

通信学报 ›› 2023, Vol. 44 ›› Issue (5): 169-180.doi: 10.11959/j.issn.1000-436x.2023095
田有亮1,2,3, 吴柿红1,2, 李沓1,2, 王林冬1,2, 周骅4
修回日期:2023-04-06
出版日期:2023-05-25
发布日期:2023-05-01
作者简介:田有亮(1982- ),男,贵州盘州人,博士,贵州大学教授、博士生导师,主要研究方向为博弈论、密码学与安全协议、大数据隐私保护基金资助:Youliang TIAN1,2,3, Shihong WU1,2, Ta LI1,2, Lindong WANG1,2, Hua ZHOU4
Revised:2023-04-06
Online:2023-05-25
Published:2023-05-01
Supported by:摘要:
针对联邦学习的训练过程迭代次数多、训练时间长、效率低等问题,提出一种基于激励机制的联邦学习优化算法。首先,设计与时间和模型损失相关的信誉值,基于该信誉值,设计激励机制激励拥有高质量数据的客户端加入训练。其次,基于拍卖理论设计拍卖机制,客户端通过向雾节点拍卖本地训练任务,委托高性能雾节点训练本地数据从而提升本地训练效率,解决客户端间的性能不均衡问题。最后,设计全局梯度聚合策略,增加高精度局部梯度在全局梯度中的权重,剔除恶意客户端,从而减少模型训练次数。
中图分类号:
田有亮, 吴柿红, 李沓, 王林冬, 周骅. 基于激励机制的联邦学习优化算法[J]. 通信学报, 2023, 44(5): 169-180.
Youliang TIAN, Shihong WU, Ta LI, Lindong WANG, Hua ZHOU. Federated learning optimization algorithm based on incentive mechanism[J]. Journal on Communications, 2023, 44(5): 169-180.
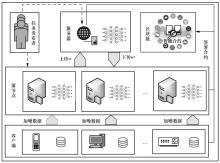
图1
系统模型"
表1
本文涉及的参数和参数描述"
| 参数 | 描述 |
| data_size | 本地训练数据的大小 |
| Pi | 雾节点i竞拍的价格 |
| Ti | 雾节点i一次迭代的时间 |
| cn | 执行一个数据样本的CPU周期数 |
| fi | 设备i的频率 |
| 客户端i用于计算的能量消耗 | |
| 客户端i在第n轮训练后的模型损失 | |
| 第n轮训练后的平均模型损失 | |
| d | 任务发布者与客户端签署合约需要交纳的押金 |
| r | 客户端与雾节点签署合约需要交纳的押金 |
| taskx | 任务x |
| curret_task | 当前任务 |
| 客户端i的第 j轮训练梯度 | |
| wj | 第 j轮训练的全局梯度 |
| Tex | 任务发布者期望的总训练时间 |
| Tr | 实际训练的总时间 |
| t ji | 客户端i在第 j轮训练所用的时间 |

图2
拍卖过程"

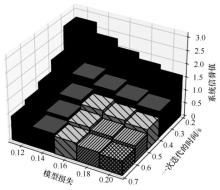
图3
模型损失、一次迭代的时间以及系统信誉值之间的关系"
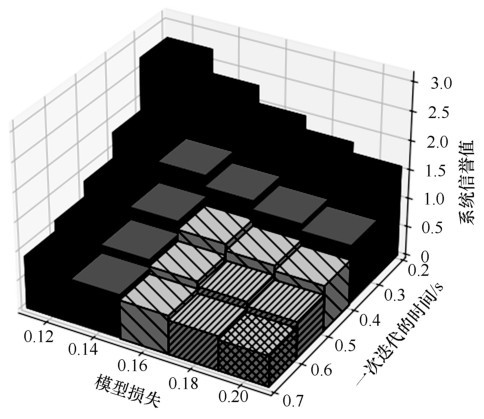
表2
20轮训练后方案所能达到的精度"
| 方案 | MNIST | CIFAR-10 |
| 本文方案 | 96.3% | 96.1% |
| FAIR方案 | 51.8% | 51.8% |
表3
20轮训练后方案所需要的时间"
| 方案 | MNIST/s | CIFAR-10/s |
| 本文方案 | 421.4 | 391.58 |
| FAIR方案 | 611.4 | 568.85 |
表4
达到指定精度所需的训练轮次"
| 方案 | MNIST(96%)/轮 | CIFAR-10(60%)/轮 |
| 本文方案 | 16 | 86 |
| FedAvg方案 | 20 | 98 |
| FAIR方案 | 17 | 91 |
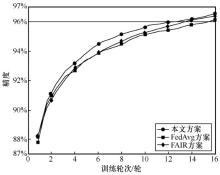
图4
MNIST数据集达到指定精度的训练轮次"
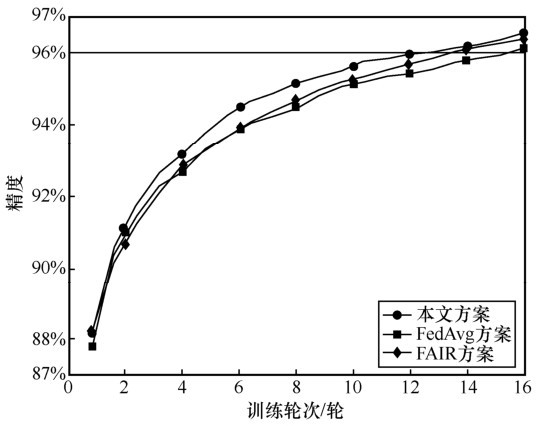
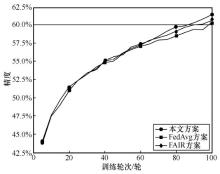
图5
CIFAR-10数据集达到指定精度的训练轮次"
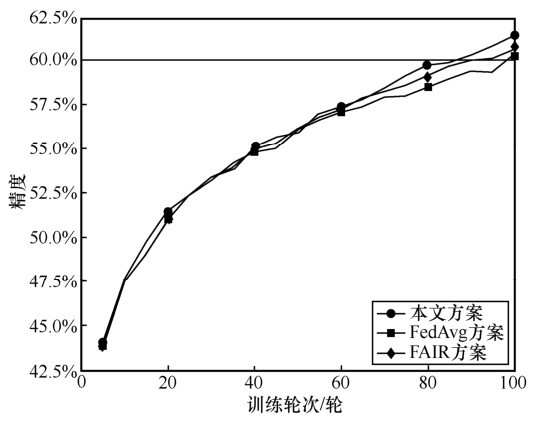

图6
MNIST数据集一次迭代的时间"
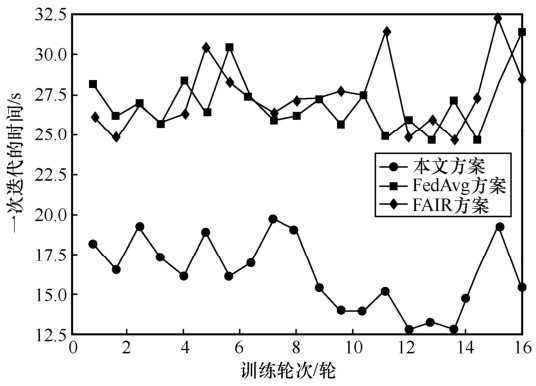
图7
CIFAR-10数据集一次迭代的时间"
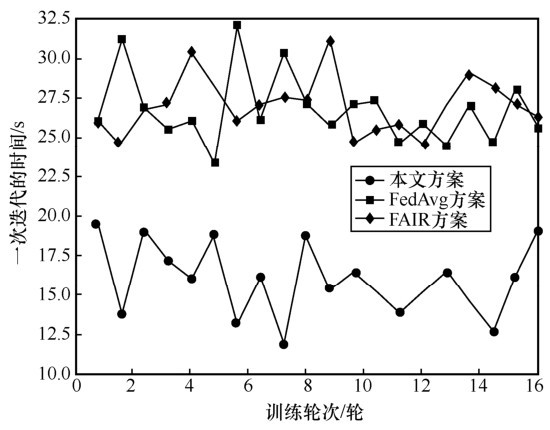
