

通信学报 ›› 2023, Vol. 44 ›› Issue (1): 164-176.doi: 10.11959/j.issn.1000-436x.2023007
汤凌韬1, 王迪1, 刘盛云2
修回日期:2022-11-16
出版日期:2023-01-25
发布日期:2023-01-01
作者简介:汤凌韬(1994- ),男,江苏启东人,数学工程与先进计算国家重点实验室博士生,主要研究方向为信息安全、机器学习和隐私保护等基金资助:Lingtao TANG1, Di WANG1, Shengyun LIU2
Revised:2022-11-16
Online:2023-01-25
Published:2023-01-01
Supported by:摘要:
为了解决联邦学习节点间数据非独立同分布(non-IID)导致的模型精度不理想的问题,提出一种隐私保护的数据增强方案。首先,提出了面向联邦学习的数据增强框架,参与节点在本地生成虚拟样本并在节点间共享,有效缓解了训练过程中数据分布差异导致的模型偏移问题。其次,基于生成式对抗网络和差分隐私技术,设计了隐私保护的样本生成算法,在保证原数据隐私的前提下生成可用的虚拟样本。最后,提出了隐私保护的标签选取算法,保证虚拟样本的标签同样满足差分隐私。仿真结果表明,在多种 non-IID 数据划分策略下,所提方案均能有效提高模型精度并加快模型收敛,与基准方法相比,所提方案在极端non-IID场景下能取得25%以上的精度提升。
中图分类号:
汤凌韬, 王迪, 刘盛云. 面向非独立同分布数据的联邦学习数据增强方案[J]. 通信学报, 2023, 44(1): 164-176.
Lingtao TANG, Di WANG, Shengyun LIU. Data augmentation scheme for federated learning with non-IID data[J]. Journal on Communications, 2023, 44(1): 164-176.
表1
系统参数及含义"
| 参数 | 含义 |
| S | 中央服务器 |
| Ci,Di | 第i个客户端节点及其本地数据集 |
| γ | 客户端虚拟样本共享比例 |
| mi | C i 共享的虚拟样本数目 |
| Ui | D i中所有样本的对应标签集合 |
| L | 全局样本类别总数 |
| 真实样本特征及标签 | |
| 虚拟样本特征及标签 | |
| 差分隐私机制的隐私预算 | |
| σ | 差分隐私机制的噪声乘子 |
| c | 训练梯度的剪裁上界 |
| 隐私损失计算函数 | |
| 判别器, 生成器 | |
| B | 一批训练样本的数目 |
图1
方案整体架构"
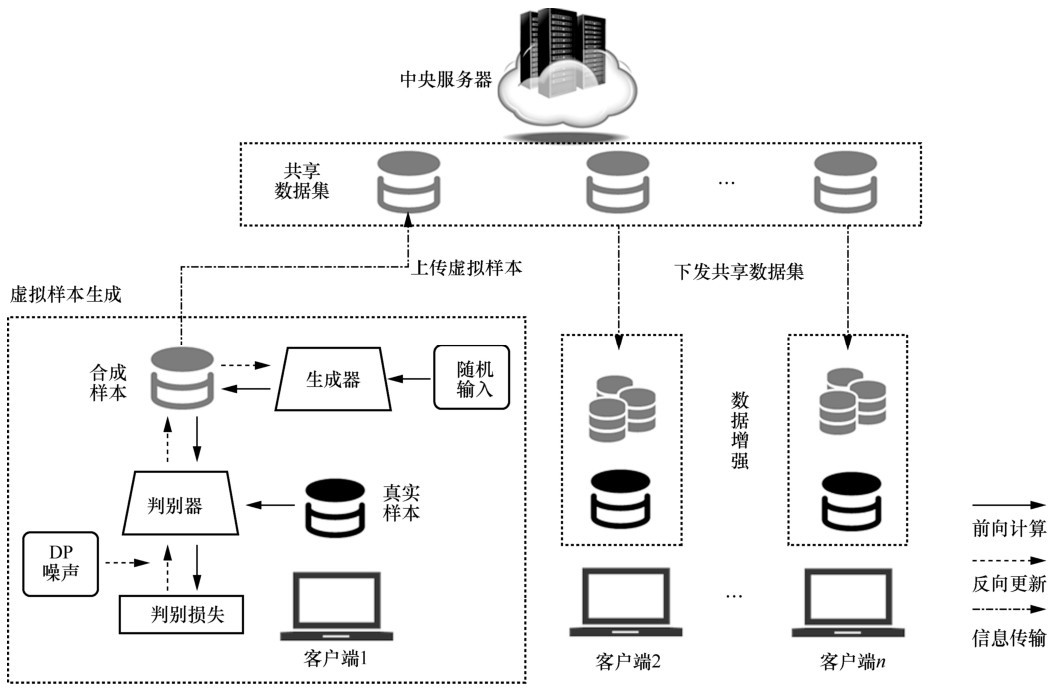

图2
Non-IID数据划分情况"
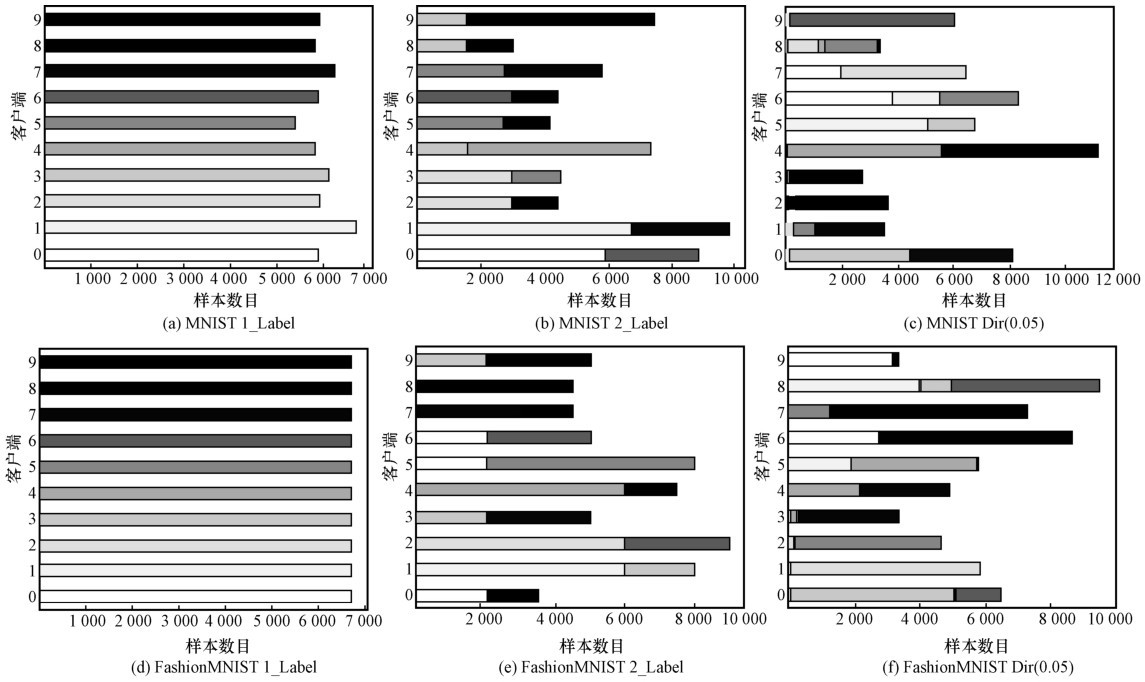

图3
GAN和CNN分类模型的结构"
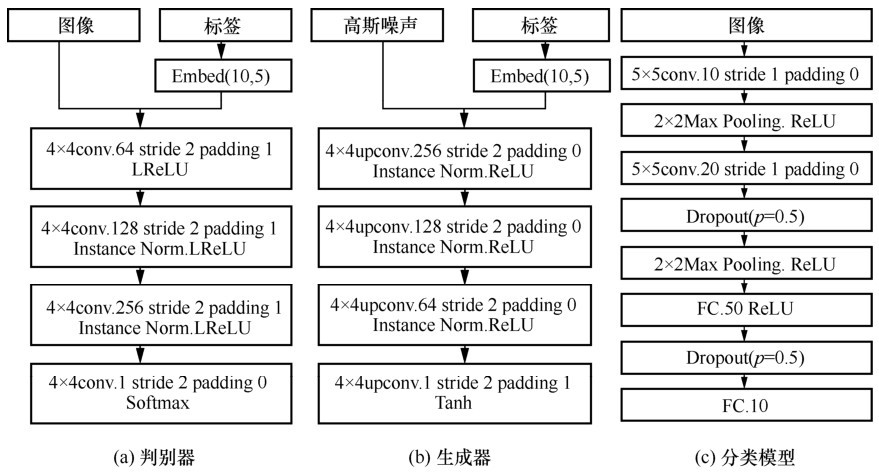
表2
实验参数设置"
| 阶段 | 参数名称 | 参数值 |
| 数据增强阶段 | 虚拟样本共享比例γ | 0.01 |
| GAN预定训练轮数/次 | 50 | |
| Batch Size | 256 | |
| 生成器输入噪声维度 | 10 | |
| 噪声乘子σ | 0.5 | |
| 剪裁上界c | 2 | |
| 隐私预算(ε ,δ) | 50, 0.000 01 | |
| 优化算法 | Adam | |
