关键技术[J]. 系统工程与电子技术, 2021,43(10): 2911-2917. |
| CHENG K , CHEN G , YU X H ,et al. Knowledge traction and data-driven wargame AI design and key technologies[J]. Systems Engineering and Electronics, 2021,43(10): 2911-2917. | |
| [19] | 张可, 郝文宁, 余晓晗 ,等. 基于遗传模糊系统的兵棋推演关键点推理方法[J]. 系统工程与电子技术, 2020,42(10): 2303-2311. |
| ZHANG K , HAO W M , YU X H ,et al. Wargame key point reasoning method based on genetic fuzzy system[J]. Systems Engineering and Electronics, 2020,42(10): 2303-2311. | |
| [20] | 李航, 刘代金, 刘禹 . 军事智能博弈对抗系统设计框架研究[J]. 火力与指挥控制, 2020,45(9): 116-121. |
| LI H , LIU D J , LIU Y . Architecture design research of military intelligent wargame system[J]. Fire Control & Command Control, 2020,45(9): 116-121. | |
| [21] | 施伟, 冯旸赫, 程光权 ,等. 基于深度强化学习的多机协同空战方法研究[J]. 自动化学报, 2021,47(7): 1610-1623. |
| SHI W , FENG Y H , CHENG G Q ,et al. Research on multi-aircraft cooperative air combat method based on deep reinforcement learning[J]. Acta Automatica Sinica, 2021,47(7): 1610-1623. | |
| [22] | 徐佳乐, 张海东, 赵东海 ,等. 基于卷积神经网络的陆战兵棋战术机动策略学习[J]. 系统仿真学报, 2021:已录用. |
| XU J L , ZHANG H D , ZHAO D H ,et al. Tactical maneuver strategy learning of wargame based on convolutional neural network[J]. Journal of System Simulation, 2021:acceped. | |
| [23] | WANG H N , LIU N , ZHANG Y Y ,et al. Deep reinforcement learning:a survey[J]. Frontiers of Information Technology & Electronic Engineering, 2020,21(12): 1726-1744. |
| [24] | MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Human-level control through deep reinforcement learning[J]. Nature, 2015,518(7540): 529-533. |
| [25] | SILVER D , HUANG A , MADDISON C J ,et al. Mastering the game of Go with deep neural networks and tree search[J]. Nature, 2016,529(7587): 484-489. |
| [26] | SILVER D , SCHRITTWIESER J , SIMONYAN K ,et al. Mastering the game of Go without human knowledge[J]. Nature, 2017,550(7676): 354-359. |
| [27] | VINYALS O , BABUSCHKIN I , CZARNECKI W M ,et al. Grandmaster level in StarCraft II using multi-agent reinforcement learning[J]. Nature, 2019,575(7782): 350-354. |
| [28] | BERNER C , BROCKMAN G , CHAN B ,et al. Dota 2 with large scale deep reinforcement learning[J]. arXiv preprint,2019,arXiv:1912.06680. |
| [29] | BROWN N , SANDHOLM T . Superhuman AI for multiplayer poker[J]. Science, 2019,365(6456): 885-890. |
| [30] | SCHRITTWIESER J , ANTONOGLOU I , HUBERT T ,et al. Mastering Atari,Go,chess and shogi by planning with a learned model[J]. Nature, 2020,588(7839): 604-609. |
| [31] | PRICE M . What impact do VR controllers have on the traditional strategy game genre[D]. Huddersfield:University of Huddersfield, 2019. |
| [32] | DAVID A S , JOHNSON M . Reinforcing deterrence on NATO’s eastern flank:wargaming the defense of the baltics[R]. 2016. |
| [33] | CANNON C T , GOERICKE S . Using convolution neural networks to develop robust combat behaviors through reinforcement learning[D]. CA:Naval Postgraduate School, 2021. |
| [34] | 缐珊珊 . 美俄人工智能军事应用发展分析[J]. 大数据, 2020,6(4): 125-132. |
| XIAN S S . An analysis of the military application and development path of artificial intelligence in the United States and Russia[J]. Big Data Research, 2020,6(4): 125-132. | |
| [35] | TARRAF D C , GILMORE J M , BOSTON S . An experiment in tactical wargaming with platforms enabled by artificial intelligence[R]. 2020. |
| [36] | YE D H , LIU Z , SUN M F ,et al. Mastering complex control in MOBA games with deep reinforcement learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020,34(4): 6672-6679. |
| [37] | BROCKMAN G , CHEUNG V , PETTERSSON L ,et al. OpenAI gym[J]. arXiv preprint,2016,arXiv:1606.01540. |
| [38] | ARULKUMARAN K , CULLY A , TOGELIUS J . Alphastar:an evolutionary computation perspective[C]// Proceedings of the Genetic and Evolutionary Computation Conference Companion.[S.l.:s.n.], 2019: 314-315. |