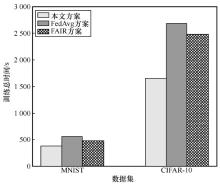
图8
完成指定精度的训练总时间"
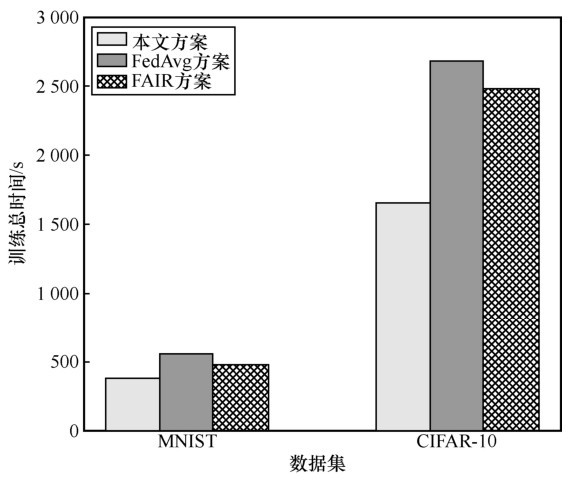
表5
训练总时间"
| 方案 | MNIST/s | CIFAR-10/s |
| 本文方案 | 296.03+ | 1 579.82+ |
| FedAvg方案 | 550.37 | 2 682.26 |
| FAIR方案 | 467.92 | 2 490.69 |
表6
性能对比"
| 方案 | 客户端激励 | 流浪者效应 | 聚合策略 |
| FedPA方案 | × | √ | × |
| FedAvg方案 | × | × | × |
| FAIR方案 | √ | × | √ |
| 本文方案 | √ | √ | √ |
| [1] | GE Z Q , SONG Z H , DING S X ,et al. Data mining and analytics in the process industry:the role of machine learning[J]. IEEE Access, 2017,5: 20590-20616. |
| [2] | MOHASSEL P , ZHANG Y P . Secure ML:a system for scalable privacy-preserving machine learning[C]// Proceedings of 2017 IEEE Symposium on Security and Privacy (SP). Piscataway:IEEE Press, 2017: 19-38. |
| [3] | ZHANG Y , XU C X , LI H W ,et al. HealthDep:an efficient and secure deduplication scheme for cloud-assisted eHealth systems[J]. IEEE Transactions on Industrial Informatics, 2018,14(9): 4101-4112. |
| [4] | AHISKA K , OZGOREN M K , LEBLEBICIOGLU M K . Autopilot design for vehicle cornering through icy roads[J]. IEEE Transactions on Vehicular Technology, 2018,67(3): 1867-1880. |
| [5] | YANG Q , LIU Y , CHEN T J ,et al. Federated machine learning:concept and applications[J]. ACM Transactions on Intelligent Systems and Technology, 2019,10(2): 1-19. |
| [6] | PANDEY S R , TRAN N H , BENNIS M ,et al. A crowdsourcing framework for on-device federated learning[J]. IEEE Transactions on Wireless Communications, 2020,19(5): 3241-3256. |
| [7] | ZHAN Y F , LI P , QU Z H ,et al. A learning-based incentive mechanism for federated learning[J]. IEEE Internet of Things Journal, 2020,7(7): 6360-6368. |
| [8] | LIU J , WANG J H , PONG C ,et al. FedPA:an adaptively partial model aggregation strategy in Federated Learning[J]. Computer Networks, 2021,199:108468. |
| [9] | MCMAHAN H B , MOORE E , RAMAGE D ,et al. Communication-efficient learning of deep networks from decentralized data[J]. arXiv Preprint,arXiv:1602.05629, 2016. |
| [10] | BONOMI F , MILITO R , ZHU J ,et al. Fog computing and its role in the Internet of things[C]// Proceedings of the First Edition of the MCC Workshop on Mobile Cloud Computing. New York:ACM Press, 2012: 13-16. |
