


Chinese Journal of Intelligent Science and Technology ›› 2023, Vol. 5 ›› Issue (3): 313-329.doi: 10.11959/j.issn.2096-6652.202326
• Surveys and Prospectives • Previous Articles Next Articles
Fengtao XIANG( ), Junren LUO, Xueqiang GU, Jiongming SU, Wanpeng ZHANG
), Junren LUO, Xueqiang GU, Jiongming SU, Wanpeng ZHANG
Received:2023-07-21
Revised:2023-08-22
Online:2023-09-15
Published:2023-09-26
Contact:
Fengtao XIANG
E-mail:xiangfengtao@nudt.edu.cn
CLC Number:
Fengtao XIANG, Junren LUO, Xueqiang GU, et al. Survey on multi-agent reinforcement learning methods from the perspective of population[J]. Chinese Journal of Intelligent Science and Technology, 2023, 5(3): 313-329.
"
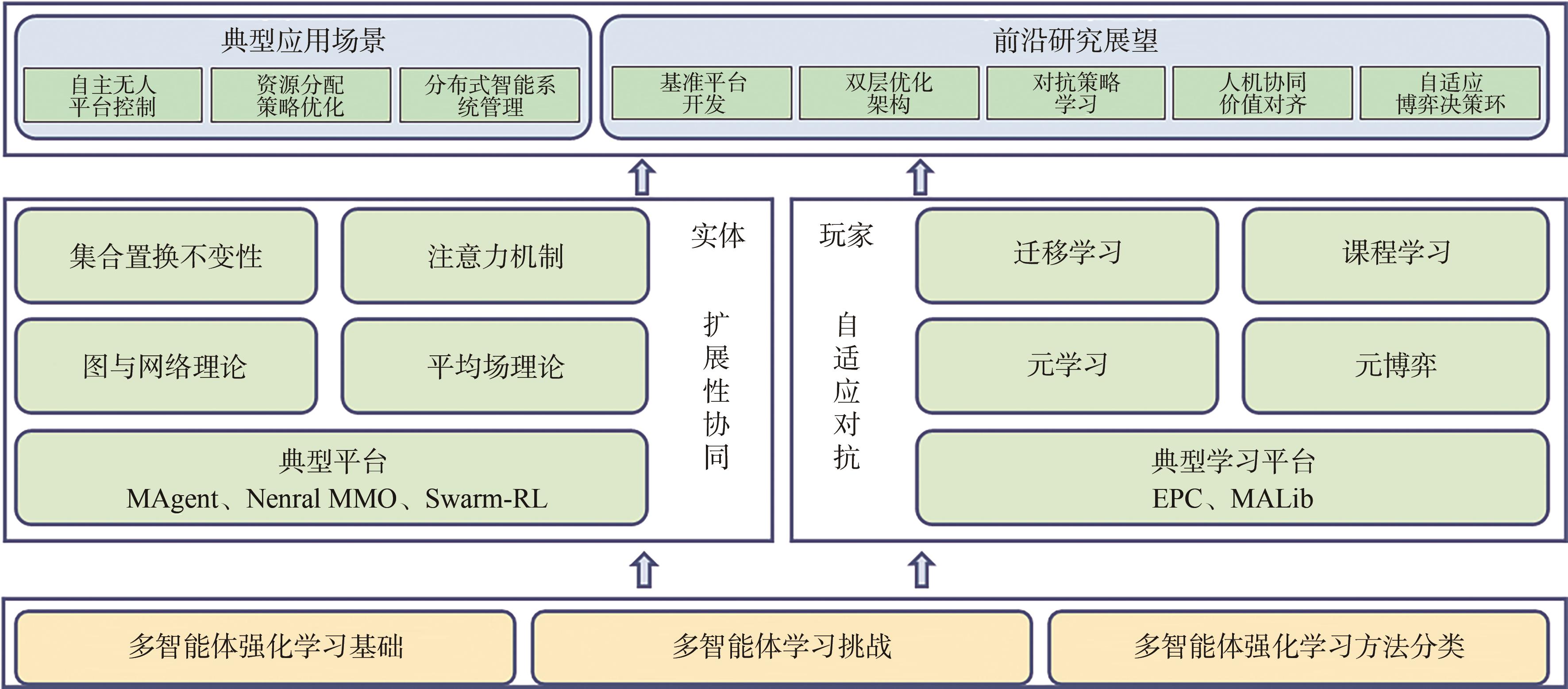
"
"
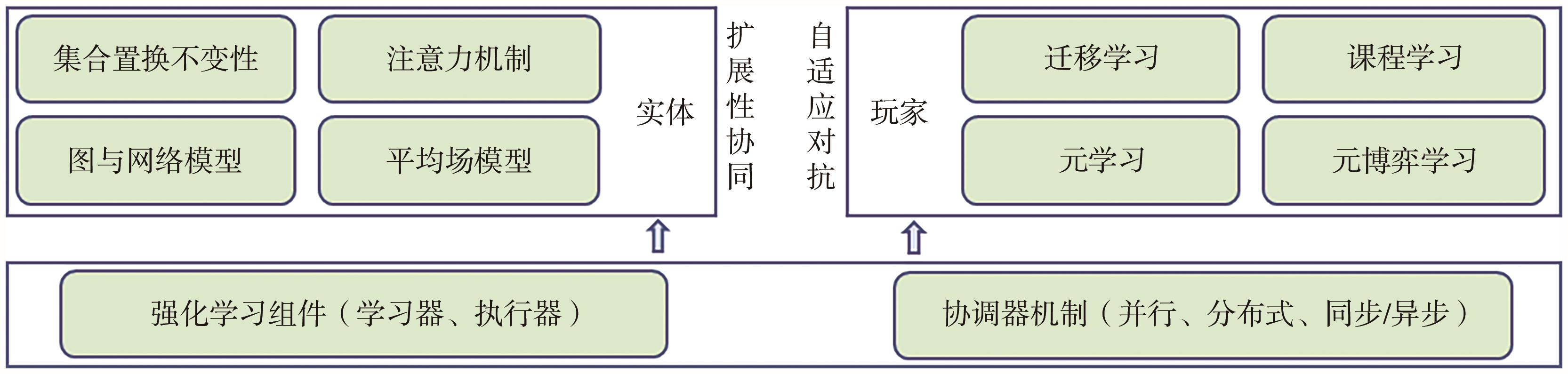
"
"
| 类别 | 建模框架与典型方法 | 主要机制及方法特点 | 缺点分析 |
|---|---|---|---|
| 集合置换不变性 | 深度集合[ | 利用置换不变性设计满足集合数据处理的网络 | 忽略了智能体之间的差异,无法满足异构智能体 |
| 深度集合Q值[ | 在深度强化学习中引入深度集合网络架构 | ||
| 深度集群[ | 多无人机交互采用深度集合架构编码 | ||
| 深度集合平均场[ | 基于深度集合架构与平均场理论设计PPO算法 | ||
| 注意力机制 | 注意力关系型编码器[ | 可以聚合任意数量邻近智能体的特征表示 | 忽略了智能体之间的信息交互,无法保证有效区分各智能体的重要性 |
| 随机实体分解[ | 采用随机分解来处理不同类型和数量的智能体 | ||
| 基于注意力的深度集合[ | 采用基于注意力的深度集合框架来控制集群 | ||
| 通用策略分解Transformer[ | 利用Transformer来学习分组实体的策略 | ||
| 种群不变Transformer[ | 设计具备种群数量规模不变的Transformer | ||
| 图与网络理论 | 可分解马尔可夫决策[ | 动态贝叶斯网络分解状态变换函数 | 需要建模复杂的交互关系,很难处理超大规模智能体策略空间的指数增长 |
| 联网分布式决策[ | 利用图表示部分可观的局部交互 | ||
| 可分解分散式决策[ | 利用协调图将状态变换函数分解成动态贝叶斯网络 | ||
| 图卷积网络[ | 直接利用图卷积网络学习大规模无人机编队控制 | ||
| 基于聚合的图神经网络[ | 利用聚合操作来处理变长维度的输入 | ||
| 图Q值混合网络[ | 利用图神经网络与注意力机制学习值函数分解 | ||
| 图注意神经网络[ | 设计小组与个人之间的注意力神经网络 | ||
| 深度循环图网络[ | 结合门控循环单元和图注意力网络模型 | ||
| 深度协调图[ | 设计基于超图表征智能体关系的图卷积神经网络 | ||
| 超图卷积混合[ | 基于超图卷积的值分解 | ||
| 协作图贝叶斯博弈[ | 构建满足智能体之间交互的非平稳交互图 | ||
| 平均场理论 | 平均场多智能体强化学习[ | 基于平均嵌入设计满足多智能体的平均场Q学习 | 忽略了数量规模信息和智能体重要程度 |
| 平均场博弈[ | 基于智能体与邻居的交互图构建局部平均场博弈 | ||
| 平均场控制[ | 将多智能体强化学习转换成高维单智能体决策 |
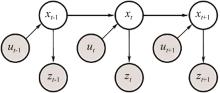
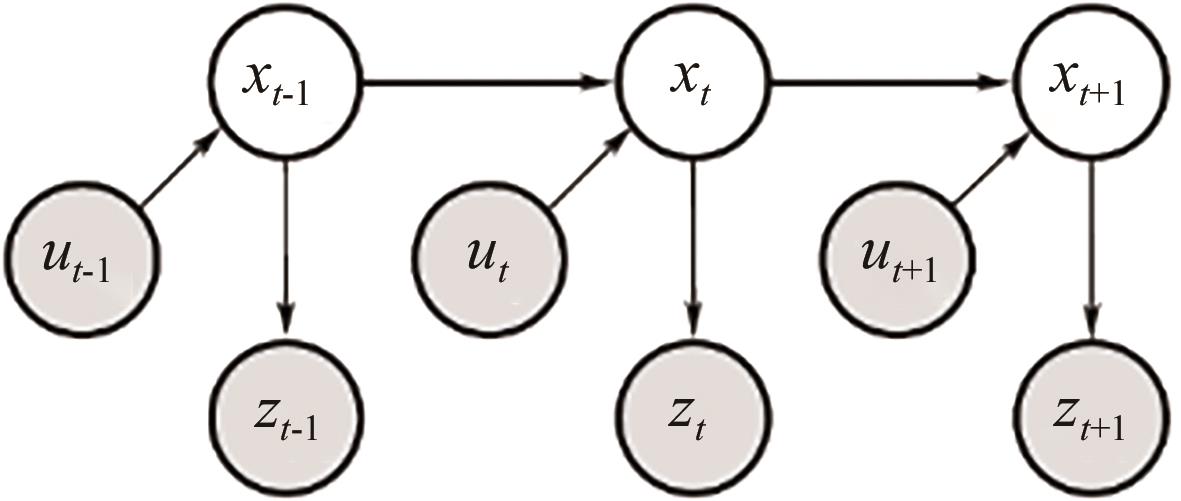
"
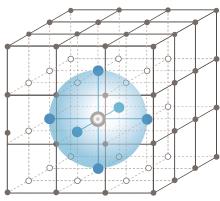
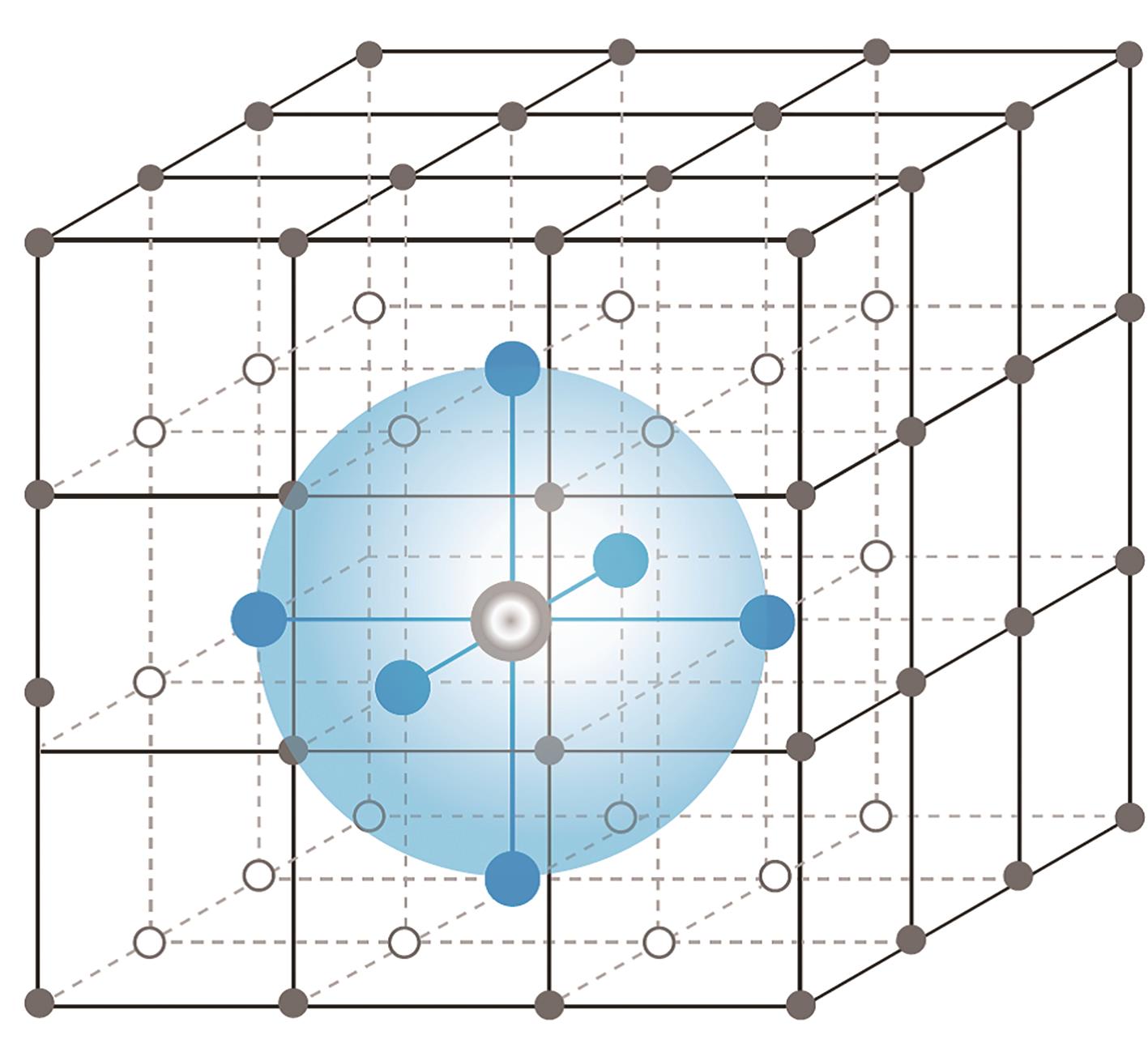
"
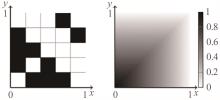
"
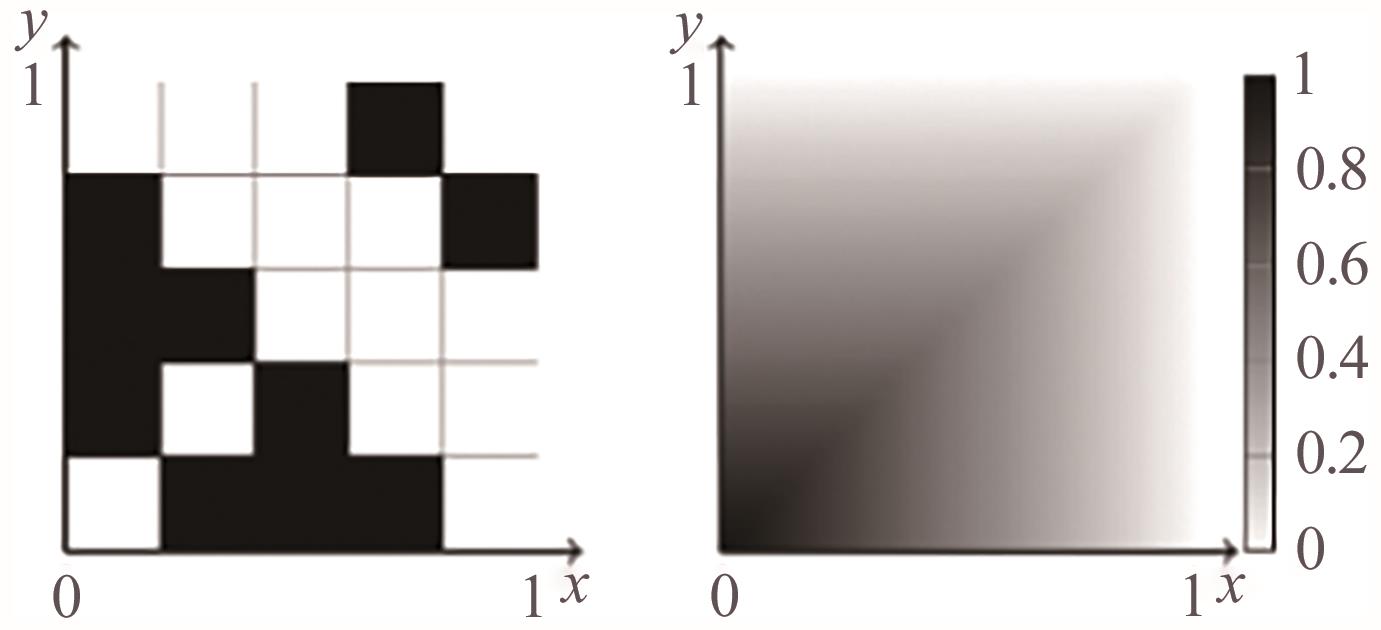
"
"
"
| 类别 | 建模框架与典型方法 | 主要机制及方法特点 | 缺点分析 |
|---|---|---|---|
| 迁移学习 | 离线预训练[ | 利用线下大样本,重构强化学习范式,进行预训模式的学习 | 预训练学习策略需要在线微调,难处理分布外场景 |
| 任务及域适应[ | 将源任务中学习到的知识,用于适配目标任务 | ||
| 智能体间迁移[ | 智能体之间采用 | ||
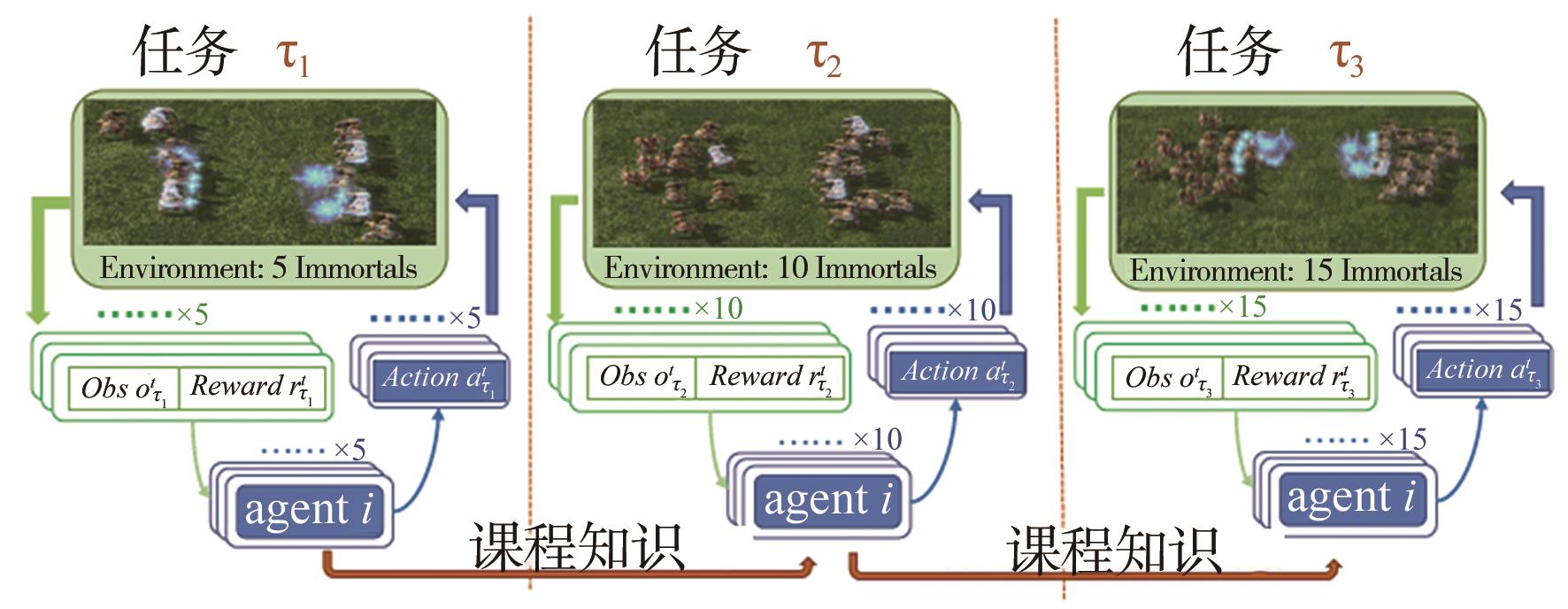
| 课程学习 | 任务难易程度课程[ | 将不同的任务场景分解成不同难度的子任务 | 课程难设计,自主课程中环境-策略协同演化难收敛 |
| 智能体规模课程 | 设定不同规模数量的智能体学习场景 | ||
| 自主课程学习[ | 利用环境与智能体进行协同学习 | ||
| 元学习 | 度量元学习[ | 基于深度度量(相似性)学习 | 训练过程不稳定,难以适应新的任务 |
| 基础与元学习器[ | 基础学习器学习底层策略,元学习器学习上层共性策略 | ||
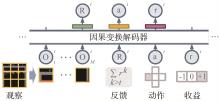
