


智能科学与技术学报 ›› 2023, Vol. 5 ›› Issue (1): 7-31.doi: 10.11959/j.issn.2096-6652.202312
黄哲1, 王永才1,2, 李德英1
修回日期:2023-03-01
出版日期:2023-03-15
发布日期:2023-03-01
作者简介:黄哲(1996- ),女,中国人民大学信息学院博士生,主要研究领域为计算机视觉、3D 目标检测基金资助:Zhe HUANG1, Yongcai WANG1,2, Deying LI1
Revised:2023-03-01
Online:2023-03-15
Published:2023-03-01
Supported by:摘要:
3D 目标检测是自动驾驶、虚拟现实、机器人等应用领域的重要基础问题,其目的是从无序点云中框取出描述目标最准确的3D框,例如紧密包围行人或车辆点云的3D框,并给出目标3D框的位置、尺寸和朝向。如今,基于双目视觉、RGB-D相机、激光雷达构建的纯点云的3D目标检测,融合图像和点云多模态信息的3D目标检测,是两类主要的方法。首先介绍了3D点云的不同表示形式和特征提取方法,然后从传统机器学习类算法、非融合深度学习类算法、基于多模态融合的深度学习类算法3个层面,逐层递进地介绍各类3D目标检测方法,对类别内部和各类之间的方法进行分析和对比,深入分析了各类方法之间的区别和联系,最后论述了3D目标检测仍存在的问题和可能的研究方向,并对3D目标检测研究的主流数据集和主要评价指标进行了总结。
中图分类号:
黄哲,王永才,李德英. 3D目标检测方法研究综述[J]. 智能科学与技术学报, 2023, 5(1): 7-31.
Zhe HUANG,Yongcai WANG,Deying LI. A survey of 3D object detection algorithms[J]. Chinese Journal of Intelligent Science and Technology, 2023, 5(1): 7-31.
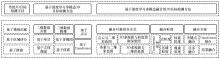
图1
3D目标检测整体分类结构"

图2
激光雷达点投影到鸟瞰图[22]"


图3
激光雷达点投影到前视图[23]"

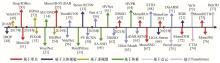
图4
单模态的深度学习检测方法时间轴"
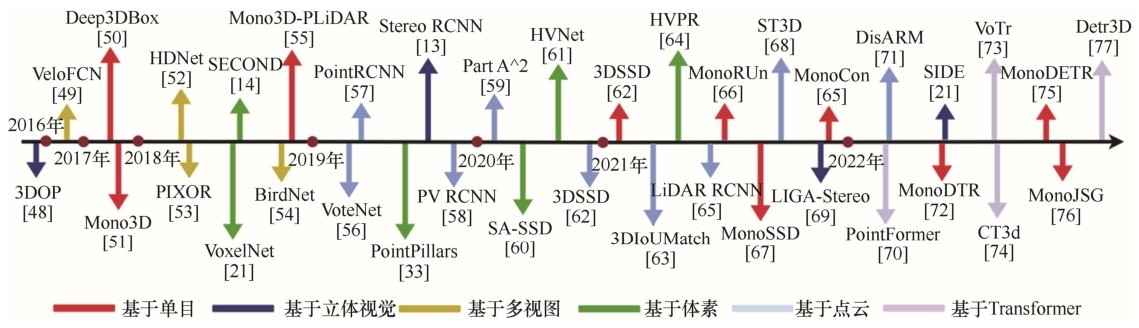
表1
典型的单模态3D检测方法在KITTI数据集上平均精度的比较"
| 方法 | 输入 | 速度/fps | 车辆 | 行人 | 自行车手 | |||||||||
| E | M | H | E | M | H | E | M | H | ||||||
| 基于立体视觉 | Deep3DBox[ | mono.image | — | — | — | — | — | — | — | — | — | — | ||
| MonoCon[ | — | 22.50% | 16.46% | 13.95% | 13.10% | 8.41% | 6.94% | 2.80% | 1.92% | 1.55% | ||||
| Mono3D[ | — | 2.53% | 2.31% | 2.31% | — | — | — | — | — | — | ||||
| Mono3D-PLiDAR[ | — | 1.76% | 7.5% | 6.1% | — | — | — | — | — | — | ||||
| M3DSSD[ | — | 17.51% | 11.46% | 8.98% | 5.16% | 3.87% | 3.08% | 2.10% | 1.51% | 1.58% | ||||
| MonoRUn[ | 19.65% | 12.30% | 10.58% | 10.88% | 6.78% | 5.83% | 1.01% | 0.61% | 0.48% | |||||
| MonoDETR[ | — | 25.00% | 16.47% | 13.58% | 33.60% | 22.11% | 18.60% | 28.84% | 20.61% | 16.38% | ||||
| MonoDTR[ | 21.99% | 15.39% | 12.73% | 15.33% | 10.18% | 8.61% | 5.05% | 3.27% | 3.19% | |||||
| MonoJSG[ | 24.69% | 16.14% | 13.64% | 11.02% | 7.49% | 6.41% | 5.45% | 3.21% | 2.57% | |||||
| 基于单目 | 3DOP[ | stereo image | — | — | — | — | — | — | — | — | — | — | ||
| LIGA-Stereo[ | — | 84.92% | 67.06% | 63.80% | 81.39% | 64.66% | 57.22% | 40.46% | 30.00% | 27.07% | ||||
| CG-Stereo[ | — | 76.17% | 57.82% | 54.63% | 74.39% | 53.58% | 46.50% | 47.40% | 30.89% | 27.73% | ||||
| Stereo R-CNN[ | — | 47.58% | 30.23% | 23.72% | — | — | — | — | — | — | ||||
| 基于多视图 | VeloFCN[ | FV | 1.0 | — | — | — | — | — | — | — | ||||
| BirdNet[ | BEV | 9.1 | 13.53% | 9.47% | 8.49% | 12.25% | 8.99% | 8.06% | 16.63% | 10.46% | 9.53% | |||
| PIXOR[ | BEV | 28.6 | — | — | — | — | — | — | — | — | — | |||
| HDNet[ | BEV | 20.0 | 82.11% | 71.70% | 67.08% | 50.32% | 40.97% | 37.87% | 77.63% | 63.78% | 55.89% | |||
| LaserNet[ | RV | 26.3 | — | — | — | — | — | — | — | — | ||||
| 基于体素 | VoxelNet[ | voxel | 2.0 | 77.82% | 64.17% | 57.51% | — | — | — | — | — | — | ||
| HVNet[ | voxel | 31 | — | — | — | — | — | — | — | — | — | |||
| SECOND[ | voxel | 26.3 | 84.65% | 75.96% | 68.71% | — | — | — | — | — | — | |||
| PointPillars[ | pillars | 62.0 | 82.58% | 74.31% | 68.99% | 51.45% | 41.92% | 38.89% | 77.10% | 58.65% | 51.92% | |||
| HVPR[ | voxel | 36.1 | 86.38% | 77.92% | 73.04% | 53.47% | 43.96% | 40.64% | ||||||
| SA-SSD[ | voxel | 25.0 | 88.75% | 79.79% | 74.16% | — | — | — | — | — | ||||
| Part-A∧2[ | point | 12.5 | 87.81% | 78.49% | 73.51% | 53.10% | 43.35% | 40.06% | 79.17% | 63.52% | 56.93% | |||
| 基于点云 | PointRCNN[ | point | 10 | 86.96% | 75.64% | 70.70% | 47.98% | 39.37% | 36.01% | 74.96% | 58.82% | 52.53% | ||
| VoteNet[ | point | — | — | — | — | — | — | — | — | — | — | |||
| PV RCNN[ | point &voxel | 12.5 | 90.25% | 81.43% | 76.82% | 52.17% | 43.29% | 40.29% | 78.60% | 63.71% | 57.65% | |||
| 3DSSD[ | point | 25.0 | 88.36% | 79.57% | 74.55% | 54.64% | 44.27% | 40.23% | 82.48% | 64.10% | 56.90% | |||
| LiDAR RCNN[ | point | — | 85.97% | 74.21% | 69.18% | — | — | — | — | — | — | |||
| 3DIoUMatch[ | point | — | 76.0% | 31.7% | 36.4% | 78.7% | 48.2% | 56.2% | 84.8% | 60.2% | 74.9% | |||
| ST3D[ | point | — | 72.94% | — | — | — | — | — | — | — | — | |||
| 基于Transformer | DisARM[ | point | — | — | — | — | — | — | — | — | — | — | ||
| VoTr-TSD[ | voxel | — | 89.04% | 84.04% | 78.68% | — | — | — | — | — | — | |||
| PointFormer[ | point | — | 87.13% | 77.06% | 69.25% | 50.67% | 42.43% | 39.60% | 75.01% | 59.80% | 53.99% | |||
| CT3D[ | point | — | 87.83% | 81.77% | 77.16% | — | — | — | — | — | — | |||
| DETR3D[ | BEV | — | — | — | — | — | — | — | — | — | — |
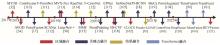
图5
多模态融合的深度学习检测方法时间轴"
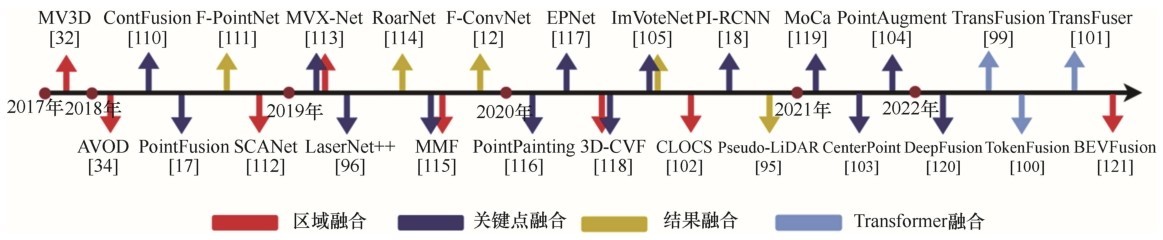
图6
两种组合方式的典型网络,从左到右依次是:(a)MV3D,(b)MVX-Net"