| [11] | LI Y J , TAO X F , ZHANG X F ,et al. Privacy-preserved federated learning for autonomous driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2022,23(7): 8423-8434. |
| [12] | KIM H , PARK J , BENNIS M ,et al. Blockchained on-device federated learning[J]. IEEE Communications Letters, 2020,24(6): 1279-1283. |
| [13] | 陈明鑫, 张钧波, 李天瑞 . 联邦学习攻防研究综述[J]. 计算机科学, 2022,49(7): 310-323. |
| CHEN M X , ZHANG J B , LI T R . Survey on attacks and defenses in federated learning[J]. Computer Science, 2022,49(7): 310-323. | |
| [14] | LI Y P , COURCOUBETIS C , DUAN L J . Recommending paths:follow or not follow?[C]// Proceedings of IEEE Conference on Computer Communications. Piscataway:IEEE Press, 2019: 928-936. |
| [15] | KANG J W , XIONG Z H , NIYATO D ,et al. Incentive mechanism for reliable federated learning:a joint optimization approach to combining reputation and contract theory[J]. IEEE Internet of Things Journal, 2019,6(6): 10700-10714. |
| [16] | ZENG R F , ZHANG S X , WANG J Q ,et al. FMore:an incentive scheme of multi-dimensional auction for federated learning in MEC[C]// Proceedings of 2020 IEEE 40th International Conference on Distributed Computing Systems (ICDCS). Piscataway:IEEE Press, 2021: 278-288. |
| [17] | DENG Y H , LYU F , REN J ,et al. FAIR:quality-aware federated learning with precise user incentive and model aggregation[C]// Proceedings of IEEE Conference on Computer Communications. Piscataway:IEEE Press, 2021: 1-10. |
| [18] | LIAN X R , HUANG Y J , LI Y C ,et al. Asynchronous parallel stochastic gradient for nonconvex optimization[C]// Proceedings of the 28th International Conference on Neural Information Processing Systems. New York:ACM Press, 2015: 2737-2745. |
| [19] | DAI W , KUMAR A , WEI J L ,et al. High-performance distributed ML at scale through parameter server consistency models[C]// Proceedings of the AAAI Conference on Artificial Intelligence. Palo Alto:AAAI Press, 2015: 79-87. |