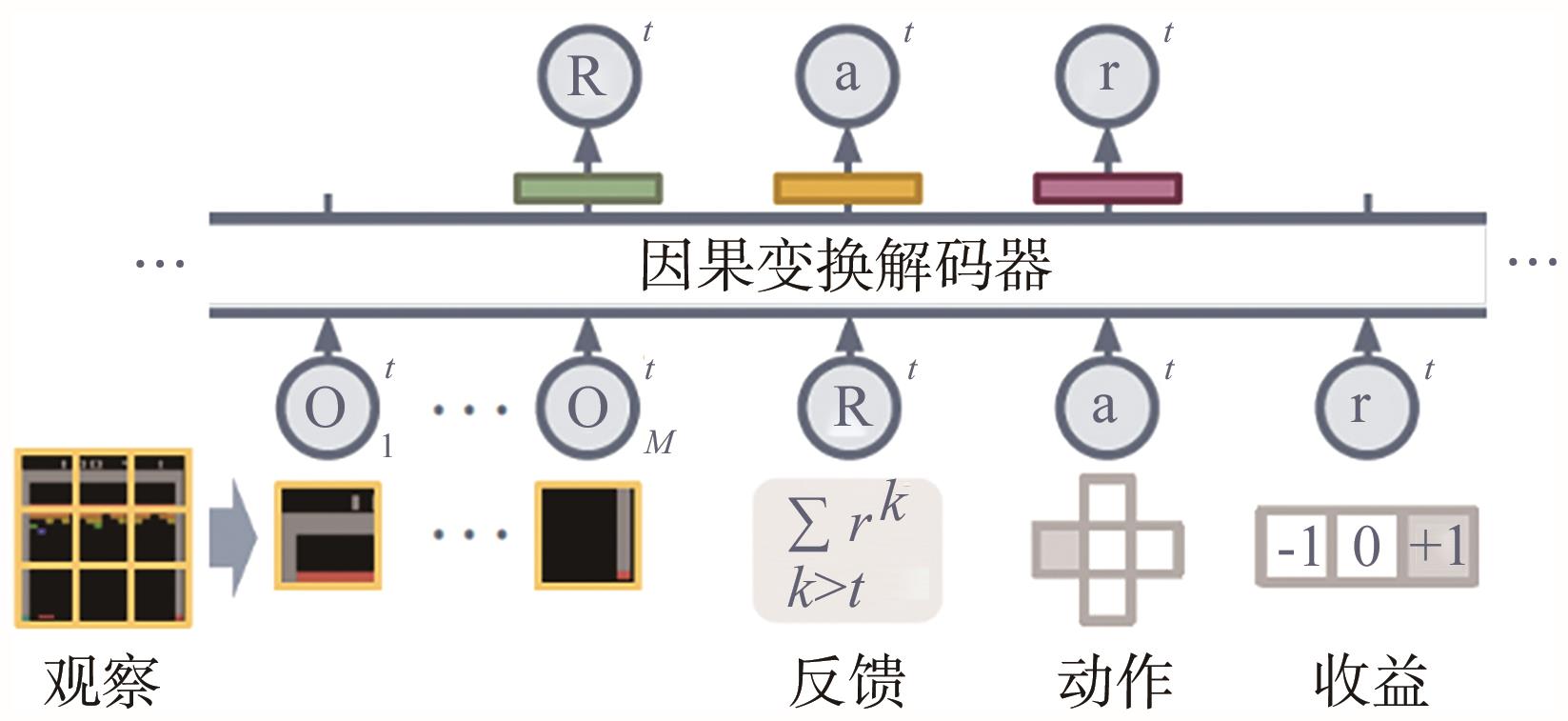
| 贝叶斯元学习[ | 从多个模型中推断贝叶斯后验 | ||
| 元博弈学习 | 基于策略评估的博弈策略学习方法 | 大规模博弈策略学习样本效率较低,分布式并行框架难适配,学习到的策略模型难以应对高动态测试时规划 | |
| 管线PSRO[ | 利用并行化的博弈策略学习方法 | ||
| 单纯形PSRO[ | 利用单纯形构建基于贝叶斯最优的策略学习方法 | ||
| 自主PSRO[ | 基于课程学习方法设计自主博弈策略学习方法 | ||
| 离线PSRO[ | 利用离线资料学习环境模型和预先训练策略模型 | ||
| 在线PSRO[ | 考虑对手类型的在线无悔的博弈策略学习方法 | ||
| 随时PSRO[ | 基于种群后悔最小化的迭代式博弈策略学习方法 | ||
| 自对弈PSRO[ | 基于自对弈学习的迭代式博弈策略学习方法 |
"
"
"
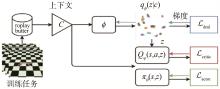
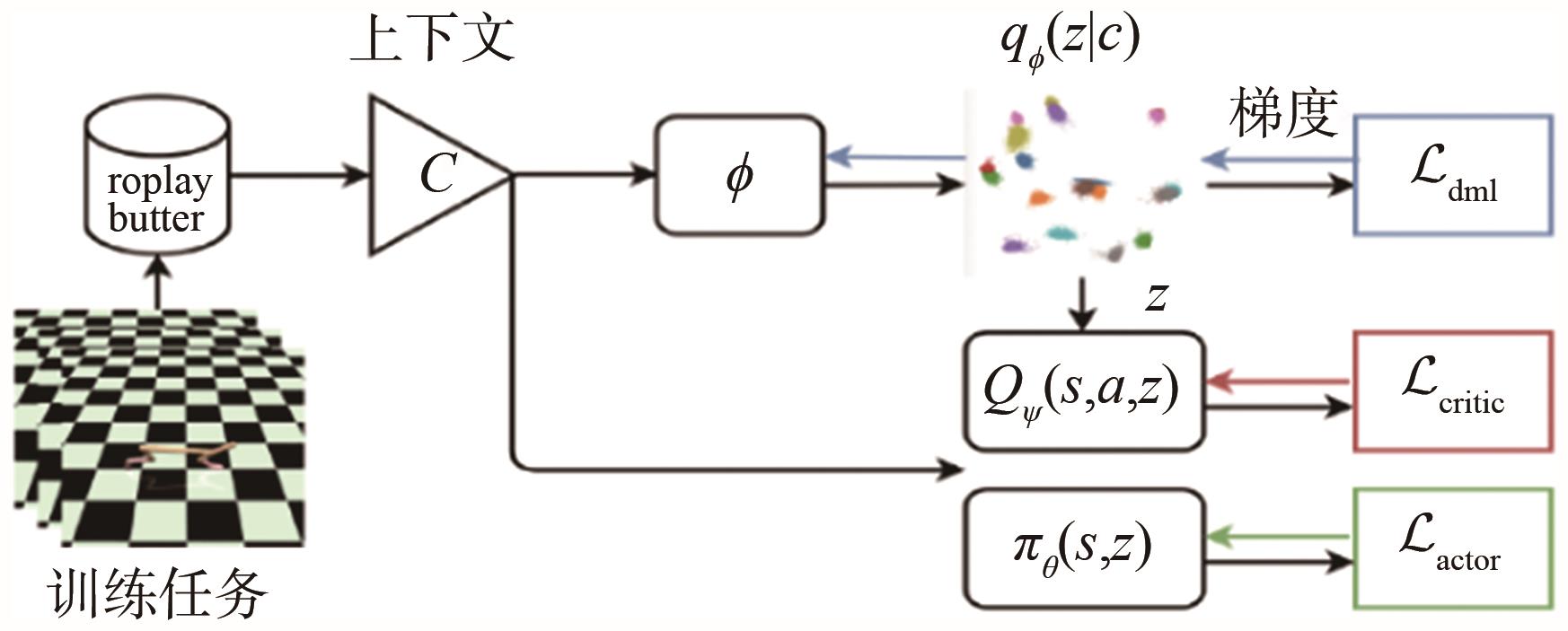
"
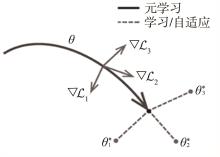
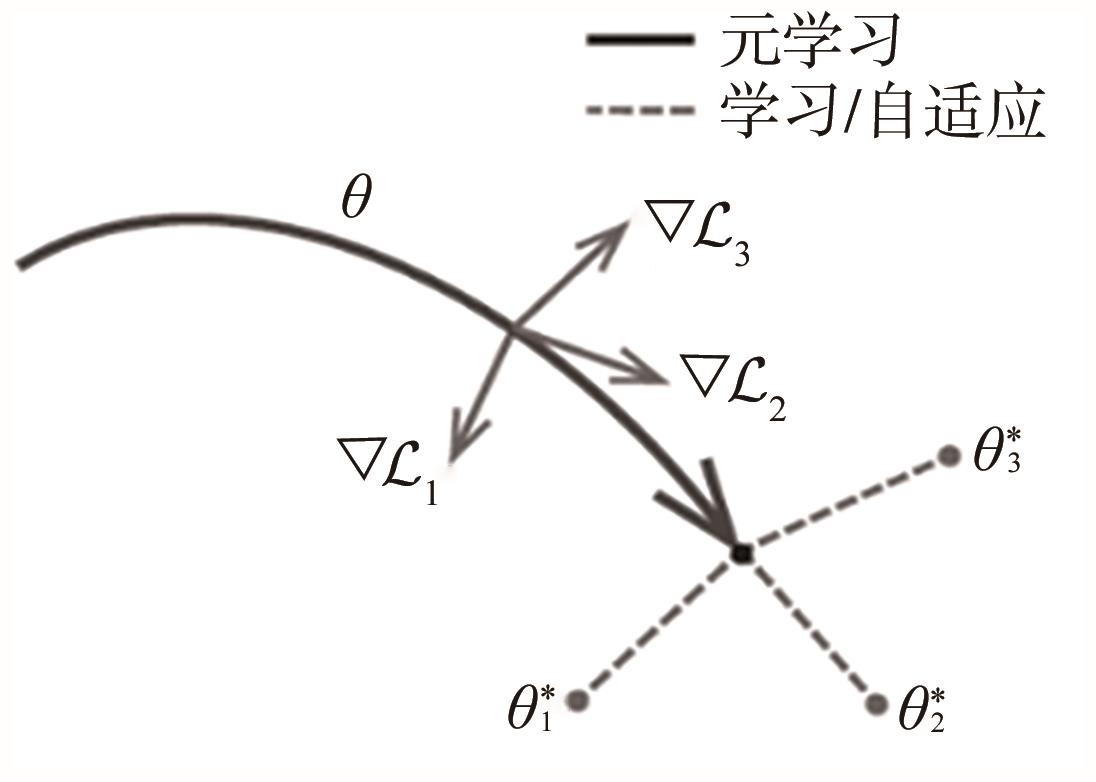
"
| 1 | YANG Y, WANG J. An overview of multi-agent reinforcement learning from game theoretical perspective [EB]. arXiv preprint, 2020, arXiv:. |
| 2 | SILVA F L, COSTA A H R. A survey on transfer learning for multi-agent reinforcement learning systems[J]. Journal of Artificial Intelligence Research, 2019, 64: 645-703. |
| 3 | YANG T, TANG H, BAI C, et al. Exploration in deep reinforcement learning: a comprehensive survey [EB]. arXiv preprint, 2021, arXiv:. |
| 4 | 王涵, 俞扬, 姜远. 基于通信的多智能体强化学习进展综述[J]. 中国科学: 信息科学, 2022, 52(5): 742-764. |
| WANG H, YU Y, JIANG Y. Review on the progress of multi-agent reinforcement learning based on communication[J]. Science China Information Sciences, 2022, 52(5): 742-764. | |
| 5 | 殷昌盛, 杨若鹏, 朱巍, 等. 多智能体分层强化学习综述 [J]. 智能系统学报, 2020, 15(4): 646-655. |
| YIN C S, YANG R P, ZHU W, et al. A survey on multi-agent hierarchical reinforcement learning[J]. CAAI Transactions on Intelligent Systems, 2020, 15(4): 646-655. | |
| 6 | 王龙, 黄锋. 多智能体博弈、学习与控制[J]. 自动化学报, 2023, 49(3): 580-613. |
| WANG L, HUANG F. An interdisciplinary survey of multi-agent games, learning and control [J]. Acta Automatica Sinica, 2023, 49(3): 580-613. | |
| 7 | 罗俊仁, 张万鹏, 苏炯铭, 等. 多智能体博弈学习研究进展[J]. 系统工程与电子技术, 2022, 已录用. |
| LUO J R, ZHANG W P, SU J M, et al. Research progress of multi-agent game theoretic learning[J]. Systems Engineering and Electronics, 2022, Accepted. | |
| 8 | DENG X, LI N, MGUNI D, et al. On the complexity of computing markov perfect equilibrium in general-sum stochastic games[J]. National Science Review, 2023, 10(1): nwac256. |
| 9 | ZHANG T, LI Y, LI S, et al. Decentralized circle formation control for fish-like robots in the real-world via reinforcement learning[C]//2021 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE, 2021: 8814-8820. |
| 10 | ZHENG L, YANG J, CAI H, et al. MAgent: a many-agent reinforcement learning platform for artificial collective intelligence[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1). |