| [39] | YE D H , CHEN G B , ZHANG W ,et al. Towards playing full MOBA games with deep reinforcement learning[J]. arXiv preprint,2020,arXiv:2011.12692. |
| [40] | MNIH V , KAVUKCUOGLU K , SILVER D ,et al. Playing atari with deep reinforcement learning[J]. arXiv preprint,2013,arXiv:1312.5602. |
| [41] | 张凯峰, 俞扬 . 基于逆强化学习的示教学习方法综述[J]. 计算机研究与发展, 2019,56(2): 254-261. |
| ZHANG K F , YU Y . Methodologies for imitation learning via inverse reinforcement learning:a review[J]. Journal of Computer Research and Development, 2019,56(2): 254-261. | |
| [42] | 曹雷 . 基于深度强化学习的智能博弈对抗关键技术[J]. 指挥信息系统与技术, 2019,10(5): 1-7. |
| CAO L . Key technologies of intelligent game confrontation based on deep reinforcement learning[J]. Command Information System and Technology, 2019,10(5): 1-7. | |
| [43] | RISI S , PREUSS M . Behind DeepMind’s AlphaStar AI that reached grandmaster level in StarCraft II[J]. KI-KünstlicheIntelligenz, 2020,34(1): 85-86. |
| [44] | SILVER D , VENESS J . Monte-Carlo planning in large POMDPs[C]// Proceedings of the Advances in Neural Information Processing Systems 23.[S.l.:s.n.], 2010. |
| [45] | GOODMAN J , LUCAS S . Does it matter how well I know what you’re thinking? Opponent modelling in an RTS game[C]// Proceedings of 2020 IEEE Congress on Evolutionary Computation. Piscataway:IEEE Press, 2020: 1-8. |
| [46] | JOHANSON M . Measuring the size of large no-limit poker games[J]. arXiv preprint,2013,arXiv:1302.7008. |
| [47] | DUGAS D , NIETO J , SIEGWART R ,et al. Navrep:unsupervised representations for reinforcement learning of robot navigation in dynamic human environments[C]// Proceedings of 2021 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2021: 7829-7835. |
| [48] | ONTANóN S , SYNNAEVE G , URIARTE A ,et al. A survey of real-time strategy game AI research and competition in StarCraft[J]. IEEE Transactions on Computational Intelligence and AI in games, 2013,5(4): 293-311. |
| [49] | FENNER S A , ROGERS J . Combinatorial game complexity:an introduction with poset games[J]. arXiv preprint,2015,arXiv:1505.07416. |
| [50] | SUTTON R S , BARTO A G . Reinforcement learning:an introduction[J]. IEEE Transactions on Neural Networks, 2005,16(1): 285-286. |
| [51] | VAN HASSELT H , GUEZ A , SILVER D . Deep reinforcement learning with double q-learning[C]// Proceedings of the 30th AAAI Conference on Artificial Intelligence. Piscataway:IEEE Press, 2016. |
| [52] | SCHAUL T , QUAN J , ANTONOGLOU I ,et al. Prioritized experience replay[J]. arXiv preprint,2015,arXiv:1511.05952. |
| [53] | WANG Z Y , SCHAUL T , HESSEL M ,et al. Dueling network architectures for deep reinforcement learning[J]. arXiv preprint,2015,arXiv:1511.06581. |
| [54] | MNIH V , BADIA A P , MIRZA M ,et al. Asynchronous methods for deep reinforcement learning[C]// Proceedings of the 33rd International Conference on Machine Learning.[S.l.:s.n.], 2016: 1928-1937. |
| [55] | 刘朝阳, 穆朝絮, 孙长银 . 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020,2(4): 314-326. |
| LIU Z Y , MU C X , SUN C Y . An overview on algorithms and applications of deep reinforcement learning[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(4): 314-326. | |
| [56] | LILLICRAP T P , HUNT J J , PRITZEL A ,et al. Continuous control with deep reinforcement learning[J]. arXiv preprint,2015,arXiv:1509.02971. |
| [57] | LOWE R , WU Y , TAMAR A ,et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]// Proceedings of the Advances in Neural Information Processing Systems 30.[S.l.:s.n.], 2018. |
| [58] | SCHULMAN J , WOLSKI F , DHARIWAL P ,et al. Proximal policy optimization algorithms[J]. arXiv preprint,2017,arXiv:1707.06347. |