| [20] | NIU F , RECHT B , RE C ,et al. HOGWILD!:a lock-free approach to parallelizing stochastic gradient descent[J]. Advances in Neural Information Processing Systems, 2011,24: 693-701. |
| [21] | NISHIO T , YONETANI R . Client selection for federated learning with heterogeneous resources in mobile edge[C]// Proceedings of 2019 IEEE International Conference on Communications (ICC). Piscataway:IEEE Press, 2019: 1-7. |
| [22] | 余佳仁, 田有亮, 林晖 . 基于信誉管理模型的矿工类型鉴别机制设计[J]. 网络与信息安全学报, 2022,8(1): 128-138. |
| YU J R , TIAN Y L , LIN H . Design of miner type identification mechanism based on reputation management model[J]. Chinese Journal of Network and Information Security, 2022,8(1): 128-138. | |
| [23] | 王勇, 李国良, 李开宇 . 联邦学习贡献评估综述[J]. 软件学报, 2023,34(3): 1168-1192. |
| WANG Y , LI G L , LI K Y . Survey on contribution evaluation for federated learning[J]. Journal of Software, 2023,34(3): 1168-1192. | |
| [24] | XU G W , LI H W , LIU S ,et al. VerifyNet:secure and verifiable federated learning[J]. IEEE Transactions on Information Forensics and Security, 2020,15: 911-926. |
| [25] | WANG S Q , TUOR T , SALONIDIS T ,et al. When edge meets learning:adaptive control for resource-constrained distributed machine learning[C]// Proceedings of IEEE 2018 IEEE Conference on Computer Communications. Piscataway:IEEE Press, 2018: 63-71. |
| [26] | ZHENG S Y , CAO Y , YOSHIKAWA M . Incentive mechanism for privacy-preserving federated learning[J]. arXiv Preprint,arXiv:2106.04384, 2021. |
| [27] | MIAO Y B , LIU Z T , LI H W ,et al. Privacy-preserving Byzantine-robust federated learning via blockchain systems[J]. IEEE Transactions on Information Forensics and Security, 2022,17: 2848-2861. |
| [28] | XIONG L , LIU L . PeerTrust:supporting reputation-based trust for peer-to-peer electronic communities[J]. IEEE Transactions on Knowledge and Data Engineering, 2004,16(7): 843-857. |
| [29] | HUANG C Y , WANG Z Y , CHEN H X ,et al. RepChain:a reputation-based secure,fast,and high incentive blockchain system via sharding[J]. IEEE Internet of Things Journal, 2021,8(6): 4291-4304. |
| [30] | TRAN N H , BAO W , ZOMAYA A ,et al. Federated learning over wireless networks:optimization model design and analysis[C]// Proceedings of 2019 IEEE Conference on Computer Communications. Piscataway:IEEE Press, 2019: 1387-1395. |