| 优化器参数(学习率,β1, β2) | 0.0002, 0.5, 0.999 | |
| 联邦学习阶段 | 客户端数/个 | 10 |
| 节点间总通信轮数/次 | 50 | |
| 客户端本地训练轮数/次 | 5 | |
| 每轮参与训练的客户端比例 | 1 | |
| Batch Size | 32 | |
| 优化算法 | SGD | |
| 优化器参数(学习率,动量) | 0.01, 0.5 |
表3
不同方法的模型测试准确率对比"
| 方法 | MNIST | FMNIST | Cifar10 | SVHN | |||||||||
| 1-Label | 2-Label | Dir(0.05) | 1-Label | 2-Label | Dir(0.05) | 1-Label | 2-Label | 1-Label | 2-Label | ||||
| FedAvg[ | 50.44% | 90.99% | 96.63% | 39.13% | 69.92% | 77.58% | 13.99% | 9.69% | 48.48% | ||||
| FedProx[ | 48.56% | 87.56% | 96.32% | 46.48% | 62.39% | 77.46% | 12.28% | 31.46% | 15.53% | ||||
| SCAFFOLD[ | 9.52% | 91.53% | 97.82% | 10.00% | 68.87% | 75.38% | 10.00% | 42.71% | 9.33% | 34.53% | |||
| FedNova[ | 42.40% | 88.86% | 96.96% | 36.47% | 70.13% | 77.38% | 10.73% | 44.97% | 11.16% | 47.76% | |||
| FedMix[ | 23.32% | 65.64% | 91.24% | 36.18% | 51.03% | 64.28% | 9.98% | 43.61% | 19.59% | 44.89% | |||
| 本文方案(γ=0.01) | 75.13% | 93.21% | 97.11% | 75.11% | 44.27% | 21.46% | 51.48% | ||||||
| 本文方案(γ=0.05) | 78.56% | 82.41% | 23.25% | 40.02% | 52.41% | ||||||||
| centralized training | 99.16% | 90.15% | 64.87% | 87.90% | |||||||||

图4
不同方法训练中的模型准确率变化情况"
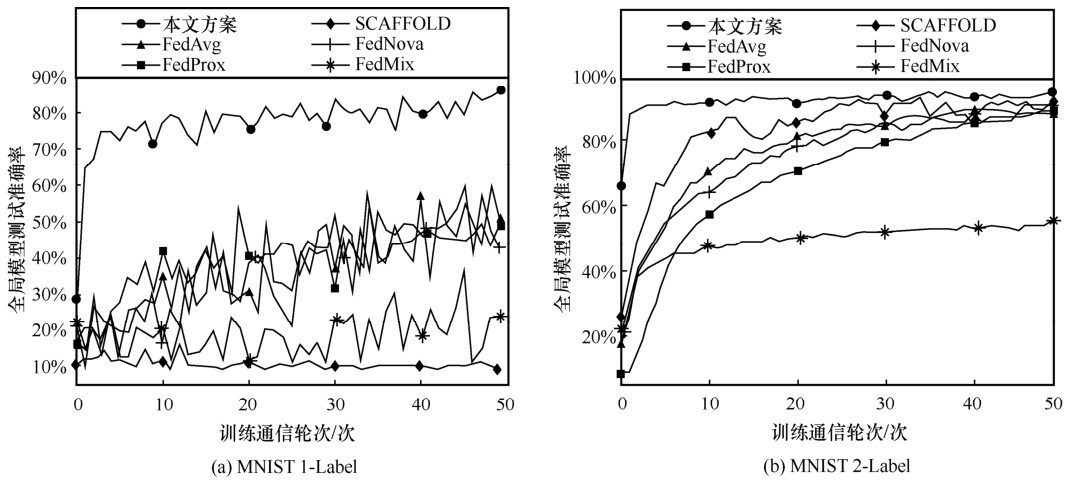
表4
不同隐私预算时的模型准确率"
| ε | 模型准确率 |
| 1 | 58.81% |
| 5 | 74.55% |
| 20 | 75.87% |
| 50 | 75.13% |
| ∞ | 88.33% |

图5
不同隐私预算时的虚拟样本"
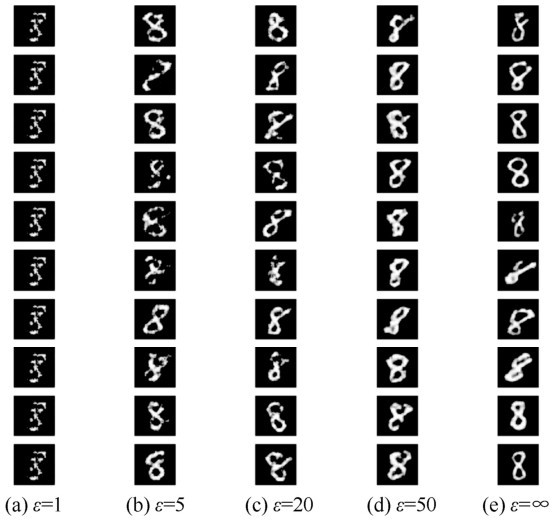
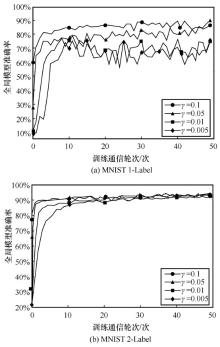
图6
不同样本共享比例的模型准确率变化曲线"
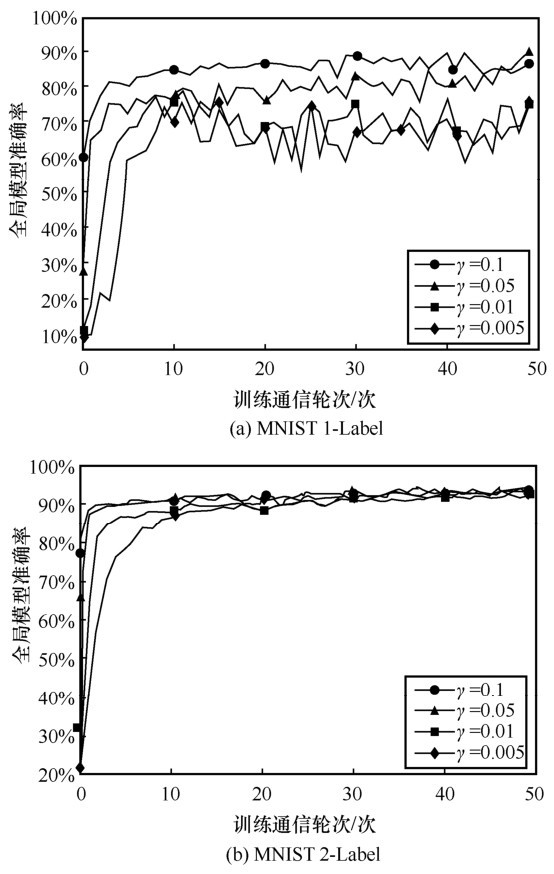
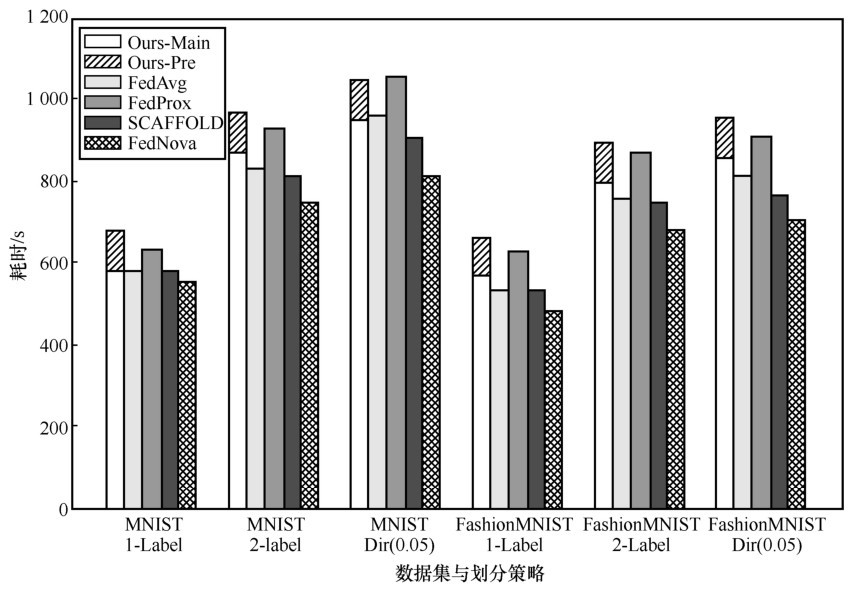
图7
不同方案效率对比"