| 11 | FU Q X, QIU T H, YI J Q, et al. Concentration network for reinforcement learning of large-scale multi-agent systems[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2022, 36(9): 9341-9349. |
| 12 | SUAREZ J, DU Y, ZHU C, et al. The neural MMO platform for massively multi-agent research[C]// Proceedings of Thirty-Fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 1). [S.l.:s.n.], 2021. |
| 13 | LONG Q, ZHOU Z, GUPTA A, et al. Evolutionary population curriculum for scaling multi-agent reinforcement learning[C]// Proceedings of International Conference on Learning Representations. Addis Ababa:[s.n.], 2019. |
| 14 | QU G N, WIERMAN A, LI N. Scalable reinforcement learning for multi-agent networked systems[J]. Operations Research, 2022, 70(6): 3601-3628. |
| 15 | TAMPUU A, MATIISEN T, KODELJA D, et al. Multi-agent cooperation and competition with deep reinforcement learning[J]. PloS One, 2017, 12(4): e0172395. |
| 16 | LEIBO J Z, PEROLAT J, HUGHES E, et al. Malthusian reinforcement learning[C]//Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems. [S.l.:s.n.], 2019: 1099-1107. |
| 17 | LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6382-6393. |
| 18 | PALMER G, TUYLS K, BLOEMBERGEN D, et al. Lenient multi-agent deep reinforcement learning[C]// Proceedings of AAMAS. International Foundation for Autonomous Agents and Multi-Agent Systems Richland. [S.l.:s.n.], 2018: 443-451. |
| 19 | FOERSTER J, FARQUHAR G, AFOURAS T, et al. Counterfactual multi-agent policy gradients[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2018, 32(1): 2974-2982. |
| 20 | SUNEHAG P, LEVER G, GRUSLYS A, et al. Value-decomposition networks for cooperative multi-agent learning based on team reward[C]//Proceedings of the 17th International Conference on Autonomous Agents and Multi-Agent Systems. New York: ACM, 2018: 2085-2087. |
| 21 | RASHID T, SAMVELYAN M, SCHROEDER C, et al. QMIX: monotonic value function factorisation for deep multi-agent reinforcement learning[C]//Proceedings of International Conference on Machine Learning. New York: PMLR, 2018: 4295-4304. |
| 22 | FOERSTER J N, ASSAEL Y M, DE FREITAS N, et al. Learning to communicate with deep multi-agent reinforcement learning[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 2145-2153. |
| 23 | UKHBAATAR S, SZLAM A, FERGUS R. Learning multi-agent communication with backpropagation[C]//Proceedings of the 30th International Conference on Neural Information Processing Systems. New York: ACM, 2016: 2252-2260. |
| 24 | PENG P, WEN Y, YANG Y, et al. Multi-agent bidirectionally-coordinated nets: emergence of human-level coordination in learning to play starcraft combat games [EB]. arXiv preprint, arXiv:. |