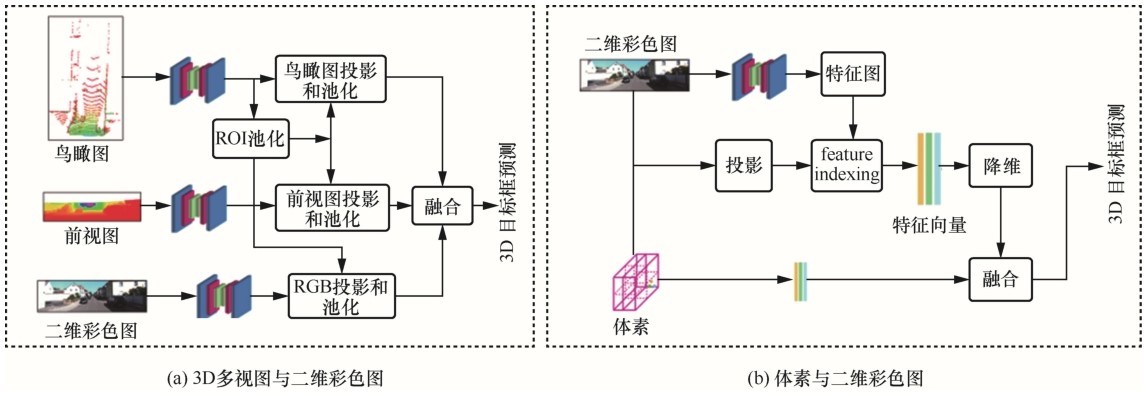

图7
两种组合方式的典型网络,从左到右依次是:(a)F-PointNet,(b)MMF"
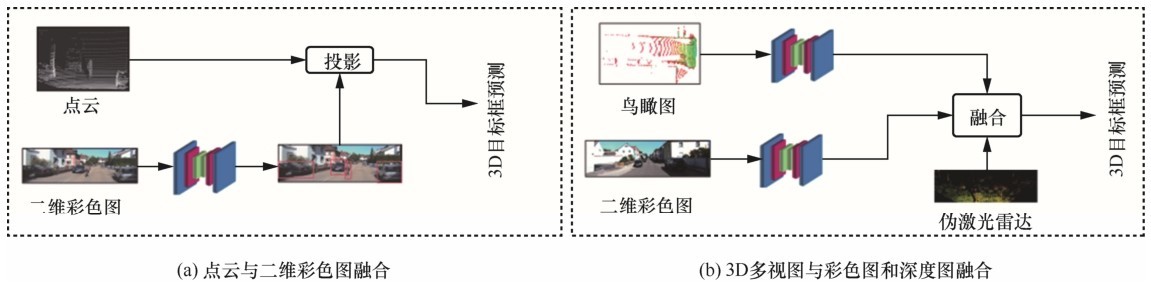
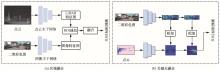
图8
区域融合、关键点融合方法示意"

图9
区域融合、关键点融合方法示意图"
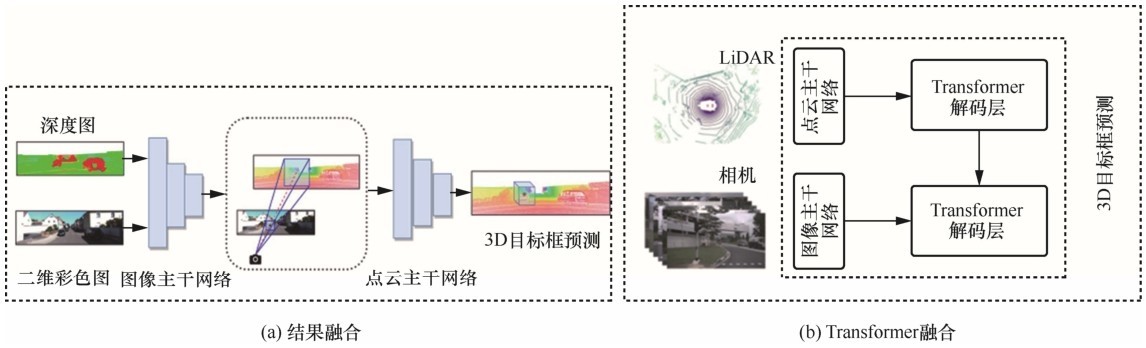
表2
典型的多模态3D检测方法在KITTI数据集上的平均精度比较"
| 模型 | 融合方法 | 组合 方式 | 速度/fps | 车辆 | 行人 | 自行车手 | ||||||||
| E | M | H | E | M | H | E | M | H | ||||||
| MV3D[ | Rg-F | (1) | 2.8 | 74.97% | 63.63% | 54.00% | — | — | — | — | — | — | ||
| AVOD[ | Rg-F | (1) | 12.5 | 76.39% | 66.47% | 60.23% | 36.10% | 27.86% | 25.76% | 57.19% | 42.08% | 38.29% | ||
| SCANet[ | Rg-F | (1) | 11.1 | 79.22% | 67.13% | 60.65% | — | — | — | — | — | — | ||
| MVX-Ne[ | Rg-F/Pt-F | (3) | 16.7 | 84.99% | 71.95% | 64.88% | — | — | — | — | — | — | ||
| MMF[ | Rg-F/Pt-F | (4) | 12.5 | 88.40% | 77.43% | 70.22% | — | — | — | — | — | — | ||
| 3D-CVF[ | Rg-F/Pt-F | (3) | — | 89.20% | 80.05% | 73.11% | — | — | — | — | — | — | ||
| CLOCS[ | Rg-F | (2) | — | 86.38% | 78.45% | 72.45% | — | — | — | — | — | — | ||
| ContFuse[ | Pt-F | (1) | 16.7 | 83.68% | 68.78% | 61.67% | — | — | — | — | — | — | ||
| PointFusion[ | Pt-F | (2) | — | 77.92% | 63.00% | 53.27% | 33.36% | 28.04% | 23.38% | 49.34% | 29.42% | 26.98% | ||
| PointPainting[ | Pt-F | (2) | 2.5 | 82.11% | 71.70% | 67.08% | 50.32% | 40.97% | 37.87% | 77.63% | 63.78% | 55.89% | ||
| EPNet[ | Pt-F | (2) | — | 89.81% | 79.28% | 74.59% | — | — | — | — | — | — | ||
| PI-RCNN[ | Pt-F | (2) | — | 88.27% | 78.53% | 77.75% | — | — | — | — | — | — | ||
| MoCa[ | Pt-F | (3) | — | 50.9% | 43.7% | 40.0% | 76.1% | 61.0% | 53.4% | 86.0% | 75.9% | 70.7% | ||
| CenterPoint[ | Pt-F | (1) | — | — | — | — | — | — | — | — | — | — | ||
| DeepFusiont[ | Pt-F | (2) | — | — | — | — | — | — | — | — | — | — | ||
| PointAugmen[ | Pt-F | (2) | — | — | — | — | — | — | — | — | — | — | ||
| RoarNet[ | Rs-F | (2) | 10.0 | 83.71% | 73.04% | 59.16% | — | — | — | — | — | — | ||
| ImVoteNet[ | Rs-F/Pt-F | (2) | — | — | — | — | — | — | — | — | — | — | ||
| Pseudo-LiDAR[ | Rs-F | (4) | — | 54.53% | 34.05% | 38.25% | — | — | — | — | — | — | ||
| F-ConvNet[ | Rs-F | (2) | 2.1 | 87.36% | 76.39% | 66.69% | 52.16% | 43.38% | 38.80% | 81.98% | 65.07% | 56.54% | ||
| F-PointNet[ | Rs-F | (2) | 5.9 | 82.19% | 69.79% | 60.59% | 50.53% | 42.15% | 38.08% | 72.27% | 56.12% | 49.01% | ||
| TransFusion[ | Tr-F | (2) | — | — | — | — | — | — | — | — | — | — | ||
| TokenFusion[ | Tr-F | (2) | — | — | — | — | — | — | — | — | — | — | ||
| TransFuser[ | Tr-F | (1) | — | — | — | — | — | — | — | — | — | — | ||
表3
3D目标检测数据集"
| 数据集 | 传感器 | 时间 | 大小 | 类别 | 采集地点 |
| KITTI[ | 相机、LiDARGNSS、惯性传感器 | 2012年 | 7481帧80 256个对象 | 8类 | 卡尔斯鲁厄(德国) |
| SUN3D[ | 3D相机 | 2013年 | 254 个不同场景 | 16类 | 北美、欧洲、亚洲 |
| 捕获415序列 | |||||
| 10 335张室内场景 | |||||
| SUN RGB-D[ | 3D相机(4) | 2015年 | 146 617个2D边框 | 10类 | 普林斯顿大学(美国) |
| 58 657个3D框 | |||||
| Multi-SpectralObject[ | 视觉和热相机 | 2017年 | 7 512帧,5 833个对象 | 3类 | 日本 |
| MPO[ | 相机、LiDAR、GNSS | 2017年 | 1 569帧 | 6类 | — |
| ScanNet[ | 3D相机 | 2018年 | 1 513个室内场景 | 21类 | — |
| 深度传感器 | |||||
| S3DIS[ | 3D相机 | 2018年 | 超过 70 000 张RGB图像 | 13类 | 斯坦福大学(美国) |
| DBNet[ | 相机、LiDAR、GNSS | 2018年 | 超过10k帧 | 含7个数据集 | 中国 |
| KAIST[ | 相机、LiDAR | 2018年 | 7512帧 | 3类 | 首尔(韩国) |
| GNSS、惯性传感器 | 308 913个对象 | ||||
| A*3D[ | 相机(2) | 2019年 | 39 k帧 | 7类 | 新加坡 |
| LiDAR | 230 k个对象 | ||||
| Argoverse[ | LiDAR(2) | 2019年 | 113个场景 | 15类 | 匹兹堡(美国) |
| 相机(9) | 300 k轨迹 | 宾西法尼亚州(美国) | |||
| 佛罗里达州(美国) | |||||
| PandaSet[ | LiDAR(2)、相机(6) | 2019年 | 125个场景 | 28类 | 旧金山(美国) |
| GNSS、惯性传感器 | |||||
| ApolloScape[ | 相机、LiDAR | 2019年 | 143 906个图像帧 | 35类 | 中国 |
| GNSS、惯性传感器 | 89 430个物体 | ||||
| 相机(6) | 1 000个场景; | ||||
| nuScence[ | LiDAR | 2019年 | 1.4万帧(照相机、雷达) | 23类 | 波士顿(美国)、新加坡 |
| Radars(6) | 390 k帧(3D激光雷达) | ||||
| BLVD[ | 相机(5) | 2019年 | 120 k帧 | 3类 | 常熟(中国) |
| LiDAR(5) | 249 129个对象 | ||||
| Waymo[ | 相机 | 2019年 | 200 k帧 | 4类 | — |
| LiDAR | 12 M对象(3D激光雷达) | ||||
| 1.2 M对象(2D照相机) | |||||
| H3D[ | 相机(3) | 2019年 | 27 721帧 | 8类 | 旧金山(美国) |
| LiDAR | 1 071 302个对象 | ||||
| A2D2[ | 相机(6) | 2020年 | 40 k帧(语义信息) | 37类 | 凯默斯海姆(德国) |
| LiDAR(5) | 12 k帧(3D激光雷达) | 英戈尔施塔特(德国) | |||
| 390 k帧未标记 | 慕尼黑(德国) |
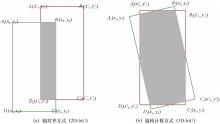
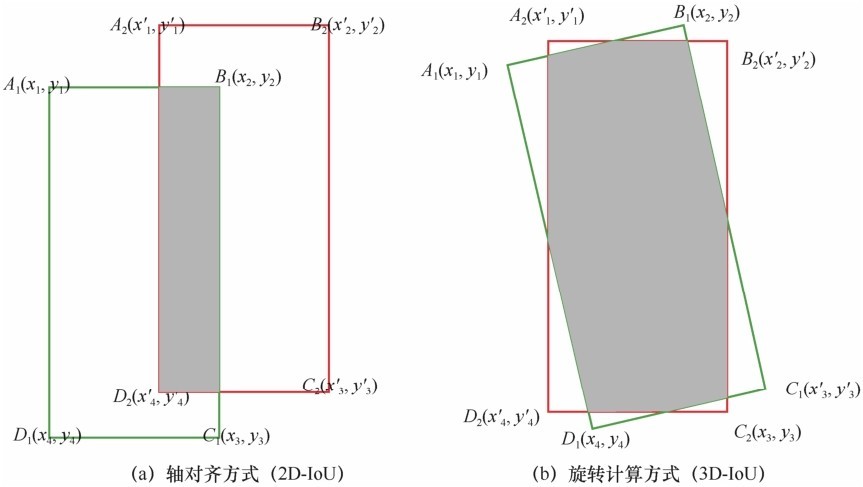
图10
真值框Bg(绿色)与预测框Bd(红色)之间旋转重叠示意图"
| [1] | GUO Y L , WANG H Y , HU Q Y ,et al. Deep learning for 3D point clouds:a survey[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2021,43(12): 4338-4364. |
| [2] | ARNOLD E , AL-JARRAH O Y , DIANATI M ,et al. A survey on 3D object detection methods for autonomous driving applications[J]. IEEE Transactions on Intelligent Transportation Systems, 2019,20(10): 3782-3795. |
