


Chinese Journal of Intelligent Science and Technology ›› 2022, Vol. 4 ›› Issue (1): 75-83.doi: 10.11959/j.issn.2096-6652.202214
• Special Topic: Crowd Intelligence • Previous Articles Next Articles
Han WANG, Yang YU, Yuan JIANG
Revised:2022-01-14
Online:2022-03-15
Published:2022-03-01
Supported by:CLC Number:
Han WANG,Yang YU,Yuan JIANG. A cooperative multi-agent reinforcement learning algorithm based on dynamic self-selection parameters sharing[J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(1): 75-83.
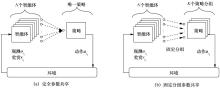
"
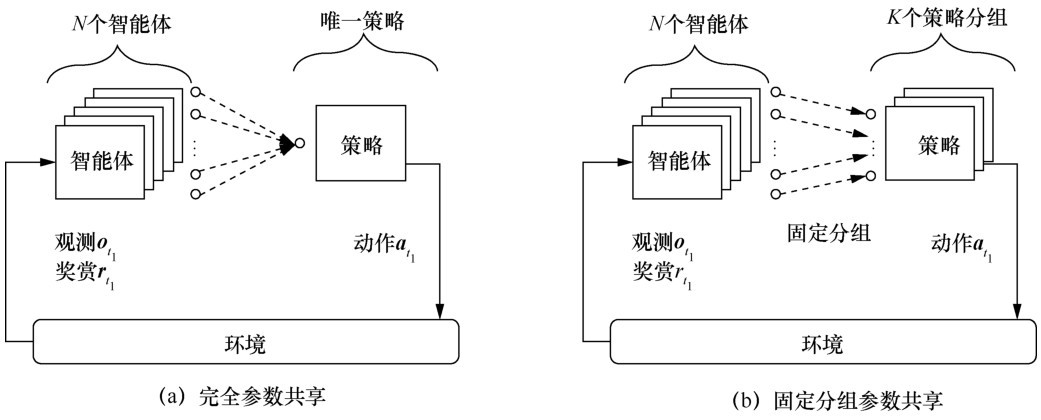

"
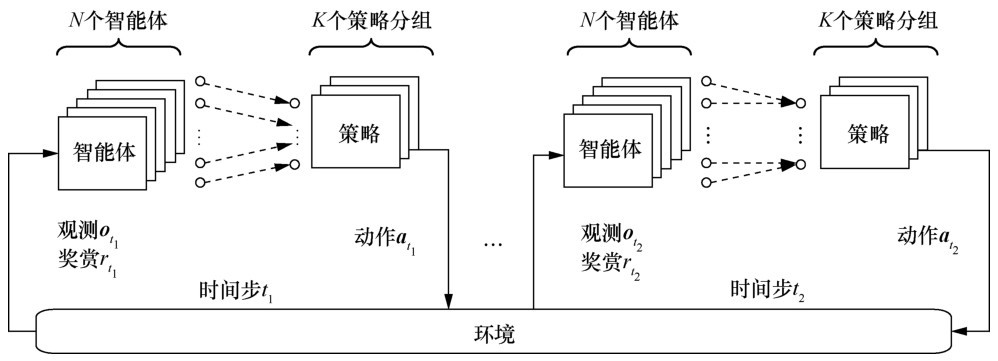
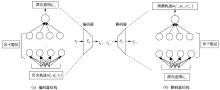
"

"

"

"

"