| 25 | HE H, BOYD-GRABER J, KWOK K, et al. Opponent modeling in deep reinforcement learning[C]//Proceedings of the 33rd International Conference on International Conference on Machine Learning - Volume 48. New York: ACM, 2016: 1804-1813. |
| 26 | FOERSTER J, CHEN R Y, AL-SHEDIVAT M, et al. Learning with opponent-learning awareness[C]//Proceedings of the 17th International Conference on Autonomous Agents and Multi-Agent Systems. New York: ACM, 2018: 122-130. |
| 27 | RABINOWITZ N, PERBET F, SONG F, et al. Machine theory of mind[C]//Proceedings of International Conference on Machine Learning. New York: PMLR, 2018: 4218-4227. |
| 28 | LI S H, WU Y, CUI X Y, et al. Robust multi-agent reinforcement learning via minimax deep deterministic policy gradient[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019, 33(1): 4213-4220. |
| 29 | LOWE R, WU Y, TAMAR A, et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. New York: ACM, 2017: 6382-6393. |
| 30 | MAO H Y, ZHANG Z C, XIAO Z, et al. Modelling the dynamic joint policy of teammates with attention multi-agent DDPG[C]//Proceedings of the 18th International Conference on Autonomous Agents and Multi-Agent Systems. New York: ACM, 2019: 1108-1116. |
| 31 | 熊丽琴, 曹雷, 赖俊, 等. 基于值分解的多智能体深度强化学习综述[J]. 计算机科学, 2022, 49(9): 172-182. |
| XIONG L Q, CAO L, LAI J, et al. Overview of multi-agent deep reinforcement learning based on value factorization[J]. Computer Science, 2022, 49(9):172-182. | |
| 32 | GUESTRIN C, KOLLER D, PARR R. Multi-agent planning with factored MDPs[C]// Proceedings of the 14th International Conference on Neural Information Processing Systems: Natural and Synthetic. [S.l.:s.n.], 2001: 1523-1530. |
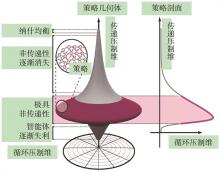
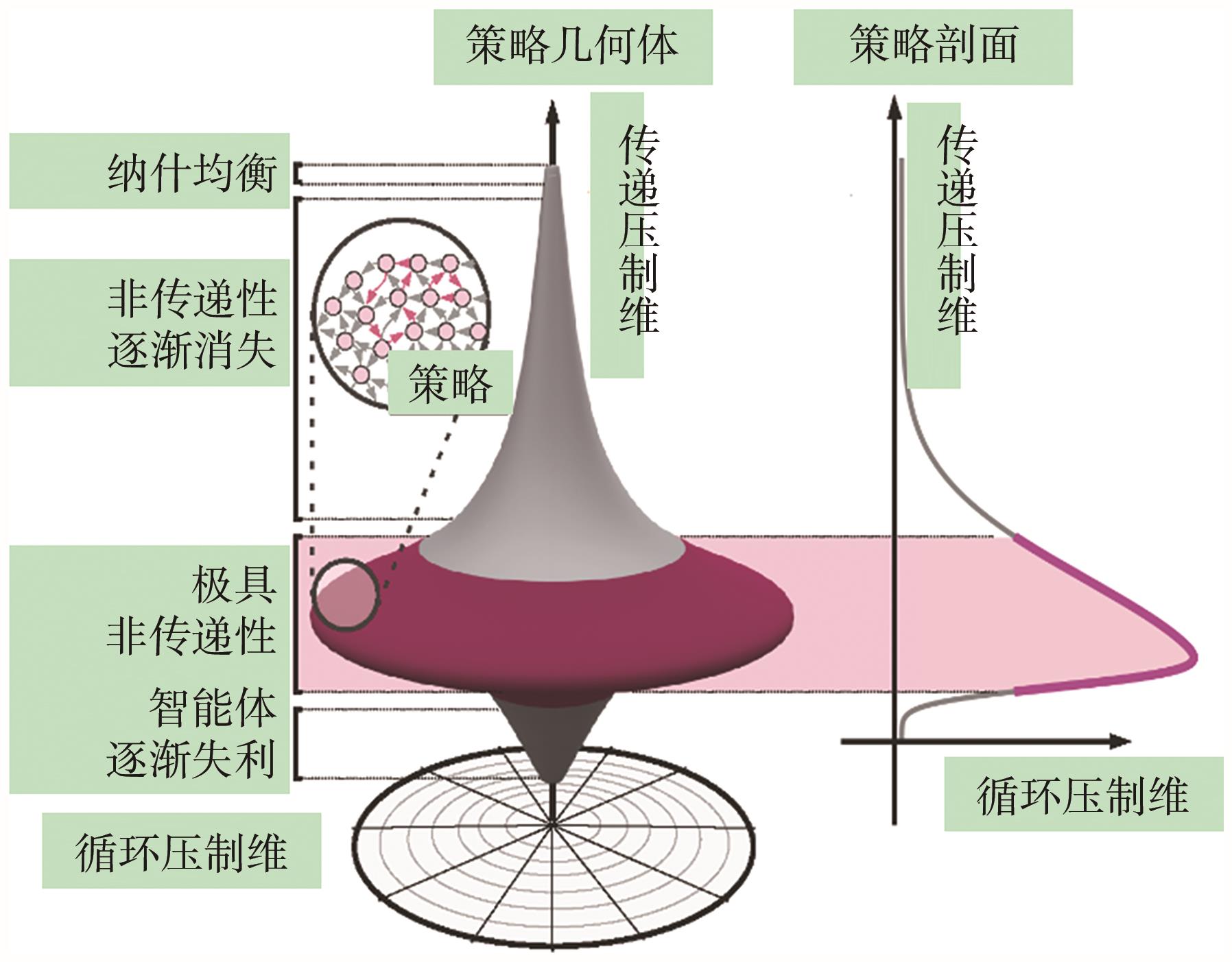
| 33 | CZARNECKI W M, GIDEL G, TRACEY B, et al. Real world games look like spinning tops[C]//Proceedings of the 34th International Conference on Neural Information Processing Systems. New York: ACM, 2020: 17443-17454. |
| 34 | YIN Q, YU T, SHEN S, et al. Distributed deep reinforcement learning: a survey and a multi-player multi-agent learning toolbox [EB]. arXiv preprint, 2022, arXiv:. |
| 35 | ZAHEER M, KOTTUR S, RAVANBHAKHSH S, et al. Deep sets[C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. [S.l.:s.n.], 2017: 3394-3404. |
| 36 | HUEGLE M, KALWEIT G, MIRCHEVSKA B, et al. Dynamic input for deep reinforcement learning in autonomous driving[C]// IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway: IEEE, 2019:7566-7573. |