| [3] | QIAN R , LAI X , LI X . 3D object detection for autonomous driving:a survey[J]. arXiv preprint, 2021,arXiv:2106.10823. |
| [4] | GEIGER A , LENZ P , URTASUN R . Are we ready for autonomous driving? The KITTI vision benchmark suite[C]// Proceedings of 2012 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2012: 3354-3361. |
| [5] | FRITZ M , SCHIELE B . Decomposition,discovery and detection of visual categories using topic models[C]// Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2008: 1-8. |
| [6] | CUI Y D , CHEN R , CHU W B ,et al. Deep learning for image and point cloud fusion in autonomous driving:a review[J]. IEEE Transactions on Intelligent Transportation Systems, 2022,23(2): 722-739. |
| [7] | QIN Z Y , WANG J L , LU Y . MonoGRNet:a geometric reasoning network for monocular 3D object localization[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1): 8851-8858. |
| [8] | FU H , GONG M M , WANG C H ,et al. Deep ordinal regression network for monocular depth estimation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 2002-2011. |
| [9] | ALDOMA A , MARTON Z C , TOMBARI F ,et al. Tutorial:point cloud library:three-dimensional object recognition and 6 DOF pose estimation[J]. IEEE Robotics & Automation Magazine, 2012,19(3): 80-91. |
| [10] | ARORA H , LOEFF N , FORSYTH D A ,et al. Unsupervised segmentation of objects using efficient learning[C]// Proceedings of 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2007: 1-7. |
| [11] | WANG Z X , JIA K . Frustum ConvNet:sliding Frustums to aggregate local point-wise features for amodal 3D object detection[C]// Proceedings of 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2020: 1742-1749. |
| [12] | YAN Y , MAO Y X , LI B . SECOND:sparsely embedded convolutional detection[J]. Sensors (Basel,Switzerland), 2018,18(10): 3337. |
| [13] | ZHOU Y , SUN P , ZHANG Y ,et al. End-to-end multi-view fusion for 3D object detection in LiDAR point clouds[C]// Proceedings of Conference on Robot Learning.[S.l.:s.n.], 2020: 923-932. |
| [14] | XU D F , ANGUELOV D , JAIN A . PointFusion:deep sensor fusion for 3D bounding box estimation[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 244-253. |
| [15] | XIE S N , LIU S N , CHEN Z Y ,et al. Attentional ShapeContextNet for point cloud recognition[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 4606-4615. |
| [16] | XIE L , XIANG C , YU Z X ,et al. PI-RCNN:an efficient multi-sensor 3D object detector with point-based attentive cont-conv fusion module[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2020,34(7): 12460-12467. |
| [17] | FENG D , HAASE-SCHüTZ C , ROSENBAUM L ,et al. Deep multi-modal object detection and semantic segmentation for autonomous driving:datasets,methods,and challenges[J]. IEEE Transactions on Intelligent Transportation Systems, 2021,22(3): 1341-1360. |
| [18] | WANG Y , MAO Q , ZHU H ,et al. Multi-modal 3D object detection in autonomous driving:a survey[J]. arXiv preprint, 2021,arXiv:2106.12735. |
| [19] | CHARLES R Q , HAO S , MO K C ,et al. PointNet:deep learning on point sets for 3D classification and segmentation[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 77-85. |
| [20] | QI C R , YI L , SU H ,et al. PointNet++:deep hierarchical feature learning on point sets in a metric space[J]. arXiv preprint, 2017,arXiv:1706.02413. |
| [21] | ZHOU Y , TUZEL O . VoxelNet:end-to-end learning for point cloud based 3D object detection[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 4490-4499. |
| [22] | CHEN X Z , MA H M , WAN J ,et al. Multi-view 3D object detection network for autonomous driving[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 6526-6534. |
| [23] | KU J , MOZIFIAN M , LEE J ,et al. Joint 3D proposal generation and object detection from view aggregation[C]// Proceedings of 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York:ACM Press, 2018: 1-8. |
| [24] | LANG A H , VORA S , CAESAR H ,et al. PointPillars:fast encoders for object detection from point clouds[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 12689-12697. |
| [25] | FAN L , XIONG X , WANG F ,et al. RangeDet:in defense of range view for LiDAR-based 3D object detection[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2022: 2898-2907. |
| [26] | SUN P , WANG W Y , CHAI Y N ,et al. RSN:range sparse net for efficient,accurate LiDAR 3D object detection[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 5721-5730. |
| [27] | WU B C , WAN A , YUE X Y ,et al. SqueezeSeg:convolutional neural nets with recurrent CRF for real-time road-object segmentation from 3D LiDAR point cloud[C]// Proceedings of 2018 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2018: 1887-1893. |