"

| [1] | 刘全, 翟建伟, 章宗长 ,等. 深度强化学习综述[J]. 计算机学报, 2018,41(1): 1-27. |
| LIU Q , ZHAI J W , ZHANG Z Z ,et al. A survey on deep reinforcement learning[J]. Chinese Journal of Computers, 2018,41(1): 1-27. | |
| [2] | 王飞跃, 曹东璞, 魏庆来 . 强化学习:迈向知行合一的智能机制与算法[J]. 智能科学与技术学报, 2020,2(2): 101-106. |
| WANG F Y , CAO D P , WEI Q L . Reinforcement learning:toward action-knowledge merged intelligent mechanisms and algorithms[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(2): 101-106. | |
| [3] | 刘朝阳, 穆朝絮, 孙长银 . 深度强化学习算法与应用研究现状综述[J]. 智能科学与技术学报, 2020,2(4): 314-326. |
| LIU Z Y , MU C X , SUN C Y . An overview on algorithms and applications of deep reinforcement learning[J]. Chinese Journal of Intelligent Science and Technology, 2020,2(4): 314-326. | |
| [4] | 王金予, 魏欣然, 石文磊 ,等. 强化学习在资源优化领域的应用[J]. 大数据, 2021,7(5): 131-149. |
| WANG J Y , WEI X R , SHI W L ,et al. Applications of reinforcement learning in the field of resource optimization[J]. Big Data Research, 2021,7(5): 131-149. | |
| [5] | LOWE R , WU Y , TAMAR A ,et al. Multi-agent actor-critic for mixed cooperative-competitive environments[C]// Proceedings of the 31st Annual Conference on Neural Information Processing Systems. Cambridge:MIT Press, 2017. |
| [6] | CONITZER V , SANDHOLM T . AWESOME:a general multiagent learning algorithm that converges in self-play and learns a best response against stationary opponents[J]. Machine Learning, 2007,67(1/2): 23-43. |
| [7] | EVERETT R , ROBERTS S . Learning against non-stationary agentswith opponent modelling and deep reinforcement learning[C]// Proceedings of AAAI Spring Symposium Series.[S.l.:s.n.], 2018. |
| [8] | FOERSTER J N , ASSAEL Y M , DE FREITAS N ,et al. Learning to communicate with deep multi-agent reinforcement learning[C]// Proceedings of Advances in Neural Information Processing Systems. New York:ACM Press, 2016: 2137-2145. |
| [9] | SUKHBAATAR S , SZLAM A , FERGUS R . Learning multiagentcommunication with back propagation[C]// Proceedings of Advances in Neural Information Processing Systems. New York:ACM Press, 2016: 2244-2252. |
| [10] | KIM D , MOON S , HOSTALLERO D ,et al. Learning to schedule communication in multi-agent reinforcement learning[C]// Proceedings of the 7th International Conference on Learning Representations.[S.l.:s.n.], 2019. |
| [11] | SUNEHAG P , LEVER G , GRUSLYS A ,et al. Value-decomposition networks for cooperative multi-agent learning[J]. arXiv preprint, 2017,arXiv:1706.05296. |
| [12] | RASHID T , SAMVELYAN M , WITT C S D ,et al. QMIX:monotonic value function factorisation for deep multi-agent reinforcement learning[C]// Proceedings of the 35th International Conference on Machine Learning. New York:JMLR, 2018: 4292-4301. |
| [13] | GUPTA J K , EGOROV M , KOCHENDERFER M J . Cooperative multi-agent control using deep reinforcement learning[C]// Proceedings of the 18th International Conference on Autonomous Agents and Multiagent Systems. New York:ACM Press, 2017: 66-83. |
| [14] | BAI H Y , CAI S J , YE N ,et al. Intention-aware online POMDP planning for autonomous driving in a crowd[C]// Proceedings of 2015 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2015: 454-460. |
| [15] | SADIGH D , SASTRY S S , SESHIA S A ,et al. Information gathering actions over human internal state[C]// Proceedings of 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). Piscataway:IEEE Press, 2016: 66-73. |
| [16] | XIE A N , LOSEY D P , TOLSMA R ,et al. Learning latent representations to influence multi-agent interaction[C]// Proceedings of the 4th Conference on Robot Learning. New York:JMLR, 2020: 575-588. |
| [17] | LITTMAN M L . Markov games as a framework for multi-agent reinforcement learning[M]// Machine learning proceedings 1994. Amsterdam: Elsevier, 1994: 157-163. |
| [18] | TERRY J K , GRAMMEL N , HARI A ,et al. Revisiting parameter sharing in multi-agent deep reinforcement learning[J]. arXiv preprint, 2020,arXiv:2005.13625. |