| [1] | MCMAHAN B , MOORE E , RAMAGE D ,et al. Communication-efficient learning of deep networks from decentralized data[C]// Artificial Intelligence and statistics. New York:PMLR, 2017: 1273-1282. |
| [2] | KONE?NY J , MCMAHAN H B , RAMAGE D ,et al. Federated optimization:distributed machine learning for on-device intelligence[J]. arXiv Preprint,arXiv:1610.02527, 2016. |
| [3] | ZHAO Y , LI M , LAI L Z ,et al. Federated learning with non-IID data[J]. arXiv Preprint,arXiv:1806.00582, 2018. |
| [4] | XU C C , HONG Z W , HUANG M L ,et al. Acceleration of federated learning with alleviated forgetting in local training[J]. arXiv Preprint,arXiv:2203.02645, 2022. |
| [5] | LI Q B , DIAO Y Q , CHEN Q ,et al. Federated learning on non-IID data silos:an experimental study[J]. arXiv Preprint,arXiv:2102.02079, 2021 |
| [6] | LI T , SAHU A K , ZAHEER M ,et al. Federated optimization in heterogeneous networks[J]. arXiv Preprint,arXiv:1812.06127, 2018. |
| [7] | KARIMIREDDY S P , KALE S , MOHRI M ,et al. Scaffold:stochastic controlled averaging for federated learning[C]// International Conference on Machine Learning. New York:PMLR, 2020: 5132-5143. |
| [8] | LUO M , CHEN F , HU D P ,et al. No fear of heterogeneity:classifier calibration for federated learning with non-IID data[C]// Proceedings of the 35th Conference on Neural Information Processing Systems (NeurIPS 2021). Massachusetts:MIT Press, 2021: 1-13. |
| [9] | WANG J Y , LIU Q H , LIANG H ,et al. Tackling the objective in-consistency problem in heterogeneous federated optimization[C]// Proceedings of the 34th Conference on Neural Information Processing Systems (NeurIPS 2020). Massachusetts:MIT Press, 2020: 1-13. |