| [28] | REN M Y , POKROVSKY A , YANG B ,et al. SBNet:sparse blocks network for fast inference[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 8711-8720. |
| [29] | LI P X , ZHAO H C , LIU P F ,et al. RTM3D:real-time monocular 3D detection from object keypoints for autonomous driving[C]// Proceedings of 2020 16th European Conference on Computer Vision. Cham:Springer, 2020: 644-660. |
| [30] | WANG Y , CHAO W L , GARG D ,et al. Pseudo-LiDAR from visual depth estimation:bridging the gap in 3D object detection for autonomous driving[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 8437-8445. |
| [31] | NG P C , HENIKOFF S . SIFT:predicting amino acid changes that affect protein function[J]. Nucleic Acids Research, 2003,31(13): 3812-3814. |
| [32] | JOHNSON A E , HEBERT M . Surface matching for object recognition in complex three-dimensional scenes[J]. Image and Vision Computing, 1998,16(9/10): 635-651. |
| [33] | CHEN H , BHANU B . 3D free-form object recognition in range images using local surface patches[J]. Pattern Recognition Letters, 2007,28(10): 1252-1262. |
| [34] | MIAN A , BENNAMOUN M , OWENS R . On the repeatability and quality of keypoints for local feature-based 3D object retrieval from cluttered scenes[J]. International Journal of Computer Vision, 2010,89(2): 348-361. |
| [35] | STEIN F , MEDIONI G . Structural indexing:efficient 3D object recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1992,14(2): 125-145. |
| [36] | CHUA C S , JARVIS R . Point signatures:a new representation for 3D object recognition[J]. International Journal of Computer Vision, 1997,25(1): 63-85. |
| [37] | FROME A , HUBER D , KOLLURI R ,et al. Recognizing objects in range data using regional point descriptors[C]// Proceedings of European Conference on Computer Vision. Heidelberg:Springer, 2004: 224-237. |
| [38] | ZHOU D F , FANG J , SONG X B ,et al. IoU loss for 2D/3D object detection[C]// Proceedings of 2019 International Conference on 3D Vision. Piscataway:IEEE Press, 2019: 85-94. |
| [39] | COLLET A , SRINIVASAY S S , HEBERT M . Structure discovery in multi-modal data:a region-based approach[C]// Proceedings of 2011 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2011: 5695-5702. |
| [40] | SHIN J , TRIEBEL R , SIEGWART R . Unsupervised discovery of repetitive objects[C]// Proceedings of 2010 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2010: 5041-5046. |
| [41] | HERBST E , HENRY P , REN X F ,et al. Toward object discovery and modeling via 3D scene comparison[C]// Proceedings of 2011 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2011: 2623-2629. |
| [42] | KARPATHY A , MILLER S , LI F F . Object discovery in 3D scenes via shape analysis[C]// Proceedings of 2013 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2013: 2088-2095. |
| [43] | FELZENSZWALB P F , HUTTENLOCHER D P . Efficient graph-based image segmentation[J]. International Journal of Computer Vision, 2004,59(2): 167-181. |
| [44] | SONG S R , XIAO J X . Sliding shapes for 3D object detection in depth images[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2014: 634-651. |
| [45] | MALISIEWICZ T , GUPTA A , EFROS A A . Ensemble of exemplar-SVMs for object detection and beyond[C]// Proceedings of 2011 International Conference on Computer Vision. Piscataway:IEEE Press, 2012: 89-96. |
| [46] | SONG S R , XIAO J X . Deep sliding shapes for amodal 3D object detection in RGB-D images[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 808-816. |
| [47] | 罗会兰, 陈鸿坤 . 基于深度学习的目标检测研究综述[J]. 电子学报, 2020,48(6): 1230-1239. |
| LUO H L , CHEN H K . Survey of object detection based on deep learning[J]. Acta Electronica Sinica, 2020,48(6): 1230-1239. | |
| [48] | MINEMURA K , LIAU H , MONRROY A ,et al. LMNet:real-time multiclass object detection on CPU using 3D LiDAR[C]// Proceedings of 2018 3rd Asia-Pacific Conference on Intelligent Robot Systems. Piscataway:IEEE Press, 2018: 28-34. |
| [49] | YE M S , XU S J , CAO T Y . HVNet:hybrid voxel network for LiDAR based 3D object detection[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 1628-1637. |
| [50] | GUO X Y , SHI S S , WANG X G ,et al. LIGA-stereo:learning LiDAR geometry aware representations for stereo-based 3D detector[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2022: 3133-3143. |
| [51] | YANG J H , SHI S S , WANG Z ,et al. ST3D:self-training for unsupervised domain adaptation on 3D object detection[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 10363-10373. |
| [52] | SHI S S , WANG X G , LI H S . PointRCNN:3D object proposal generation and detection from point cloud[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 770-779. |