| [19] | CHRISTIANOS F , PAPOUDAKIS G , RAHMAN A ,et al. Scaling multi-agent reinforcement learning with selective parameter sharing[C]// Proceedings of the 38th International Conference on Machine Learning. New York:JMLR, 2021: 1989-1998. |
| [20] | QI S Y , ZHU S C . Intent-aware multi-agent reinforcement learning[C]// Proceedings of 2018 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2018: 7533-7540. |
| [21] | KIM W J , PARK J G , SUNG T C . Communication in multi-agent reinforcement learning:intention sharing[C]// Proceedings of the 9th International Conference on Learning Representations.[S.l.:s.n.], 2021. |
| [22] | SAMVELYAN M , RASHID T , WITT C S ,et al. The StarCraft multi-agent challenge[C]// Proceedings of the 18th International Conference on Autonomous Agents and Multi-Agent Systems. New York:ACM Press, 2019: 2186-2188. |
| [1] | Zhou YU, Jing BI, Haitao YUAN. A path planning method for complex naval battle field based on an improved DQN algorithm [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(3): 418-425. |
| [2] | Shuai MA, Qiming FU, Jianping CHEN, Fan FENG, You LU, Zhengwei LI, Shunian QIU. HVAC model-free optimal control method based on double-pools DQN [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(3): 426-444. |
| [3] | Yuxiang SUN, Yihui PENG, Bin LI, Jiawei ZHOU, Xinlei ZHANG, Xianzhong ZHOU. Overview of intelligent game:enlightenment of game AI to combat deduction [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 157-173. |
| [4] | De XU, Fangbo QIN. Research development on automated robotic peg-in-hole assembly [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 200-211. |
| [5] | Jiacheng LIU, Xiangwen ZHANG. TD3-based energy management strategy for hybrid energy storage system of electric vehicle [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(2): 277-287. |
| [6] | Pu FENG, Wenjun WU, Jie LUO, Xin YU, Yongkai TIAN. Emergence measurement of robot swarm intelligence based on swarm entropy [J]. Chinese Journal of Intelligent Science and Technology, 2022, 4(1): 65-74. |
| [7] | Lina XIA, Qing LI, Ruizhuo SONG, Zihan WANG, Zhen XU. Synchronization control of unknown heterogeneous multi-agent system via model-free adaptive dynamic programming [J]. Chinese Journal of Intelligent Science and Technology, 2021, 3(4): 444-448. |
| [8] | Zhiqiang HU. The framework model on internal mechanism of big data intelligent command and control [J]. Chinese Journal of Intelligent Science and Technology, 2021, 3(1): 101-109. |
| [9] | Zhaoyang LIU, Chaoxu MU, Changyin SUN. An overview on algorithms and applications of deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 314-326. |
| [10] | Jinna LI, Weiran CHENG. An overview of optimal consensus for data driven multi-agent system based on reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 327-340. |
| [11] | Qing-Shan JIA, Jingxian TANG, Junjie WU, Xiao HU, Yiting LIN, Heng XIA. Reinforcement learning for green and reliable data center [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 341-347. |
| [12] | Tao LI, Qinglai WEI. Intelligent heating temperature control system based on deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 348-353. |
| [13] | Rizhong WANG, Huiping LI, Di CUI, Demin XU. Depth control of autonomous underwater vehicle using deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 354-360. |
| [14] | Huiqiao FU, Kaiqiang TANG, Guizhou DENG, Xinpeng WANG, Chunlin CHEN. Motion planning for hexapod robot using deep reinforcement learning [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 361-371. |
| [15] | Yingying LIU, Zhanshan WANG. Output synchronization of heterogeneous multi-agent system:a reinforcement learning approach based on data [J]. Chinese Journal of Intelligent Science and Technology, 2020, 2(4): 394-400. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||
|
||