| 37 | SHI G Y, H?NIG W, YUE Y S, et al. Neural-swarm: decentralized close-proximity multirotor control using learned interactions[C]//Proceedings of 2020 IEEE International Conference on Robotics and Automation (ICRA). Piscataway: IEEE Press, 2020: 3241-3247. |
| 38 | SHI G, H?NIG W, SHI X, et al. Neural-swarm2: planning and control of heterogeneous multirotor swarms using learned interactions[J]. IEEE Transactions on Robotics, 2021, 38(2): 3098436. |
| 39 | LI Y, WANG L, YANG J, et al. Permutation invariant policy optimization for mean-field multi-agent reinforcement learning: a principled approach [EB]. arXiv preprint, 2021, arXiv:. |
| 40 | LIU X, TAN Y. Attentive relational state representation in decentralized multi-agent reinforcement learning[J]. IEEE Transactions on Cybernetics, 2022, 52(1): 252-264. |
| 41 | IQBAL S, WITT C D, PENG B, et al. Randomized entity-wise factorization for multi-agent reinforcement learning[C]// Proceedings of International Conference on Machine Learning (ICML). New York: PMLR, 2021: 4596-4606. |
| 42 | BATRA S, HUANG Z, PETRENKO A, et al. Decentralized control of quadrotor swarms with end-to-end deep reinforcement learning[EB]. arXiv preprint, 2021, arXiv:. |
| 43 | HU S, ZHU F, CHANG X, et al. UPDeT: universal multi-agent reinforcement learning via policy decoupling with transformers[C]// Proceedings of International Conference on Learning Representations (ICLR). [S.l.:s.n.], 2021. |
| 44 | ZHOU T, ZHANG F, SHAO K, et al. Cooperative multi-agent transfer learning with level-adaptive credit assignment [EB]. arXiv preprint, 2021, arXiv:. |
| 45 | NAIR R, VARAKANTHAM P, TAMBE M, et al. Networked distributed POMDPs: a synthesis of distributed constraint optimization and POMDPs[C]// Proceedings of the 20th National Conference on Artificial Intelligence-Volume 1. New York: ACM, 2005: 133-139. |
| 46 | OLIEHOEK F A, WHITESON S, SPAAN M T J. Approximate solutions for factored dec-POMDPs with many agents[C]// Proceedings of the 2013 International Conference on Autonomous Agents and Multi-Agent Systems. New York: ACM, 2013: 563-570. |
| 47 | LIU I J, YEH R A, Schwing A G. PIC: permutation invariant critic for multi-agent deep reinforcement learning[C]// Conference on Robot Learning (CoRL). New York: PMLR, 2020: 590-602. |
| 48 | WANG W, YANG T, LIU Y, et al. From few to more: large-scale dynamic multi-agent curriculum learning[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 7293-7300. |
| 49 | NADERIALIZADEH N, HUNG F H, Soleyman S, et al. Graph convolutional value decomposition in multi-agent reinforcement learning [EB]. arXiv preprint, 2020, arXiv:. |