| [53] | HE C H , ZENG H , HUANG J Q ,et al. Structure aware single-stage 3D object detection from point cloud[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11870-11879. |
| [54] | SHI S S , WANG Z , WANG X G ,et al. Part-A∧2 Net:3D part-aware and aggregation neural network for object detection from point cloud[J]. arXiv preprint, 2019,arXiv:1907.03670. |
| [55] | PENG X D , ZHU X G , WANG T ,et al. SIDE:center-based stereo 3D detector with structure-aware instance depth estimation[C]// Proceedings of 2022 IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway:IEEE Press, 2022: 225-234. |
| [56] | ARMENI I , SAX S , ZAMIR A R ,et al. Joint 2D-3D-semantic data for indoor scene understanding[J]. arXiv preprint, 2017,arXiv:1702.01105. |
| [57] | PAN X R , XIA Z F , SONG S J ,et al. 3D object detection with pointformer[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 7459-7468. |
| [58] | SHENGA H L , CAI S J , LIU Y ,et al. Improving 3D object detection with channel-wise transformer[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2022: 2723-2732. |
| [59] | WANG Y , GUIZILINI V , ZHANG T ,et al. DETR3D:3D object detection from multi-view images via 3D-to-2D queries[C]// Proceedings of Conference on Robot Learning.[S.l.:s.n.], 2022: 180-191. |
| [60] | MAO J G , XUE Y J , NIU M Z ,et al. Voxel transformer for 3D object detection[C]// Proceedings of 2021 IEEE/CVF International Conference on Computer Vision. Piscataway:IEEE Press, 2021: 3164-3173. |
| [61] | DUAN Y , ZHU C , LAN Y ,et al. DisARM:displacement aware relation module for 3D detection[J]. arXiv preprint, 2022,arXiv:2203.01152. |
| [62] | JUNG H , OTO Y , MOZOS O M ,et al. Multi-modal panoramic 3D outdoor datasets for place categorization[C]// Proceedings of 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York:ACM Press, 2016: 4545-4550. |
| [63] | ZHANG R , QIU H , WANG T ,et al. MonoDETR:depth-guided transformer for monocular 3D object detection[J]. arXiv preprint, 2022,arXiv:2203.13310. |
| [64] | DAI A , CHANG A X , SAVVA M ,et al. ScanNet:richly-annotated 3D reconstructions of indoor scenes[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 2432-2443. |
| [65] | LI Z C , WANG F , WANG N Y . LiDAR R-CNN:an efficient and universal 3D object detector[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 7542-7551. |
| [66] | SONG S R , LICHTENBERG S P , XIAO J X . SUN RGB-D:a RGB-D scene understanding benchmark suite[C]// Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2015: 567-576. |
| [67] | XIAO J X , OWENS A , TORRALBA A . SUN3D:a database of big spaces reconstructed using SfM and object labels[C]// Proceedings of 2013 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2014: 1625-1632. |
| [68] | CHOI Y , KIM N , HWANG S ,et al. KAIST multi-spectral day/night data set for autonomous and assisted driving[J]. IEEE Transactions on Intelligent Transportation Systems, 2018,19(3): 934-948. |
| [69] | BELTRáN J , GUINDEL C , MORENO F M ,et al. BirdNet:a 3D object detection framework from LiDAR information[C]// Proceedings of 2018 21st International Conference on Intelligent Transportation Systems. New York:ACM Press, 2018: 3517-3523. |
| [70] | LU H H , CHEN X S , ZHANG G Y ,et al. Scanet:spatial-channel attention network for 3D object detection[C]// Proceedings of 2019 IEEE International Conference on Acoustics,Speech and Signal Processing. Piscataway:IEEE Press, 2019: 1992-1996. |
| [71] | HUANG K C , WU T H , SU H T ,et al. MonoDTR:monocular 3D object detection with depth-aware transformer[J]. arXiv preprint, 2022,arXiv:2203.10981. |
| [72] | ZHAO X , LIU Z , HU R L ,et al. 3D object detection using scale invariant and feature reweighting networks[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1): 9267-9274. |
| [73] | VORA S , LANG A H , HELOU B ,et al. Point Painting:sequential fusion for 3D object detection[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 4603-4611. |
| [74] | QI C R , LIU W , WU C X ,et al. Frustum PointNets for 3D object detection from RGB-D data[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 918-927. |
| [75] | JIANG M , WU Y , ZHAO T ,et al. PointSIFT:a SIFT-like network module for 3D point cloud semantic segmentation[J]. arXiv preprint, 2018,arXiv:1807.00652. |
| [76] | LI B , ZHANG T , XIA T . Vehicle detection from 3D lidar using fully convolutional network[J]. arXiv preprint, 2016,arXiv:1608.07916. |
| [77] | LIANG M , YANG B , WANG S L ,et al. Deep continuous fusion for multi-sensor 3D object detection[C]// Proceedings of 2018 15th European Conference on Computer Vision. New York:ACM Press, 2018: 663-678. |