| [31] | ABDALI T A N , HASSAN R , AMAN A H M ,et al. Fog computing advancement:concept,architecture,applications,advantages,and open issues[J]. IEEE Access, 2021,9: 75961-75980. |
| [32] | ZHOU C Y , FU A M , YU S ,et al. Privacy-preserving federated learning in fog computing[J]. IEEE Internet of Things Journal, 2020,7(11): 10782-10793. |
| [33] | WAN C B , JIN F S , QIAO Z ,et al. Unsupervised active learning with loss prediction[J]. Neural Computing and Applications, 2023,35(5): 3587-3595. |
| [34] | FU A M , ZHANG X L , XIONG N X ,et al. VFL:a verifiable federated learning with privacy-preserving for big data in industrial IoT[J]. IEEE Transactions on Industrial Informatics, 2022,18(5): 3316-3326. |
| [1] | 马鑫迪, 李清华, 姜奇, 马卓, 高胜, 田有亮, 马建峰. 面向Non-IID数据的拜占庭鲁棒联邦学习[J]. 通信学报, 2023, 44(6): 138-153. |
| [2] | 金彪, 李逸康, 姚志强, 陈瑜霖, 熊金波. GenFedRL:面向深度强化学习智能体的通用联邦强化学习框架[J]. 通信学报, 2023, 44(6): 183-197. |
| [3] | 李开菊, 许强, 王豪. 冗余数据去除的联邦学习高效通信方法[J]. 通信学报, 2023, 44(5): 79-93. |
| [4] | 余晟兴, 陈泽凯, 陈钟, 刘西蒙. DAGUARD:联邦学习下的分布式后门攻击防御方案[J]. 通信学报, 2023, 44(5): 110-122. |
| [5] | 姜慧, 何天流, 刘敏, 孙胜, 王煜炜. 面向异构流式数据的高性能联邦持续学习算法[J]. 通信学报, 2023, 44(5): 123-136. |
| [6] | 张佳乐, 朱诚诚, 孙小兵, 陈兵. 基于GAN的联邦学习成员推理攻击与防御方法[J]. 通信学报, 2023, 44(5): 193-205. |
| [7] | 余晟兴, 陈钟. 基于同态加密的高效安全联邦学习聚合框架[J]. 通信学报, 2023, 44(1): 14-28. |
| [8] | 汤凌韬, 王迪, 刘盛云. 面向非独立同分布数据的联邦学习数据增强方案[J]. 通信学报, 2023, 44(1): 164-176. |
| [9] | 范绍帅, 吴剑波, 田辉. 面向能量受限工业物联网设备的联邦学习资源管理[J]. 通信学报, 2022, 43(8): 65-77. |
| [10] | 莫梓嘉, 高志鹏, 杨杨, 林怡静, 孙山, 赵晨. 面向车联网数据隐私保护的高效分布式模型共享策略[J]. 通信学报, 2022, 43(4): 83-94. |
| [11] | 康海燕, 冀源蕊. 基于本地化差分隐私的联邦学习方法研究[J]. 通信学报, 2022, 43(10): 94-105. |
| [12] | 陶梅霞, 王栋, 孙瑞, 张乃夫. 联邦学习中基于时分多址接入的用户调度策略[J]. 通信学报, 2021, 42(6): 1-29. |
| [13] | 贺文晨, 郭少勇, 邱雪松, 陈连栋, 张素香. 基于DRL的联邦学习节点选择方法[J]. 通信学报, 2021, 42(6): 62-71. |
| [14] | 李尤慧子, 殷昱煜, 高洪皓, 金一, 王新珩. 面向隐私保护的非聚合式数据共享综述[J]. 通信学报, 2021, 42(6): 195-212. |
| [15] | 黄永明, 郑冲, 张征明, 尤肖虎. 大规模无线通信网络移动边缘计算和缓存研究[J]. 通信学报, 2021, 42(4): 44-61. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||