| [59] | HAARNOJA T , ZHOU A , ABBEEL P ,et al. Soft actor-critic:off-policy maximum entropy deep reinforcement learning with a stochastic actor[C]// Proceedings of the International Conference on Machine Learning.[S.l.:s.n.], 2018: 1861-1870. |
| [60] | FUJIMOTO S , VAN HOOF H , MEGER D . Addressing function approximation error in actor-critic methods[C]// Proceedings of the International Conference on Machine Learning.[S.l.:s.n.], 2018: 1587-1596. |
| [61] | FLORENSA C , DUAN Y , ABBEEL P . Stochastic neural networks for hierarchical reinforcement learning[J]. arXiv preprint,2017,arXiv:1704.03012. |
| [62] | RAFATI J , NOELLE D C . Learning representations in model-free hierarchical reinforcement learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33: 10009-10010. |
| [63] | PANG Z J , LIU R Z , MENG Z Y ,et al. On reinforcement learning for full-length game of StarCraft[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33: 4691-4698. |
| [64] | LI S Y , WANG R , TANG M X ,et al. Hierarchical reinforcement learning with advantage-based auxiliary rewards[J]. arXiv preprint,2019,arXiv:1910.04450. |
| [65] | HOCHREITER S , SCHMIDHUBER J . Long short-term memory[J]. Neural Computation, 1997,9(8): 1735-1780. |
| [66] | YAO X . A review of evolutionary artificial neural networks[J]. International Journal of Intelligent Systems, 1993,8(4): 539-567. |
| [67] | DING S F , LI H , SU C Y ,et al. Evolutionary artificial neural networks:a review[J]. Artificial Intelligence Review, 2013,39(3): 251-260. |
| [68] | YAO X , LIU Y . A new evolutionary system for evolving artificial neural networks[J]. IEEE Transactions on Neural Networks, 1997,8(3): 694-713. |
| [69] | SALIMANS T , HO J , CHEN X ,et al. Evolution strategies as a scalable alternative to reinforcement learning[J]. arXiv preprint,2017,arXiv:1703.03864. |
| [70] | SUCH F P , MADHAVAN V , CONTI E ,et al. Deep neuroevolution:genetic algorithms are a competitive alternative for training deep neural networks for reinforcement learning[J]. arXiv preprint,2017,arXiv:1712.06567. |
| [71] | 栾丽华, 吉根林 . 决策树分类技术研究[J]. 计算机工程, 2004,30(9): 94-96,105. |
| LUAN L H , JI G L . The study on decision tree classification techniques[J]. Computer Engineering, 2004,30(9): 94-96,105. | |
| [72] | 鲁大剑 . 面向作战推演的博弈与决策模型及应用研究[D]. 南京:南京理工大学, 2013. |
| LU D J . Research on game and decision model for operational deduction and its application[D]. Nanjing:Nanjing University of technology, 2013. | |
| [73] | 尹星, 孙鹏, 韩冰 . 基于决策树的作战实体行为规则建模[J]. 指挥控制与仿真, 2020,42(1): 15-19. |
| YIN X , SUN P , HAN B . Modeling of behavior rules of combat entities based on decision tree[J]. Command Control & Simulation, 2020,42(1): 15-19. | |
| [74] | ZHOU Z H , FENG J . Deep forest[J]. National Science Review, 2019,6(1): 74-86. |
| [75] | 董浩洋, 张永亮, 齐宁 ,等. 基于综合势能的作战行动序列生成方法研究[J]. 军事运筹与系统工程, 2020,34(3): 11-18. |
| DONG H Y , ZHANG Y L , QI N ,et al. Research on the method of generating operational sequence based on comprehensive potential energy[J]. Military Operations Research and Systems Engineering, 2020,34(3): 11-18. | |
| [76] | BREIMAN L . Random forests[J]. Machine learning, 2001,45(1): 5-32. |
| [77] | DE MESENTIER SILVA F , TOGELIUS J , LANTZ F ,et al. Generating novice heuristics for post-flop poker[C]// Proceedings of 2018 IEEE Conference on Computational Intelligence and Games. Piscataway:IEEE Press, 2018: 1-8. |
| [78] | 周献中, 郭庆军, 鞠恒荣 . 基于人件服务的C4ISR服务视点扩展[J]. 指挥信息系统与技术, 2016,7(5): 1-9. |
| ZHOU X Z , GUO Q J , JU H R . Extended C4ISR service viewpoint based on humanware service[J]. Command Information System and Technology, 2016,7(5): 1-9. | |
| [79] | 朱咸军, 周献中, 王友发 ,等. 面向新型决策系统的人件模型研究[J]. 中国科技论坛, 2016(6): 121-127. |
| ZHU X J , ZHOU X Z , WANG Y F ,et al. Research on humanware model of novel decision system-oriented[J]. Forum on Science and Technology in China, 2016(6): 121-127. | |