| [78] | 尹宏鹏, 陈波, 柴毅 ,等. 基于视觉的目标检测与跟踪综述[J]. 自动化学报, 2016,42(10): 1466-1489. |
| YIN H P , CHEN B , CHAI Y ,et al. Vision-based object detection and tracking:a review[J]. Acta Automatica Sinica, 2016,42(10): 1466-1489. | |
| [79] | 王永森, 刘宏哲 . 3D 目标检测技术的研究进展[C]// 中国计算机用户协会网络应用分会2019年第二十三届网络新技术与应用年会论文集. 重庆:《计算机科学》编辑部, 2019: 177-182. |
| WANG Y S , LIU H Z . Study progress of advances in 3D object detection technology[C]// Proceedings of 2019 23rd Annual Conference on New Network Technologies and Applications of China Computer Users Association. Chongqing:Editorial Board of Computer Science, 2019: 177-182. | |
| [80] | GIRSHICK R , . Fast R-CNN[C]// Proceedings of 2015 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2016: 1440-1448. |
| [81] | REN S Q , HE K M , GIRSHICK R ,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39(6): 1137-1149. |
| [82] | LIU W , ANGUELOV D , ERHAN D ,et al. SSD:single shot MultiBox detector[C]// Proceedings of 14th European Conference on Computer Vision. Cham:Springer International Publishing, 2016: 21-37. |
| [83] | REDMON J , DIVVALA S , GIRSHICK R ,et al. You only look once:unified,real-time object detection[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 779-788. |
| [84] | HE K M , ZHANG X Y , REN S Q ,et al. Deep residual learning for image recognition[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 770-778. |
| [85] | CHEN Y J , TAI L , SUN K ,et al. MonoPair:monocular 3D object detection using pairwise spatial relationships[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 12090-12099. |
| [86] | MOUSAVIAN A , ANGUELOV D , FLYNN J ,et al. 3D bounding box estimation using deep learning and geometry[C]// Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2017: 5632-5640. |
| [87] | WENG X S , KITANI K . Monocular 3D object detection with pseudo-LiDAR point cloud[C]// Proceedings of 2019 IEEE/CVF International Conference on Computer Vision Workshop. Piscataway:IEEE Press, 2020: 857-866. |
| [88] | LIAN Q , LI P , CHEN X . MonoJSG:joint semantic and geometric cost volume for monocular 3D object detection[J]. arXiv preprint, 2022,arXiv:2203.08563. |
| [89] | CHEN X Z , KUNDU K , ZHU Y K ,et al. 3D object proposals using stereo imagery for accurate object class detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40(5): 1259-1272. |
| [90] | LI P L , CHEN X Z , SHEN S J . Stereo R-CNN based 3D object detection for autonomous driving[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 7636-7644. |
| [91] | HE K M , GKIOXARI G , DOLLáR P ,et al. Mask R-CNN[C]// Proceedings of 2017 IEEE International Conference on Computer Vision. Piscataway:IEEE Press, 2017: 2980-2988. |
| [92] | YANG B , LUO W J , URTASUN R . PIXOR:real-time 3D object detection from point clouds[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 7652-7660. |
| [93] | YANG B , LIANG M , URTASUN R . HDNET:exploiting HD maps for 3D object detection[C]// Proceedings of Conference on Robot Learning.[S.l.:s.n.], 2018: 146-155. |
| [94] | MEYER G P , LADDHA A , KEE E ,et al. LaserNet:an efficient probabilistic 3D object detector for autonomous driving[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 12669-12678. |
| [95] | LIU W , ANGUELOV D , ERHAN D ,et al. SSD:single shot multibox detector[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2016: 21-37. |
| [96] | SHI S S , GUO C X , JIANG L ,et al. PV-RCNN:point-voxel feature set abstraction for 3D object detection[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 10526-10535. |
| [97] | WANG H , CONG Y Z , LITANY O ,et al. 3DIoUMatch:leveraging IoU prediction for semi-supervised 3D object detection[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 14610-14619. |
| [98] | CARION N , MASSA F , SYNNAEVE G ,et al. End-to-end object detection with transformers[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2020: 213-229. |
| [99] | LIU X , XUE N , WU T . Learning auxiliary monocular contexts helps monocular 3D object detection[J]. arXiv preprint, 2021,arXiv:2112.04628. |
| [100] | HE T , SOATTO S . Mono3D++:monocular 3D vehicle detection with two-scale 3D hypotheses and task priors[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2019,33(1): 8409-8416. |
| [101] | LUO S J , DAI H , SHAO L ,et al. M3DSSD:monocular 3D single stage object detector[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 6141-6150. |
| [102] | CHEN H S , HUANG Y Y , TIAN W ,et al. MonoRUn:monocular 3D object detection by reconstruction and uncertainty propagation[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 10374-10383. |