| 50 | RYU H, SHIN H, PARK J. Multi-agent actor-critic with hierarchical graph attention network[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 7236-7243. |
| 51 | YE Z H, WANG K, CHEN Y N, et al. Multi-UAV navigation for partially observable communication coverage by graph reinforcement learning[J]. IEEE Transactions on Mobile Computing, 2023, 22(7): 4056-4069. |
| 52 | B?HMER W, KURIN V, WHITESON S. Deep coordination graphs[C]// Proceedings of International Conference on Machine Learning. New York: PMLR, 2020: 980-991. |
| 53 | BAI Y, GONG C, ZHANG B, et al. Value function factorisation with hypergraph convolution for cooperative multi-agent reinforcement learning [EB]. arXiv preprint, 2021, arXiv:. |
| 54 | OLIEHOEK F A, SPAAN M T J, WHITESON S, et al. Exploiting locality of interaction in factored dec-POMDPs[C]// Proceedings of the 7th International Joint Conference on Autonomous Agents and Multi-Agent Systems. [S.l.:s.n.], 2008: 517-524. |
| 55 | YANG Y, LUO R, LI M, et al. Mean field multi-agent reinforcement learning[C]// Proceedings of International Conference on Machine Learning (ICML). New York: PMLR, 2018: 5571-5580. |
| 56 | LAURIèRE M, PERRIN S, GIRGIN S, et al. Scalable deep reinforcement learning algorithms for mean field games[C]// Proceedings of the Thirty-Ninth International Conference on Machine Learning. [S.l.:s.n.], 2022:12078-12095. |
| 57 | CAINES P E, HUANG M Y. Graphon mean field games and the GMFG equations: ε-Nash equilibria[C]//Proceedings of 2019 IEEE 58th Conference on Decision and Control (CDC). Piscataway: IEEE Press, 2019: 286-292. |
| 58 | GU H, GUO X, WEI X, et al. Mean-field controls with Q-learning for cooperative MARL: convergence and complexity analysis[J]. SIAM Journal on Mathematics of Data Science, 2021, 3(4): 1168-1196. |
| 59 | LEE K H, NACHUM O, YANG M, et al. Multi-game decision transformers [EB]. arXiv preprint, 2022, arXiv:. |
| 60 | QIN R, CHEN F, WANG T, et al. Multi-agent policy transfer via task relationship modeling [J]. arXiv preprint, 2022, arXiv:. |
| 61 | ZHAO J, HU X, YANG M, et al. CTDS: centralized teacher with decentralized student for multi-agent reinforcement learning [EB]. arXiv preprint, 2022, arXiv:. |
| 62 | JIA H T, REN C X, HU Y J, et al. Mastering basketball with deep reinforcement learning: an integrated curriculum training approach[C]//Proceedings of the 19th International Conference on Autonomous Agents and Multi-Agent Systems. New York: ACM, 2020: 1872-1874. |
| 63 | PORTELAS R, COLAS C, WENG L, et al. Automatic curriculum learning for deep RL: a short survey[C]// Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence. [S.l.:s.n.], 2021: 4819-4825. |