| [80] | LUCAS Simon, 沈甜雨, 王晓, ,等. 基于统计前向规划算法的游戏通用人工智能[J]. 智能科学与技术学报, 2019,1(3): 219-227. |
| SIMON L , SHEN T Y , WANG X ,et al. General game AI with statistical forward planning algorithms[J]. Chinese Journal of Intelligent Science and Technology, 2019,1(3): 219-227. | |
| [81] | SHAO K , ZHU Y H , ZHAO D B . StarCraft micromanagement with reinforcement learning and curriculum transfer learning[J]. IEEE Transactions on Emerging Topics in Computational Intelligence, 2019,3(1): 73-84. |
| [82] | SILVER D , HUBERT T , SCHRITTWIESER J ,et al. A general reinforcement learning algorithm that masters chess,shogi,and Go through self-play[J]. Science, 2018,362(6419): 1140-1144. |
| [83] | TANG Z T , ZHU Y H , ZHAO D B ,et al. Enhanced rolling horizon evolution algorithm with opponent model learning[J]. IEEE Transactions on Games, 2020:1. |
| [84] | 杨旭, 王锐, 张涛 . 面向无人机集群路径规划的智能优化算法综述[J]. 控制理论与应用, 2020,37(11): 2291-2302. |
| YANG X , WANG R , ZHANG T . Review of unmanned aerial vehicle swarm path planning based on intelligent optimization[J]. Control Theory & Applications, 2020,37(11): 2291-2302. | |
| [85] | 张菁, 何友, 彭应宁 ,等. 基于神经网络和人工势场的协同博弈路径规划[J]. 航空学报, 2019,40(3): 322493. |
| ZHANG J , HE Y , PENG Y N ,et al. Neural network and artificial potential field based cooperative and adversarial path planning[J]. Acta Aeronautica et Astronautica Sinica, 2019,40(3): 322493. | |
| [86] | LEE D , TANG H R , ZHANG J O ,et al. Modular architecture for StarCraft II with deep reinforcement learning[C]// Proceedings of the AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment.[S.l.:s.n.], 2018. |
| [87] | MEENAKSHI N . An efficient agent created in StarcCraft 2 using pysc2[J]. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 2021,12(10): 336-342. |
| [1] | Shuai MA, Qiming FU, Jianping CHEN, Fan FENG, You LU, Zhengwei LI, Shunian QIU. HVAC model-free optimal control method based on double-pools DQN [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(3): 426-444. |
| [2] | Jiacheng LIU, Xiangwen ZHANG. TD3-based energy management strategy for hybrid energy storage system of electric vehicle [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 277-287. |
| [3] | Pu FENG, Wenjun WU, Jie LUO, Xin YU, Yongkai TIAN. Emergence measurement of robot swarm intelligence based on swarm entropy [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(1): 65-74. |
| [4] | Zhiqiang HU. The framework model on internal mechanism of big data intelligent command and control [J]. Chinese Journal of Intelligent Science and Technology, 2021, 3(1): 101-109. |
| [5] | Zhaoyang LIU, Chaoxu MU, Changyin SUN. An overview on algorithms and applications of deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 314-326. |
| [6] | Tao LI, Qinglai WEI. Intelligent heating temperature control system based on deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 348-353. |
| [7] | Rizhong WANG, Huiping LI, Di CUI, Demin XU. Depth control of autonomous underwater vehicle using deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 354-360. |
| [8] | Huiqiao FU, Kaiqiang TANG, Guizhou DENG, Xinpeng WANG, Chunlin CHEN. Motion planning for hexapod robot using deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 361-371. |
| [9] | Yu SHEN,Jinpeng HAN,Lingxi LI,Fei-Yue WANG. AI in game intelligence—from multi-role game to parallel game [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(3): 205-213. |
| [10] | LUCAS Simon, Tianyu SHEN, Xiao WANG, Jie ZHANG. General game AI with statistical forward planning algorithms [J]. Chinese Journal of Intelligent Science and Technology, 2019, 1(3): 219-227. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||