| [10] | HSU T M H , QI H , BROWN M . Measuring the effects of non-identical data distribution for federated visual classifica-tion[J]. arXiv Preprint,arXiv:1909.06335, 2019. |
| [11] | LIN T , KONG L J , STICH S U ,et al. Ensemble distillation for robust model fusion in federated learning[J]. arXiv Preprint,arXiv:2006.07242, 2020. |
| [12] | GOETZ J , TEWARI A . Federated learning via synthetic data[J]. arXiv Preprint,arXiv:2008.04489, 2020. |
| [13] | HAO W T , EL-KHAMY M , LEE J ,et al. Towards fair federated learning with zero-shot data augmentation[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW). Piscataway:IEEE Press, 2021: 3305-3314. |
| [14] | YOON T , SHIN S , HWANG S J ,et al. FedMix:approximation of mixup under mean augmented federated learning[J]. arXiv Preprint,arXiv:2107.00233, 2021. |
| [15] | FALLAH A , MOKHTARI A , OZDAGLAR A . Personalized federated learning:a meta-learning approach[J]. arXiv Preprint,arXiv:2002.07948, 2020. |
| [16] | SMITH V , CHIANG C K , SANJABI M ,et al. Federated multi-task learning[C]// Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017). Massachusetts:MIT Press, 2017: 1-11. |
| [17] | GHOSH A , CHUNG J , YIN D ,et al. An efficient framework for clustered federated learning[J]. IEEE Transactions on Information Theory, 2022,68(12): 8076-8091. |
| [18] | WAHEED A , GOYAL M , GUPTA D ,et al. CovidGAN:data augmentation using auxiliary classifier GAN for improved COVID-19 detection[J]. IEEE Access, 2020,8: 91916-91923. |