| 64 | LI L, YANG R, LUO D. FOCAL: efficient fully-offline meta-reinforcement learning via distance metric learning and behavior regularization[C]// Proceedings of International Conference on Learning Representations. [S.l.:s.n.], 2020. |
| 65 | SHAO J, ZHANG H, JIANG Y, et al. Credit assignment with meta-policy gradient for multi-agent reinforcement learning [EB]. arXiv preprint, 2021, arXiv:. |
| 66 | YOON J, KIM T, DIA O, et al. Bayesian model-agnostic meta-learning[C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. [S.l.:s.n.], 2018: 7343-7353. |
| 67 | MULLER P, OMIDSHAFIEI S, ROWLAND M, et al. A generalized training approach for multi-agent learning[C]// Proceedings of the 8th International Conference on Learning Representations. [S.l.:s.n.], 2020: 1-35. |
| 68 | MCALEER S, LANIER J, FOX R, et al. Pipeline PSRO: a scalable approach for finding approximate Nash equilibria in large games[C]// Proceedings of Advances in Neural Information Processing Systems. [S.l.:s.n.], 2020, 33: 20238-20248. |
| 69 | LIU S, LANCTOT M, MARRIS L, et al. Simplex neural population learning: any-mixture bayes-optimality in symmetric zero-sum games [EB]. arXiv preprint, 2022, arXiv:. |
| 70 | FENG X, SLUMBERS O, YANG Y, et al. Neural auto-curricula in two-player zero-sum games[C]// Proceedings of the Thirty-Fifth Conference on Neural Information Processing Systems. [S.l.:s.n.], 2021: 3504-3517. |
| 71 | LI S, WANG X, CERNY J, et al. Offline equilibrium finding [EB]. arXiv preprint, 2022, arXiv:. |
| 72 | DINH L C, YANG Y, TIAN Z, et al. Online double oracle [EB]. arXiv preprint, 2021, arXiv:. |
| 73 | MCALEER S, WANG K, LANCTOT M, et al. Anytime optimal PSRO for two-player zero-sum games [EB]. arXiv preprint, 2022, arXiv:. |
| 74 | MCALEER S, LANIER J B, WANG K, et al. Self-play PSRO: toward optimal populations in two-player zero-sum games [EB]. arXiv preprint, 2022, arXiv:. |
| 75 | ZHOU M, WAN Z, WANG H, et al. Malib: a parallel framework for population-based multi-agent reinforcement learning [EB]. arXiv preprint, 2021, arXiv:. |
| 76 | SINHA A, MALO P, DEB K. A review on bilevel optimization: from classical to evolutionary approaches and applications[J]. IEEE Transactions on Evolutionary Computation, 2017, 22(2): 276-295. |
| 77 | CHEN L S, JOSE S T, NIKOLOSKA I, et al. Learning with limited samples: meta-learning and applications to communication systems[J]. Foundations and Trends? in Signal Processing, 2023, 17(2): 79-208. |
| 78 | ZHANG H F, CHEN W Z, HUANG Z R, et al. Bi-level actor-critic for multi-agent coordination[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020, 34(5): 7325-7332. |