| [103] | LI C Y , KU J , WASLANDER S L . Confidence guided stereo 3D object detection with split depth estimation[C]// Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2021: 5776-5783. |
| [104] | NOH J , LEE S , HAM B . HVPR:hybrid voxel-point representation for single-stage 3D object detection[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 14600-14609. |
| [105] | DING Z P , HAN X , NIETHAMMER M . VoteNet:a deep learning label fusion method for multi-atlas segmentation[C]// Proceedings of International Conference on Medical Image Computing and Computer-Assisted Intervention. Cham:Springer, 2019: 202-210. |
| [106] | YANG Z T , SUN Y N , LIU S ,et al. 3DSSD:point-based 3D single stage object detector[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11037-11045. |
| [107] | LIU Z C , WU Z Z , TóTH R , . SMOKE:single-stage monocular 3D object detection via keypoint estimation[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE Press, 2020: 4289-4298. |
| [108] | HERBST E , REN X F , FOX D . RGB-D object discovery via multi-scene analysis[C]// Proceedings of 2011 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway:IEEE Press, 2011: 4850-4856. |
| [109] | LIANG M , YANG B , CHEN Y ,et al. Multi-task multi-sensor fusion for 3D object detection[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 7337-7345. |
| [110] | LI Y , YU A W , MENG T ,et al. DeepFusion:lidar-camera deep fusion for multi-modal 3D object detection[J]. arXiv preprint, 2022,arXiv:2203.08195. |
| [111] | GUPTA S , GIRSHICK R , ARBELáEZ P ,et al. Learning rich features from RGB-D images for object detection and segmentation[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2014: 345-360. |
| [112] | YOO J H , KIM Y , KIM J ,et al. 3D-CVF:generating joint camera and LiDAR features using cross-view spatial feature fusion for 3D object detection[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2020: 720-736. |
| [113] | SHIN K , KWON Y P , TOMIZUKA M . RoarNet:a robust 3D object detection based on RegiOn approximation refinement[C]// Proceedings of 2019 IEEE Intelligent Vehicles Symposium. Piscataway:IEEE Press, 2019: 2510-2515. |
| [114] | QI C R , CHEN X L , LITANY O ,et al. ImVoteNet:boosting 3D object detection in point clouds with image votes[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 4403-4412. |
| [115] | SINDAGI V A , ZHOU Y , TUZEL O . MVX-Net:multimodal VoxelNet for 3D object detection[C]// Proceedings of 2019 International Conference on Robotics and Automation. Piscataway:IEEE Press, 2019: 7276-7282. |
| [116] | ZHANG W W , WANG Z , LOY C C . Multi-modality cut and paste for 3D object detection[J]. arXiv preprint, 2020,arXiv:2012.12741. |
| [117] | WANG C W , MA C , ZHU M ,et al. PointAugmenting:cross-modal augmentation for 3D object detection[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 11789-11798. |
| [118] | WANG Y , CHEN X , CAO L ,et al. Multimodal token fusion for vision transformers[J]. arXiv preprint, 2022,arXiv:2204.08721. |
| [119] | BAI X , HU Z , ZHU X ,et al. TransFusion:robust LiDAR-camera fusion for 3D object detection with transformers[J]. arXiv preprint, 2022,arXiv:2203.11496. |
| [120] | PRAKASH A , CHITTA K , GEIGER A . Multi-modal fusion transformer for end-to-end autonomous driving[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 7073-7083. |
| [121] | LIANG T , XIE H , YU K ,et al. BEVFusion:a simple and robust LiDAR-camera fusion framework[J]. arXiv preprint, 2022,arXiv:2205.13790. |
| [122] | MANHARDT F , KEHL W , GAIDON A . ROI-10D:monocular lifting of 2D detection to 6D pose and metric shape[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 2064-2073. |
| [123] | GUPTA S , HOFFMAN J , MALIK J . Cross modal distillation for supervision transfer[C]// Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2016: 2827-2836. |
| [124] | HUANG T T , LIU Z , CHEN X W ,et al. EPNet:enhancing point features with image semantics for 3D object detection[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2020: 35-52. |
| [125] | PANG S , MORRIS D , RADHA H . CLOCs:camera-LiDAR object candidates fusion for 3D object detection[C]// Proceedings of 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems. New York:ACM Press, 2020: 10386-10393. |
| [126] | YIN T W , ZHOU X Y , KR?HENBüHL P , . Center-based 3D object detection and tracking[C]// Proceedings of 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2021: 11779-11788. |
| [127] | SIVIC J , RUSSELL B C , EFROS A A ,et al. Discovering objects and their location in images[C]// Proceedings of 10th IEEE International Conference on Computer Vision Volume 1. Piscataway:IEEE Press, 2005: 370-377. |