| [19] | SHOKRI R , STRONATI M , SONG C Z ,et al. Membership inference attacks against machine learning models[C]// Proceedings of 2017 IEEE Symposium on Security and Privacy. Piscataway:IEEE Press, 2017: 3-18. |
| [20] | CHEN D F , YU N , ZHANG Y ,et al. GAN-leaks:a taxonomy of membership inference attacks against generative models[C]// Proceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security. New York:ACM Press, 2020: 343-362. |
| [21] | GOODFELLOW I , POUGET-ABADIE J , MIRZA M ,et al. Generative adversarial nets[C]// Proceedings of the 27th Conference on Neural Information Processing Systems (NeurIPS 2014). Massachusetts:MIT Press, 2014: 2672-2680. |
| [22] | MIRZA M , OSINDERO S . Conditional generative adversarial nets[J]. arXiv Preprint,arXiv:1411.1784, 2014. |
| [23] | RADFORD A , METZ L , CHINTALA S . Unsupervised representation learning with deep convolutional generative adversarial networks[J]. arXiv Preprint,arXiv:1511.06434, 2015. |
| [24] | ARJOVSKY M , CHINTALA S , BOTTOU L . Wasserstein generative adversarial networks[C]// International Conference on Machine Learning. New York:PMLR, 2017: 214-223. |
| [25] | DWORK C , MCSHERRY F , NISSIM K ,et al. Calibrating noise to sensitivity in private data analysis[C]// Theory of Cryptography Conference. Berlin:Springer, 2006: 265-284. |
| [26] | DWORK C , ROTH A . The algorithmic foundations of differential privacy[J]. Foundations and Trends in Theoretical Computer Science, 2013,9(3/4): 211-407. |