| 79 | 李智, 吕铁鑫, 潘艳辉. 联合全域作战智能博弈优化一体化决策问题[J]. 火力与指挥控制, 2023, 48(3):1-8. |
| LI Z, LYU T X, PAN Y H. Research on integrated decision-making problems of intelligent game optimization in JADO[J]. Fire Control& Command Control, 2023, 48(3):1-8. | |
| 80 | BECK J, VUORIO R, LIU E Z, et al. A survey of meta-reinforcement learning [EB]. arXiv preprint, 2023, arXiv:. |
| 81 | CUI K, TAHIR A, EKINCI G, et al. A survey on large-population systems and scalable multi-agent reinforcement learning [EB]. arXiv preprint, 2022, arXiv:. |
| 82 | 黄凯奇, 兴军亮, 张俊格, 等. 人机对抗智能技术[J]. 中国科学: 信息科学, 2020, 50(4): 540-550. |
| HUANG K Q, XING J L, ZHANG J G, et al. Intelligent technology of man-machine confrontation [J]. Science China Information Sciences, 2020, 50(4): 540-550. | |
| 83 | GRAYSON T P, LILLIU S. Mosaic warfare and human–machine symbiosis[J]. Scientific Video Protocols, 2021, 1(1): 1-12. |
| 84 | FLURI L, PALEKA D, TRAMèR F. Evaluating superhuman models with consistency checks [EB]. arXiv preprint, 2023, arXiv:. |
| 85 | MCILROY-YOUNG R, SEN S, KLEINBERG J, et al. Aligning superhuman AI with human behavior: chess as a model system[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. New York: ACM, 2020: 1677-1687. |
| 86 | LIANG J, HE R, TAN T. A comprehensive survey on test-time adaptation under distribution shifts [EB]. arXiv preprint, 2023, arXiv:. |
| 87 | SOKOTA S, FARINA G, WU D J, et al. The update equivalence framework for decision-time planning [EB]. arXiv preprint, 2023, arXiv:. |
| 88 | RAND Corporation. Adaptive engagement for undergoverned spaces: concepts, challenges and prospects for new approaches[R]. 2022. |
| 89 | TEAM A A, BAUER J, BAUMLI K, et al. Human-timescale adaptation in an open-ended task space [EB]. arXiv preprint, 2023, arXiv:. |
| 90 | 王涵,俞扬,姜远. 基于动态自选择参数共享的合作多智能体强化学习算法[J]. 智能科学与技术学报, 2022, 4(1): 75-83. |
| WANG H, YU Y, JIANG Y. A cooperative multi-agent reinforcement learning algorithm based on dynamic self-selection parameters sharing [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(1): 75-83. |
| [1] | Jun HUANG, Yonglin TIAN, Xingyuan DAI, Xiao WANG, Zhixing PING. Deep learning-based multimodal trajectory prediction methods for autonomous driving: state of the art and perspectives [J]. Chinese Journal of Intelligent Science and Technology, 2023, 5(2): 180-199. |
| [2] | Yuanqi QIN, Qingyuan JI, Jun GE, Xingyuan DAI, Yuanyuan CHEN, Xiao WANG. Short-term traffic state reasoning and precise prediction in urban networks [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(3): 380-395. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||