| [128] | SHI X P , CHEN Z X , KIM T K . Distance-normalized unified representation for monocular 3D object detection[C]// Proceedings of European Conference on Computer Vision. Cham:Springer, 2020: 91-107. |
| [129] | CHEN Y P , WANG J K , LI J ,et al. LiDAR-video driving dataset:learning driving policies effectively[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2018: 5870-5878. |
| [130] | PHAM Q H , SEVESTRE P , PAHWA R S ,et al. A*3D dataset:towards autonomous driving in challenging environments[C]// Proceedings of 2020 IEEE International Conference on Robotics and Automation. Piscataway:IEEE Press, 2020: 2267-2273. |
| [131] | CHANG M F , LAMBERT J , SANGKLOY P ,et al. Argoverse:3D tracking and forecasting with rich maps[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 8740-8749. |
| [132] | SCALE H . PandaSet:public large-scale dataset for autonomous driving[R]. 2019. |
| [133] | HUANG X Y , CHENG X J , GENG Q C ,et al. The ApolloScape dataset for autonomous driving[C]// Proceedings of 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops. Piscataway:IEEE Press, 2018: 1067-10676. |
| [134] | CAESAR H , BANKITI V , LANG A H ,et al. nuScenes:a multimodal dataset for autonomous driving[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 11618-11628. |
| [135] | SUN P , KRETZSCHMAR H , DOTIWALLA X ,et al. Scalability in perception for autonomous driving:waymo open dataset[C]// Proceedings of 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 2443-2451. |
| [136] | PATIL A , MALLA S , GANG H M ,et al. The H3D dataset for full-surround 3D multi-object detection and tracking in crowded urban scenes[C]// Proceedings of 2019 International Conference on Robotics and Automation. Piscataway:IEEE Press, 2019: 9552-9557. |
| [137] | GEYER J A2D2:AEV autonomous driving dataset[Z]. 2019. |
| [138] | RAHMAN M M , TAN Y H , XUE J ,et al. Notice of violation of IEEE publication principles:recent advances in 3D object detection in the era of deep neural networks:a survey[J]. IEEE Transactions on Image Processing, 2020,29: 2947-2962. |
| [139] | DENG J , DONG W , SOCHER R ,et al. ImageNet:a large-scale hierarchical image database[C]// Proceedings of 2009 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2009: 248-255. |
| [140] | LIU Y C , FAN B , XIANG S M ,et al. Relation-shape convolutional neural network for point cloud analysis[C]// Proceedings of 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2020: 8887-8896. |
| [141] | CASEY A D , SON S F , BILIONIS I ,et al. Prediction of energetic material properties from electronic structure using 3D convolutional neural networks[J]. Journal of Chemical Information and Modeling, 2020,60(10): 4457-4473. |
| [142] | CASAS S , LUO W , URTASUN R . IntentNet:learning to predict intention from raw sensor data[J]. arXiv preprint, 2021,arXiv:2101.07907. |
| [143] | SUN Y X , ZUO W X , LIU M . RTFNet:RGB-thermal fusion network for semantic segmentation of urban scenes[J]. IEEE Robotics and Automation Letters, 2019,4(3): 2576-2583. |
| [144] | CHEN X , SHI S , ZHU B ,et al. MPPNet:multi-frame feature intertwining with proxy points for 3D temporal object detection[J]. arXiv preprint, 2022,arXiv:2205.05979. |
| [145] | XU J Y , MIAO Z W , ZHANG D ,et al. INT:towards infiniteframes 3D detection with an efficient framework[J]. arXiv preprint, 2022,arXiv:2209.15215. |
| [1] | 卢经纬, 程相, 王飞跃. 求解微分方程的人工智能与深度学习方法:现状及展望[J]. 智能科学与技术学报, 2022, 4(4): 461-476. |
| [2] | 张俊, 许沛东, 陈思远, 高天露, 戴宇欣, 张科, 赵杭, 高杰迈, 白昱阳, 李金星, 张浩然, 李湘, 陈玖香. 物理-数据-知识混合驱动的人机混合增强智能系统管控方法[J]. 智能科学与技术学报, 2022, 4(4): 571-583. |
| [3] | 陈妍, 罗雪琴, 梁伟, 谢永芳. 基于情感信息融合注意力机制的抑郁症识别[J]. 智能科学与技术学报, 2022, 4(4): 600-609. |
| [4] | 栗仁武, 张凌霄, 高林, 李淳芃, 蒋浩. 基于点云的类级别物体姿态估计[J]. 智能科学与技术学报, 2022, 4(2): 246-254. |
| [5] | 李琳辉, 周彬, 任威威, 连静. 行人轨迹预测方法综述[J]. 智能科学与技术学报, 2021, 3(4): 399-411. |
| [6] | 李颖, 陈龙, 黄钊宏, 孙杨, 蔡国榕. 基于多尺度卷积神经网络特征融合的植株叶片检测技术[J]. 智能科学与技术学报, 2021, 3(3): 304-311. |
| [7] | 田庆, 胡蓉, 李佐勇, 蔡远征, 余兆钗. 基于SE-YOLOv5s的绝缘子检测[J]. 智能科学与技术学报, 2021, 3(3): 312-321. |
| [8] | 刘文, 胡琨林, 李岩, 刘钊. 移动目标轨迹预测方法研究综述[J]. 智能科学与技术学报, 2021, 3(2): 149-160. |
| [9] | 张阳, 胡月, 辛东嵘. 一种考虑时空关联的深度学习短时交通流预测方法[J]. 智能科学与技术学报, 2021, 3(2): 172-178. |
| [10] | 刘栋军, 王宇涵, 凌文芬, 彭勇, 孔万增. 基于脑机协同智能的情绪识别[J]. 智能科学与技术学报, 2021, 3(1): 65-75. |
| [11] | 赵亮, 谢志峰, 张坤鹏, 郑玉卿, 付园坤. 无线网络信号传输建模:一种区间二型模糊集成深度学习方法[J]. 智能科学与技术学报, 2020, 2(4): 401-411. |
| [12] | 田思佳,顾强,胡蓉,李锐戈,何顶新. 一种基于深度学习的机械臂分拣方法[J]. 智能科学与技术学报, 2020, 2(3): 268-274. |
| [13] | 王飞跃,曹东璞,魏庆来. 强化学习:迈向知行合一的智能机制与算法[J]. 智能科学与技术学报, 2020, 2(2): 101-106. |
| [14] | 袁小锋,王雅琳,阳春华,桂卫华. 深度学习在流程工业过程数据建模中的应用[J]. 智能科学与技术学报, 2020, 2(2): 107-115. |
| [15] | 刘凯, 李浥东, 林伟鹏. 车辆再识别技术综述[J]. 智能科学与技术学报, 2020, 2(1): 10-25. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
|
||