| [27] | ABADI M , CHU A , GOODFELLOW I ,et al. Deep learning with differential privacy[C]// Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security. New York:ACM Press, 2016: 308-318. |
| [28] | XIE L Y , LIN K X , WANG S ,et al. Differentially private generative adversarial network[J]. arXiv Preprint,arXiv:1802.06739, 2018. |
| [29] | ZHANG X Y , JI S L , WANG T . Differentially private releasing via deep generative model[J]. arXiv Preprint,arXiv:1801.01594, 2018. |
| [30] | DAVODY A , ADELANI D I , KLEINBAUER T ,et al. Robust differentially private training of deep neural networks[J]. arXiv Preprint,arXiv:2006.10919, 2020. |
| [31] | YOUSEFPOUR A , SHILOV I , SABLAYROLLES A ,et al. Opacus:user-friendly differential privacy library in PyTorch[J]. arXiv Preprint,arXiv:2109.12298, 2021. |
| [32] | ZENG D , LIANG S Q , HU X J ,et al. FedLab:a flexible federated learning framework[J]. arXiv Preprint,arXiv:2107.11621, 2021. |
| [33] | LECUN Y , BOTTOU L , BENGIO Y ,et al. Gradient-based learning applied to document recognition[J]. Proceedings of the IEEE, 1998,86(11): 2278-2324. |
| [34] | XIAO H , RASUL K , VOLLGRAF R . Fashion-MNIST:a novel image dataset for benchmarking machine learning algorithms[J]. arXiv Preprint,arXiv:1708.07747, 2017. |
| [35] | KRIZHEVSKY A . Learning multiple layers of features from tiny images[D]. Toronto:University of Toronto, 2009. |
| [36] | NETZER Y , WANG T , COATES A ,et al. Reading digits in natural images with unsupervised feature learning[C]// Proceedings of the 25th Conference on Neural Information Processing Systems (NIPS 2011). Massachusetts:MIT Press, 2011: 1-9. |
| [37] | MIRONOV I , TALWAR K , ZHANG L . Renyi differential privacy of the sampled gaussian mechanism[J]. arXiv Preprint,arXiv:1908.10530, 2019. |
| [1] | 马鑫迪, 李清华, 姜奇, 马卓, 高胜, 田有亮, 马建峰. 面向Non-IID数据的拜占庭鲁棒联邦学习[J]. 通信学报, 2023, 44(6): 138-153. |
| [2] | 金彪, 李逸康, 姚志强, 陈瑜霖, 熊金波. GenFedRL:面向深度强化学习智能体的通用联邦强化学习框架[J]. 通信学报, 2023, 44(6): 183-197. |
| [3] | 田有亮, 吴柿红, 李沓, 王林冬, 周骅. 基于激励机制的联邦学习优化算法[J]. 通信学报, 2023, 44(5): 169-180. |
| [4] | 张佳乐, 朱诚诚, 孙小兵, 陈兵. 基于GAN的联邦学习成员推理攻击与防御方法[J]. 通信学报, 2023, 44(5): 193-205. |
| [5] | 冯涛, 陈李秋, 方君丽, 石建明. 基于本地化差分隐私和属性基可搜索加密的区块链数据共享方案[J]. 通信学报, 2023, 44(5): 224-233. |
| [6] | 李开菊, 许强, 王豪. 冗余数据去除的联邦学习高效通信方法[J]. 通信学报, 2023, 44(5): 79-93. |
| [7] | 余晟兴, 陈泽凯, 陈钟, 刘西蒙. DAGUARD:联邦学习下的分布式后门攻击防御方案[J]. 通信学报, 2023, 44(5): 110-122. |
| [8] | 姜慧, 何天流, 刘敏, 孙胜, 王煜炜. 面向异构流式数据的高性能联邦持续学习算法[J]. 通信学报, 2023, 44(5): 123-136. |
| [9] | 张淑芬, 董燕灵, 徐精诚, 王豪石. 基于目标扰动的AdaBoost算法[J]. 通信学报, 2023, 44(2): 198-209. |
| [10] | 余晟兴, 陈钟. 基于同态加密的高效安全联邦学习聚合框架[J]. 通信学报, 2023, 44(1): 14-28. |
| [11] | 袁程胜, 郭强, 付章杰. 基于差分隐私的深度伪造指纹检测模型版权保护算法[J]. 通信学报, 2022, 43(9): 181-193. |
| [12] | 王瀚仪, 李效光, 毕文卿, 陈亚虹, 李凤华, 牛犇. 多级本地化差分隐私算法推荐框架[J]. 通信学报, 2022, 43(8): 52-64. |
| [13] | 范绍帅, 吴剑波, 田辉. 面向能量受限工业物联网设备的联邦学习资源管理[J]. 通信学报, 2022, 43(8): 65-77. |
| [14] | 张勇, 李丹丹, 韩璐, 黄小红. 隐私保护的群体感知数据交易算法[J]. 通信学报, 2022, 43(5): 1-13. |
| [15] | 莫梓嘉, 高志鹏, 杨杨, 林怡静, 孙山, 赵晨. 面向车联网数据隐私保护的高效分布式模型共享策略[J]. 通信学报, 2022, 43(4): 83-94. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||